
1. 톰캣 만들기 미션 3,4단계에 대한 리뷰를 반영하여 제출했다.
https://github.com/woowacourse/jwp-dashboard-http/pull/428
[톰캣 구현하기 - 3, 4단계] 오잉(이하늘) 미션 제출합니다. by hanueleee · Pull Request #428 · woowacourse/jw
안녕하세요 하디 🕺 이번 미션 3,4단계 완료했습니다! 3단계(리팩토링)를 진행하다보니 수정사항이 꽤 많이 생겼습니다 ㅎㅎ.. Servlet 기존 Servlet의 handle메소드는 Request를 파라미터로 받아 적절한
github.com
2. DB에 제약조건 걸기
DB에 제약조건을 걸기 위한 쿼리를 작성했다!
내일 우리팀 백엔드 팀원 다같이 확인하고 운영&개발 DB에 적용할 예정~
📍 테이블 구조 조회
1) SHOW CREATE TABLE
- SHOW CREATE TABLE [테이블명]
- 최초 테이블 생성시 사용자가 실행한 내용 그대로 보여주는 건 X.
MySQL 서버가 테이블의 메타 정보를 읽어 이를 CREATE TABLE명령으로 재작성해서 보여주는 것 - 칼럼의 목록과 인덱스, 외래키 정보를 확인할 수 있다.
2) DESC
- DESC [테이블명]
- 테이블의 칼럼 정보를 보기 편한 표 형태로 표시.
- 인덱스 칼럼의 순서나 외래키, 테이블 자체의 속성을 보여주지는 않는다.
📍 JPA의 DDL 생성 기능

한마디로~ 필드에 @Column(어쩌고저쩌고... 달아줘도 실제로 뭐가 되지는 않는다. 그저 DDL생성에 영향 줄 뿐.
📍 컬럼의 제약조건 수정하기
ALTER TABLE [테이블명] MODIFY [컬럼명] VARCHAR(30) NOT NULL;
참고) VARCHAR뒤의 숫자는 Byte수가 아니가 그냥 글자수에 대한 내용이라고 한다.
3. [MySQL 아키텍처] 관련 테코톡을 싹 봤다.
2개밖에 없긴 했다 ㅎ
📍 MySQL 구조

1) MySQL 엔진
- 쿼리 파서
- 쿼리를 토큰으로 쪼개서 트리로 만든다.
- 쿼리 문장의 기본 문법 오류 체크
- 전처리기
- 파스 트리를 하나씩 검사하며 토큰이 유효한지 체크
- 옵티마이저
- 최적화한 쿼리 실행 계획 수립
- 최적화 방법
- 규칙 기반 최적화
- 비용 기반 최적화
- 쿼리 실행 엔진
- 옵티마이저가 만든 실행 계획대로 스토리지 엔진을 호출해서 레코드를 읽고 쓴다.
2) MySQL 스토리지 엔진
- 쿼리 실행 엔진이 요청한대로 디스크로 데이터를 저장하거나 읽어온다.
- 대표적 예시) InnoDB, MyISAM
📍 InnoDB 스토리지 엔진
1) PK에 의한 클러스터링
- 레코드를 PK순으로 정렬해서 저장
- PK 인덱스 자동 생성
- PK를 통해서만 레코드에 접근 가능
- PK를 통한 범위 검색 매우 빠름
- But, 클러스터링으로 인해 쓰기 성능 저하
2) 트랜잭션 지원 (MVCC, 리두로그&언두로그, 레코드 단위 잠금)
MVCC

- 버퍼풀 : 변경된 데이터를 디스크에 반영하기 전까지 잠시 보관하는 공간
- 언두로그 : 변경되기 이전 데이터를 백업해 두는 공간
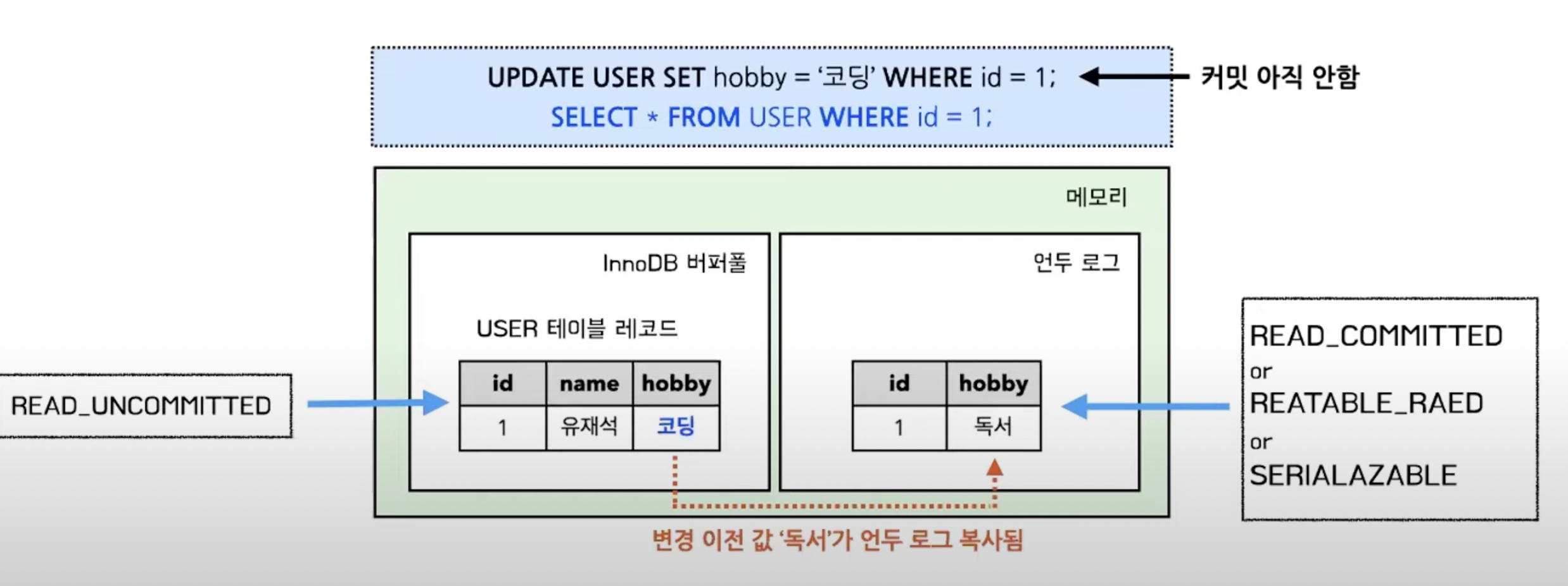
- MVCC : 트랜잭션 격리 레벨에 따라 조회되는 데이터가 달라지게 하는 기술
- Multi Version Concurrency Control (다양한 버전이 동시에 관리된다)
- 취미가 서로 다른 유재석 레코드 두개가 버퍼풀, 언두 로그에서 동시에 관리되고 있다!
- MVCC를 통해 레코드에 잠금을 걸지 않고도, 트랜잭션 격리 레벨에 따라 일관된 읽기를 할 수 있다.
언두로그 & 리두로그

레코드 단위 잠금
- DB에서 데이터를 변경할 때는 동시성 문제를 고려해 lock을 건다.
- InnoDB는 레코드 단위로 lock을 걸기 때문에 동시처리 성능 굿
- 근데 사실 레코드 자체를 잠그는게 아니라, 인덱스를 잠근다.
3) 버퍼풀
- 데이터 캐싱
- 인덱스 정보와 데이터 파일을 메모리에 캐싱
- 페이지 단위로 테이블 데이터 관리
- 쓰기 지연 버퍼
- 더티 페이지 : insert, update, delete 등으로 변경된 페이지
- 더티 페이지들을 모았다가 주기적으로 이벤트를 발생시켜서 한번에 디스크에 반영
4) 어댑티브 해시 인덱스
- 페이지에 빠르게 접근하기 위한 자료구조 기반 인덱스
- <인덱스 키, 페이지 주소 값>으로 구성
- 자주 요청되는 페이지에 대해 InnoDB가 자동으로 생성하는 인덱스

4. 유튜브에서 인덱스에 대한 짧은 강의를 봤다.
DB 조회 성능 개선의 핵심 = 디스크 I/O를 줄이는 것
- 인덱스 거는 법
- CREATE INDEX : 중복 있을 수도
- CREATE UNIQUE INDEX : 중복 없음


- 테이블에 걸려있는 인덱스 파악하기

- B-tree 기반 인덱스 동작 방식 : 영상을 확인하자
binary search(이진 탐색)
multicolumn-index 의 경우 attribute순서 중요! (team_id, backnumber이면 team_id로 먼저 정렬 후 backnumber로 정렬)
- 쿼리가 어떤 인덱스를 쓰는지 확인하기

- covering index : 조회하려는 attribute를 index가 모두 cover 할 때 -> 조회 성능 더 빠름
