
1. 구구의 [웹 어플리케이션 발전 과정, 서블릿과 서블릿 컨테이너] 강의를 들었다.
서블릿 : 자바 웹 서버에서 실행되는 프로그램
자바 공식 표준 기술 -> 정해진대로 써야함

프레임워크 안 쓰고 서블릿으로만으로도 웹 서비스 만들 수 있긴하다.
하지만 서블릿에 강하게 경합 + HTTP&비즈니스 섞여있게됨


개발자들이 저 servlet에 맞춰서 구현을 해두면 톰캣등의 서블릿 컨테이너가 알아서 라이프 사이클 관리해줌
(서블릿 클래스 알아서 읽어와서 실행시켜줌)
(서블릿 컨테이너 살아있는 동안 서블릿 객체 계속 살아있고 요청들어오면 service 메소드 실행)
요청이 들어오면 request, response를 만들어두고
→ 하나 떠 있는 서블릿에 reqeust, response 넘겨줌
각 서블릿 객체는 하나만 존재. 근데 싱글톤은 아니다!
이유: 톰캣이 구조상 서블릿을 한번 실행할 뿐이지 생성자 호출하면 하나 더 생성할 수 있긴함. 그니까 싱글톤은 아님
서블릿은 앵간하면 불변이어야 한다.
구구는 그냥 상태를 안둠.

필터도 서블릿 표준에 정의되어있다. (서블릿 스펙)
서블릿 처리를 할 때 필터링이 필요한 경우 사용
2. 페이징 성능 개선 자료를 읽었다.
- 인덱스의 두번째 컬럼은 첫 번째 컬럼에 의존해서 정렬되어 있습니다.
- 여러 컬럼으로 인덱스를 잡는다면 카디널리티가 높은순에서 낮은순으로 (group_no, from_date, is_bonus) 구성하는게 더 성능이 뛰어납니다.
- 커버링 인덱스 : 쿼리를 충족시키는 데 필요한 모든 데이터를 갖고 있는 인덱스
- 쿼리에서 오래걸리는 페이징 작업까지는 커버링 인덱스로 빠르게 처리후, 마지막 필요한 컬럼들만 별도로 가져오는 형태로 사용
3. [펀잇] 카테고리별 상품 목록 정렬 조회 api를 개선하기 위해 고민했다.
product 테이블

<기존>


- 가격기준, 평점기준 정렬시 - findAllByCategory
- 리뷰수기준 정렬시 - findAllByCategoryOrderByReviewCountDesc
가격기준(or 평점기준) 정렬시


category 조회 1
product 조회 1
count product 1 (page)
리뷰수기준 정렬시

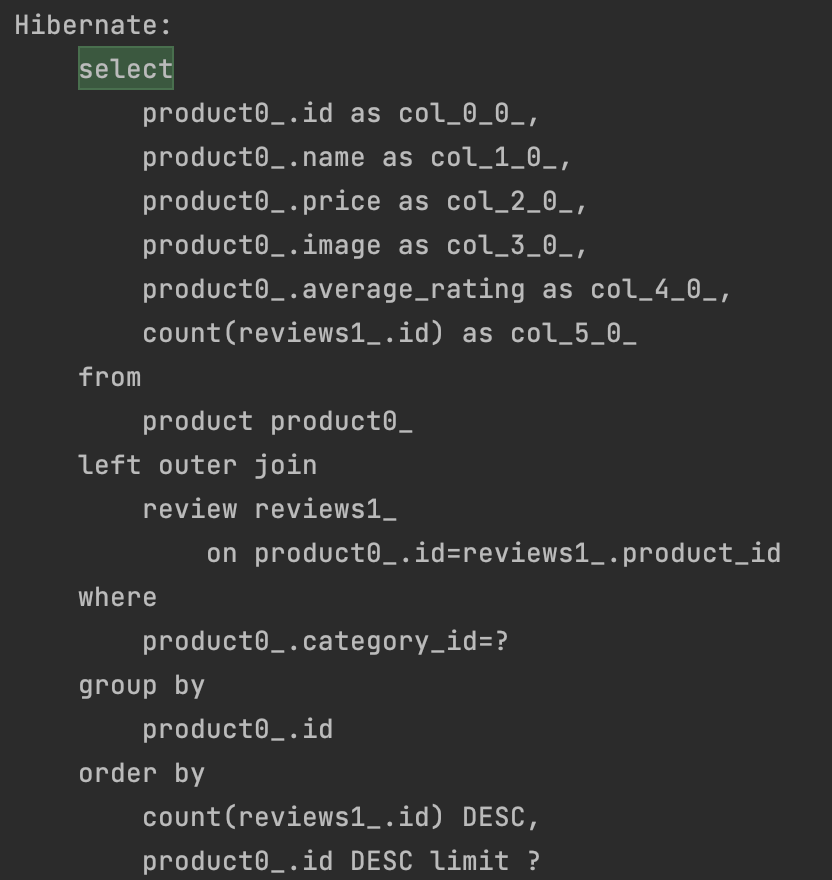
category 조회 1
product 조회 1
(근데 얘는 왜 product count 쿼리가 안 날라갈까?)
📍 고민1
Favoritecount
- 반정규화된 상태 (review, recipe가 column으로 가지고 있음)
- 사용자가 우다다 가능 (변동자주)
- 크기 한계가 있음 (사용자X리뷰)
ReviewCount
- 정규화된 상태 (product가 가지고 있지 않음)
- 사용자가 우다다 불가 (변동천천)
- 크기 한계 없음 (사용자X상품X??)
=> ReviewCount도 반정규화해야하는거 아닐까?
📍 고민2
paging 개선 방법 중에 no-offset을 적용하고 싶었는데,
우리팀 쿼리의 경우에는 정렬&페이징이 같이 들어가서 no-offset적용이 불가능하다..
(no-offset의 핵심은 where id > 30 뭐 이런식으로 앞의 데이터를 안 읽고 싹 넘겨버리는건데
쿼리 실행 순서가 where -> ... -> order by 여서, 앞에서 데이터를 id로 날려버리면 정렬이 이상해진다)
📍 현재까지의 결론
- 일단 우리팀의 경우에는 무한스크롤 방식이라 기존방식처럼 page 정보가 상세히 필요 없다.
그러므로 Page였던 반환값을 Slice로 바꾸자 (-> count query 안 날라감) - no-offset은 포기하고, 커버링 인덱스로 쫙 id뽑고 select 할까?
기타
톰캣 만들기 미션 패키지 구조
- nextstep : 응용 애플리케이션
- org.apache : 톰캣
- catalina :
- coyote :
감정회고
- 으으음~~ 성능 개선은 어렵구나!!
- 근데 인덱스에 대한 이해도가 점점 높아지고 있는 것 같아 뿌듯하다 ㅎㅎ
- 할 일이 왕 많다 🤪 학습 테스트랑 미션 언제하지!