
1. 토미의 [인프라 구조 개선하기 part1] 강의를 들었다.
최근에 대규모 시스템 설계 관련 책을 조금 봐서 그런지 이해도 잘되고 매우매우매우 재밌었다!!!
가용성, 성능, 규모 확장성 등등을 고려해 개선을 쭉쭉 해나간다고 무조건 좋은게 아니고,
다중화를 하기 때문에 고려해야하는 부분이 점점 늘어난다!
우테코는 ec2 인스턴스 4개로만 운영하기 때문에 인프라 아키텍처로 많은 시도를 해볼 수는 없다는게 아쉽다 ㅠㅠ
2. [인덱스] 테코톡 싹 봤다.
- 인덱스 : DB의 검색속도를 향상시키기 위해
- full table scan <-> range scan
- b-tree
clustering index : 인덱스에 실제 데이터

- 실제 데이터 자체가 정렬
- 테이블당 1개 존재 가능
- 리프 페이지가 데이터 페이지
- 생성방법
- PK
- NOT NULL + UNIQUE
non-clustering index
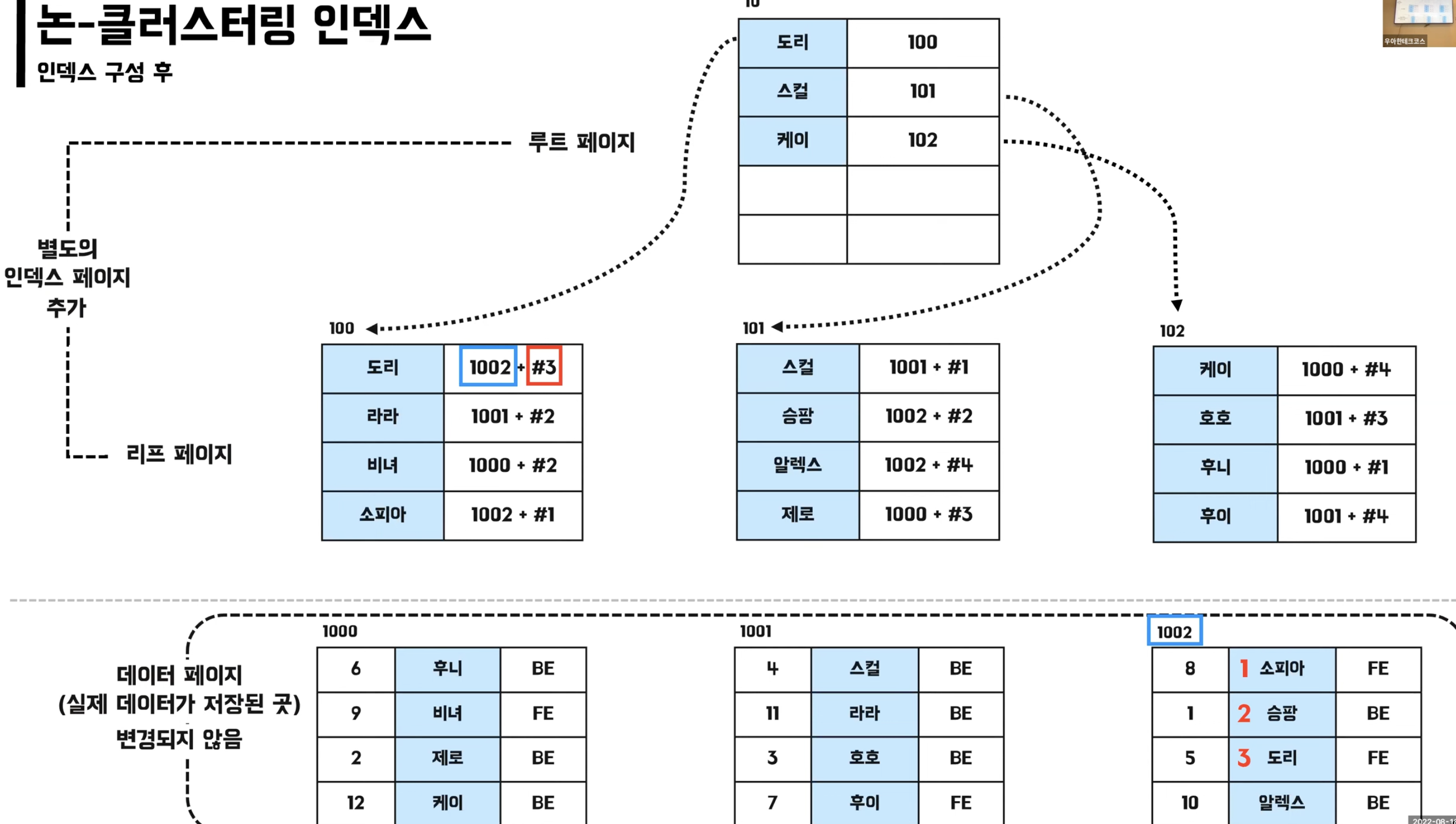
- 실제 데이터 페이지 그대로
- 별도의 인덱스 페이지 생성 -> 추가 공간 필요
- 테이블당 여러개 존재 가능
- 리프 페이지에 실제 데이터 페이지의 주소를 담고 있음
- 생성방법
- UNIQUE
- CREATE INDEX
- CREATE UNIQUE INDEX
clustering + non-clustering

인덱스 적용 기준
- 카디널리티 높은 컬럼
- WHERE, JOIN, ORDER BY, GROUP BY에 자주 사용되는 컬럼
- INSERT / UPDATE / DELETE가 자주 발생하지 않는 컬럼
- 규모가 작지 않은 테이블
3. 기타
1) 펀잇 코드의 @ManyToOne의 FetchType을 LAZY로 설정했다.
레시피 상세 조회 api 쿼리 개선하려고 코드 보다가
우리 팀 대부분의 @ManyToOne에서 fetchType설정이 안되어 있는 것을 발견했다!😱
default 설정이 EAGER인데 말이지..ㅋㅋ
그래서 팀원들한테 알리고 LAZY로 수정했다!
그 과정에서 테스트가 하나 깨져서 좀 문제가 있었는데 일단 해결했다.
2) 톰캣 미션 3단계를 진행하다가 Controller의
파라미터로 HttpResponse를 넘길지 vs 반환값으로 HttpResponse를 반환할지
고민이 생겼다!
그래서 루카&홍실과 대화를 나눴는데 매우 좋았다! 역시 우테코의 최고 장점은 주변에 함께 토론할 크루가 많다는 것 ><
httpresponse를 파라미터로 넘겼을 때
- 장
- 전후처리 (filter, interceptor ) 가능
- 불변애초에 불가
- 사용자가 편함
- 단
- 클린코드 아님 (파라미터가 계속 바뀜)
httpresponse를 반환값으로 했을 때
- 장
- controller의 로직 결과로 response가 만들어지는 것이므로 좀 타당하다
- (전후 처리가 없다면) response 불변
- 단
- 사용자가 이 컨트롤러를 사용할 때 과연 response를 제대로 만들 수 있을까? (사용자가 불편하다)
감정회고
- 갑작스레 먹은 참치가 맛있었다.
- 루카는 참 멋있는 사람이다. 나도 루카처럼 멋진 어른이 되고 싶다!