
1. [가상 면접 사례로 배우는 대규모 시스템 설계 기초]의 [1장. 사용자 수에 따른 규모 확장성]을 읽었다.
이 책 진짜진짜 재밌다!! 너무 재밌고 어렵지도 않아서 술술 읽히고 즐겁다 ㅎㅎㅎ
📍 어떤 데이터베이스를 사용할 것인가
- 관계형 데이터베이스 (RDBMS) .. join
- 아무래도 보통 얘를 쓴다
- 비 관계형 데이터베이스 (NoSQL)
- NoSQL이 바람직한 상황
- 아주 낮은 응답 지연시간(latency) 요구될 때
- 다루는 데이터가 비정형(unstructured)라 관계형 데이터가 아닐 때
- 데이터(JSON, YML, XML 등)를 직렬화하거나 역직렬화 할 수 있기만 하면 될 때
- 아주 많은 양의 데이터를 저장해야할 때
- NoSQL이 바람직한 상황
📍 수직적 규모 확장 vs 수평적 규모 확장
- scale up (수직정 규모 확장) : 서버에 고사양 자원(더 좋은 cpu, 더 많은 ram 등)을 추가하는 행위
- 서버로 유입되는 트래픽 양 적을 때는 얘가 good
- 장점 : 단순
- 단점
- 한계 있다 (cpu, 메모리 무한대 증설 불가)
- 장애에 대한 자동복구(failover) 방안이나 다중화 방안 x -> 장애 발생시 완전 중단
- scale out (수평적 규모 확장) : 더 많은 서버를 추가하여 성능을 개선하는 행위
- 대규모 애플리케이션 지원할 때는 얘가 good
📍 웹 서비스 다중화
1) 로드 밸런서
웹 서버가 하나일 때 웹 서버가 다운되면 사용자는 웹 사이트 접속 불가.
또한 너무 많은 사용자 접속해 웹 서버 한계 도달하면 응답 속도 느려지거나 접속 불가해질수도.
=> 로드밸런서 도입!
- 로드밸런서 : 부하 분산 집합 (load balancing set)에 속한 웹 서버들에게 트래픽 부하를 고르게 분산하는 역할
- 과정
- 사용자는 로드밸런서의 공개 ip로 접속
- 웹 서버 간 통신에는 사설 ip 사용
(사설 ip : 같은 네트워크에 속한 서버 사이의 통신에만 쓰일 수 있는 ip 주소. 인터넷으로는 접근 불가) - 로드밸런서는 이 사설 ip로 웹서버와 통신
- 로드밸런서에 웹 서버를 또 추가하면 no failover(장애 자동복구 실패) 해소. 웹 계층 가용성 향상
- 서버1 다운시 모든 트래픽 서버2로
- 유입 트래픽 폭증하면 로드 밸런서 있기 때문에 서버 그냥 서버 하나더 추가하면 된다.
2) 무상태(stateless) 웹 계층
웹 계층을 수평적으로 확장하기 위해서는 상태 정보(ex. 사용자 세션 데이터)를 웹 계층에서 제거해야한다.
-> 상태 정보를 NoSQL같은 지속성 저장소(공유 저장소)에 보관하고, 필요할 때 가져오도록 -> 상태 정보를 웹 서버로부터 물리적 분리
📍 데이터베이스 다중화
1) replication
- master-slave
- master
- 데이터 원본
- 쓰기 연산(insert, update, delete)은 여기서만 가능
- slave
- 데이터 사본
- 읽기 연산만 가능
- 대부분의 애플리케이션은 읽기 연산의 비중이 쓰기 연산보다 훨씬 높다. 그러므로 slave 수 > master 수
- 장점
- 더 나은 성능 : 쓰기 연산은 master에, 읽기 연산은 slave들에 -> 병렬 처리할 수 있는 query 수 증가
- 안정성 : 자연재해 등으로 db 일부 파괴되어도 데이터 보존 (다중화)
- 가용성 : 하나의 db서버에 장애 발생해도 다른 서버의 데이터 가져와 계속 서비스 가능
2) 샤딩
- 대규모 DB를 샤드(shard)라는 작은 단위로 분할
- 모든 샤드는 같은 스키마를 쓰지만 샤드에 보관되는 데이터 사이에는 중복이 없다
- 유의점 : 샤딩 키를 어떻게 정하느냐
- 샤딩 키 : 데이터가 어떻게 분산될지 정하는 하나 이상의 칼럼으로 구성된다.
- 샤딩 키를 통해 올바른 DB에 질의를 보내어 데이터 조회나 변경을 처리하므로 중요
- 샤딩 키를 정할 때는 데이터를 고르게 분할 할 수 있도록 하는것이 가장 중요
- 단점
- 데이터의 재샤딩
- 유명인사 문제 (핫스팟 키) : 특정 샤드에 질의 집중되어 서버 과부하
- 여러 샤드에 걸친 데이터 조인하기 힘들다
📍 캐시와 CDN을 통한 응답시간 개선
1) 캐시
- 캐시: 값비싼 연산 결과 또는 자주 참조되는 데이터를 메모리에 두고, 뒤이은 요청이 보다 빨리 처리될 수 있도록 하는 저장소
- 캐시 계층 : 데이터가 잠시 보관되는 곳. db보다 훨씬 빠르다
- 장점
- 성능 개선
- db 부하 줄임
- 캐시 계층 규모 독립적으로 확장시키기 가능
- 캐시 전략 중 하나인 읽기 주도형 캐시 전략 (read-through)
- 데이터가 캐시에 있으면 캐시에서 데이터를 읽어 웹 서버에 데이터 반환
- 데이터가 캐시에 없으면 db에서 해당 데이터를 읽어와 캐시에 적고 웹 서버에 데이터 반환
- 캐시 사용시 유의점
- 언제 써야하나? 캐시는 데이터 갱신은 자주 일어나지 않지만 참조는 빈번하게 일어날 때
- 어떤 데이터를 캐시? 캐시는 휘발성 메모리. 영속적으로 보관해야하는 데이터는 두면 안됨. 중요 데이터는 지속적 저장소에 둬야함.
- 캐시 속 데이터 언제 만료? 만료 정채 없으면 계속 남아 있다 (만료 기한 너무 짧아도 길어도 안됨)
- 일관성 어떻게 유지? 일관성은 데이터 저장소의 원본과 캐시 내의 사본이 같은지 여부. 저장소의 원본을 갱신하는 연산과 캐시를 갱신하는 연산은 단일 트랜잭션으로 처리되어야 한다.
- 장애에 어떻게 대처? 캐시 서버 한대만 두면 SPOF될 가능성있다. 여러 지역에 캐시 서버 분산해야함.
- 캐시 메모리 얼마나 크게? 너무 작으면 데이터가 자주 캐시에서 밀려나서(eviction) 캐시 성능 떨어짐. 캐시 메모리 과할당해라.
- 데이터 방출(eviction) 정책 뭘로? 캐시 꽉 차면 새로운 데이터 넣기 위해 기존 데이터 내보내야함. LRU(Least Recently Used), LFU(Least Frequently Used), FIFO(First In First Out) 등.
2) CDN (Content Delivery Network)
- CDN : 정적 콘텐츠를 전송하는 데에 쓰이는 지리적으로 분산된 서버의 네트워크
- 이미지, 비디오, CSS, JavaScript 파일 등 캐시 가능
- 동작 과정
- 사용자가 웹사이트에 방문
- 그 사용자에게 가장 가까운 CDN서버가 정적 콘텐츠 전달 (당연히 사용자가 CDN서버로부터 멀면 멀수록 느림)
- CDN서버의 캐시에 해당 이미지 없으면 origin서버에 요청해 파일 가져와 CDN에 저장한 후 파일 반환
- CDN 사용시 유의점
- 비용 : CDN으로 들어가고 나가는 데이터 전송 양에 따라 요금 냄 -> 자주 사용하지 않는 콘텐츠는 빼라
- 적절한 만료 시한 설정 : 시의성이 중요한(time-sensitive) 콘텐츠 경우 만료 시점 잘 정해야. 너무 길지도 짧지도 않게.
- CDN 장애에 대한 대처 방안 : CDN 자체가 죽었을 경우 웹사이트가 어떻게 동작해야하는지 고려해야함. 만약 일시적으로 응답 없으면, 해당 문제 감지하여 원본 서버로부터 직접 콘텐츠를 가져오도록 클라이언트를 구성하는게 필요할수도
- 콘텐츠 무효화(invalidation) 방법
📍 데이터 센터
- 지리적라우팅(geoDNS-routing, geo-routing) : 장애가 없는 상황에서 사용자는 가장 가까운 데이터 센터로 안내된다.
- geoDNS : 사용자의 위치에 따라 도메인 이름을 어떤 IP주소로 변환할지 결정할 수 있도록 해주는 DNS 서비스
📍 메시지 큐
시스템을 더 큰 규모로 확장하기 위해서는 시스템의 컴포넌트를 분리하여, 각자 독립적으로 확장될 수 있도록 해야한다.
이를 위해 메시지 큐를 사용할 수 있다.
- 메시지 큐 (https://tecoble.techcourse.co.kr/post/2021-09-19-message-queue/)
- 프로세스 또는 프로그램 간에 데이터를 교환할 때 사용하는 통신 방법 중에 하나
- 메시지 지향 미들웨어(비동기 메시지를 사용하는 응용 프로그램들 사이에서 데이터를 송수신하는 것)
- 즉, 메시지를 저장하는 임시 버퍼이며 비동기적으로 전송 (메시지를 전송 및 수신하기 위해 중간에 메시지 큐를 두는 것)
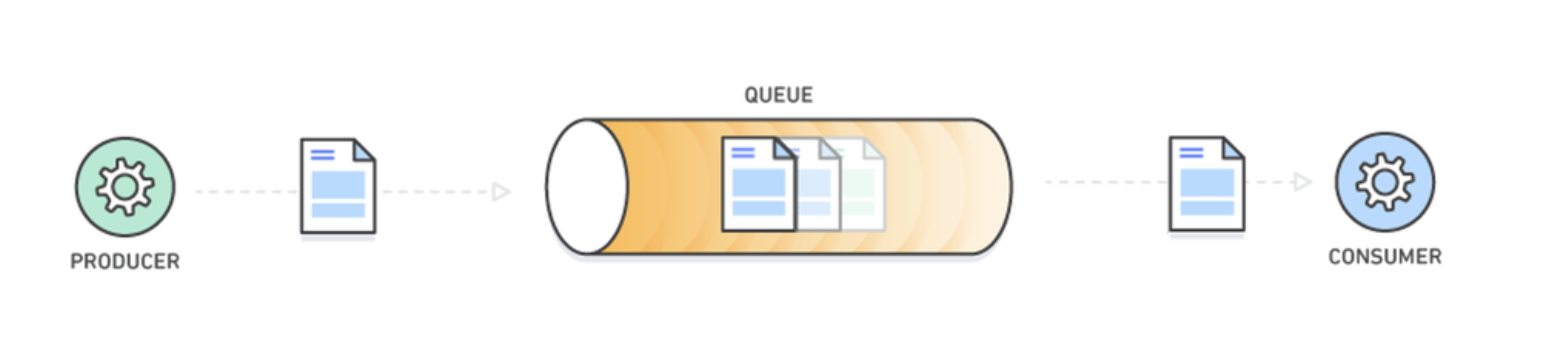
- 메시지의 무손실 보장 (메시지 큐에 일단 보관된 데이터는 소비자가 꺼낼 때까지 안전히 보관된다)
- 메시지 큐를 이용하면 서비스 또는 서버 간 결합이 느슨해져서, 규모 확장성이 보장되어야 하는 안정적 애플리케이션 구성에 좋다.
- 생산자는 소비자가 죽어있어도 메시지를 발행할 수 있고, 소비자는 생산자 서비가 죽어있어도 메시지를 수신할 수 있다.
📍 정리
시스템 규모 확장을 위해 살펴본 기법들
- 웹 계층은 무상태 계층으로
- 모든 계층에 다중화 도입
- 가능한 한 많은 데이터를 캐시
- 여러 데이터 센터를 지원
- 정적 콘텐츠는 CDN을 통해 서비스
- 데이터 계층은 샤딩을 통해 규모 확장
- 각 계층은 독립적 서비스로 분할
- 시스템을 지속적으로 모니터링하고 자동화 도구들 활용
2. 영한님의 JPA 활용2편의 [섹션 2 : API 개발 고급 - 준비] 강의를 들었다.
📍 데이터 세팅
본격적인 강의 전에 @PostConstruct를 활용해 데이터를 미리 세팅해두는 작업.
얼마전 강의에서 본 내용이 나와서 반가웠다!
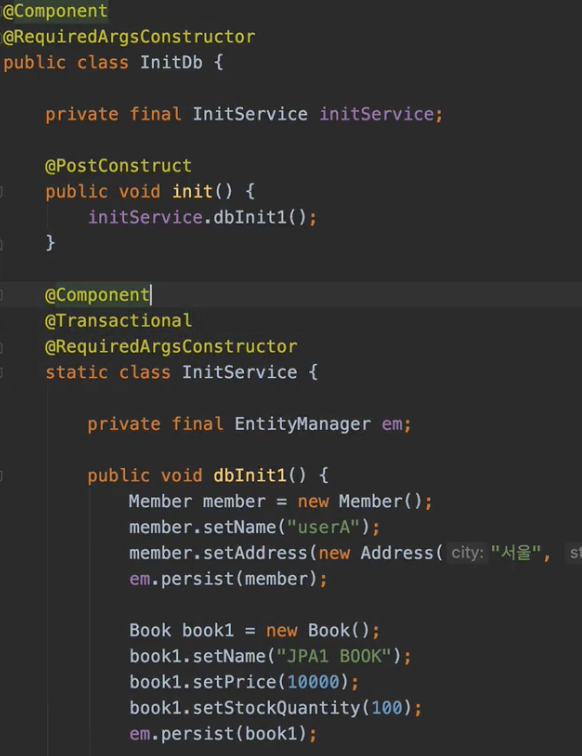
생성자 호출 -> 의존성 주입 -> @PostConstruct
@PostConstruct와 @Transactional을 같이사용하면 트랜잭션이 적용되지 않는다~ (초기화 코드 호출 이후 트랜잭션 AOP가 적용되기 때문)
📍 영속성 전이, 고아 객체
아 그리고 오랜만에 봐서 그런가 JPA의 cascade, orphan removal 쪽이 또 가물가물하길래..^^
예전에 정리해 둔 내용을 다시 봤다. 흑흑 왜 자꾸 까먹을까..
cascade
- 특정 엔티티를 영속 상태로 만들 때 연관된 엔티티도 함께 영속 상태로 만들고 싶은 경우 사용
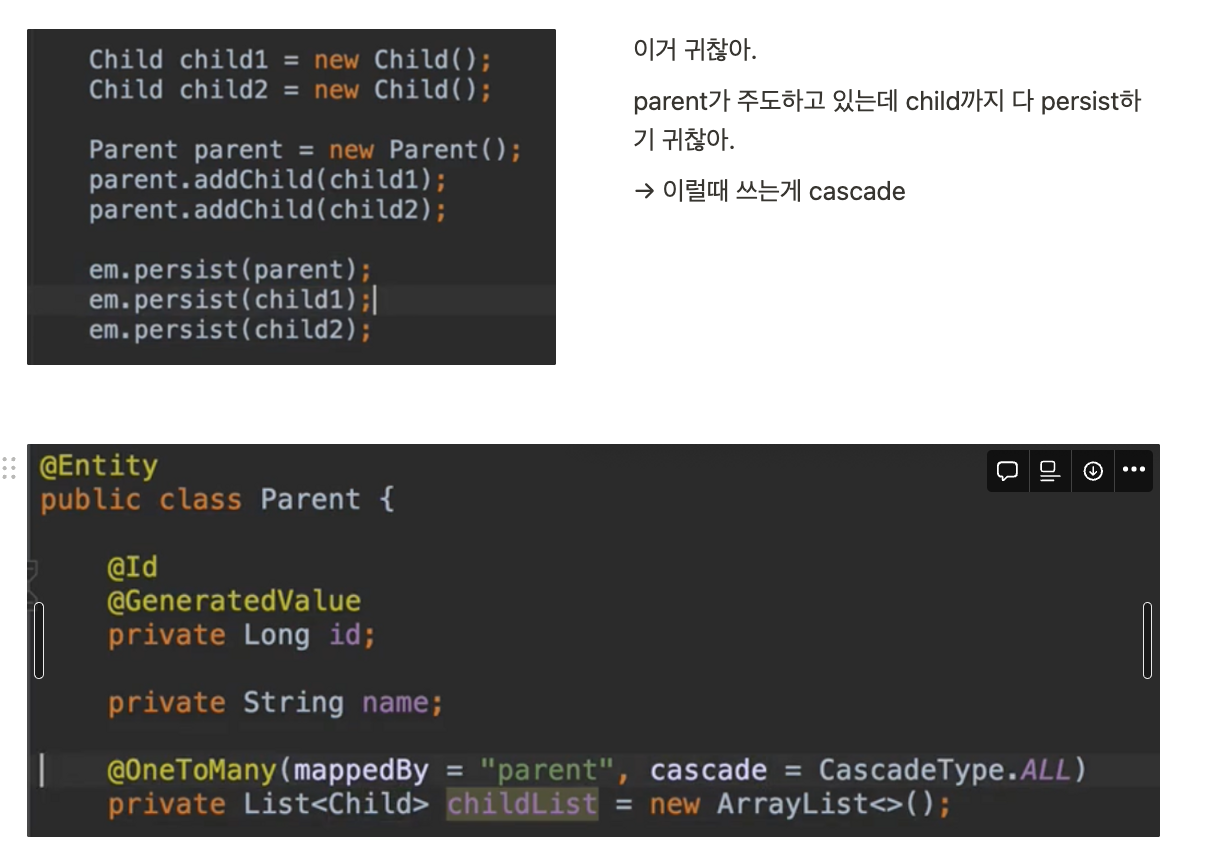
- 이런식으로 cascade 옵션 달아주면 em.persist(parent) 한방으로 parent와 child들을 전부 저장할 수 있다.
- 주의) 영속성 전이는 연관관계 매핑과 아무 관련 없다.
그저 엔티티를 영속화할 때 연관된 엔티티도 함께 영속화하는 편리함을 제공할 뿐! - 언제 사용? 하나의 부모가 자식을 관리할 때 (ex. 게시판-첨부파일)
- 첨부파일은 한 게시판에서만 관리 : cascade 굿
- 그 파일을 여러군데에서 관리 (또는 다른 entity에서도 관리) : 쓰면안됨
- => 소유주가 하나일 때! 단일 entity에 완전히 종속될 때! 라이프사이클이 똑같을 때!
orphan removal
- orphanRemoval = true : 부모 엔티티와 연관관계 끊어진 자식 엔티티 자동 삭제
- parent.getChildren().remove(0) -> 자동으로 delete from child where ~ 쿼리 나감
- 언제 사용?
- 참조하는 곳이 하나일 때! 특정 엔티티가 개인 소유할 때!
- @onetoone, @onetomany만 가능
- 참고) 고아 객체 제거 기능 활성화 시, 부모 제거하면 자식도 함께 제거 (마치 cascadetype.REMOVE처럼)
영속성 전이 + 고아 객체 , 생명주기
- 스스로 생명주기를 관리하는 엔티티는 em.persist로 영속화, em.remove로 제거 → em을 통해서 생명주기 관리
- cascade, orphanremoval 다 키면 -> 부모 엔티티를 통해 자식 엔티티의 생명주기 관리
3. 영한님의 JPA 활용2편의 [섹션 3 : API 개발 고급 - 지연 로딩과 조회 성능 최적화] 강의를 들었다.
@ManyToOne, @OneToOne에서의 성능 최적화
강의에 사용되는 예제는 다음과 같다. 이중 Member와 Delivery를 포함한 Order 조회!
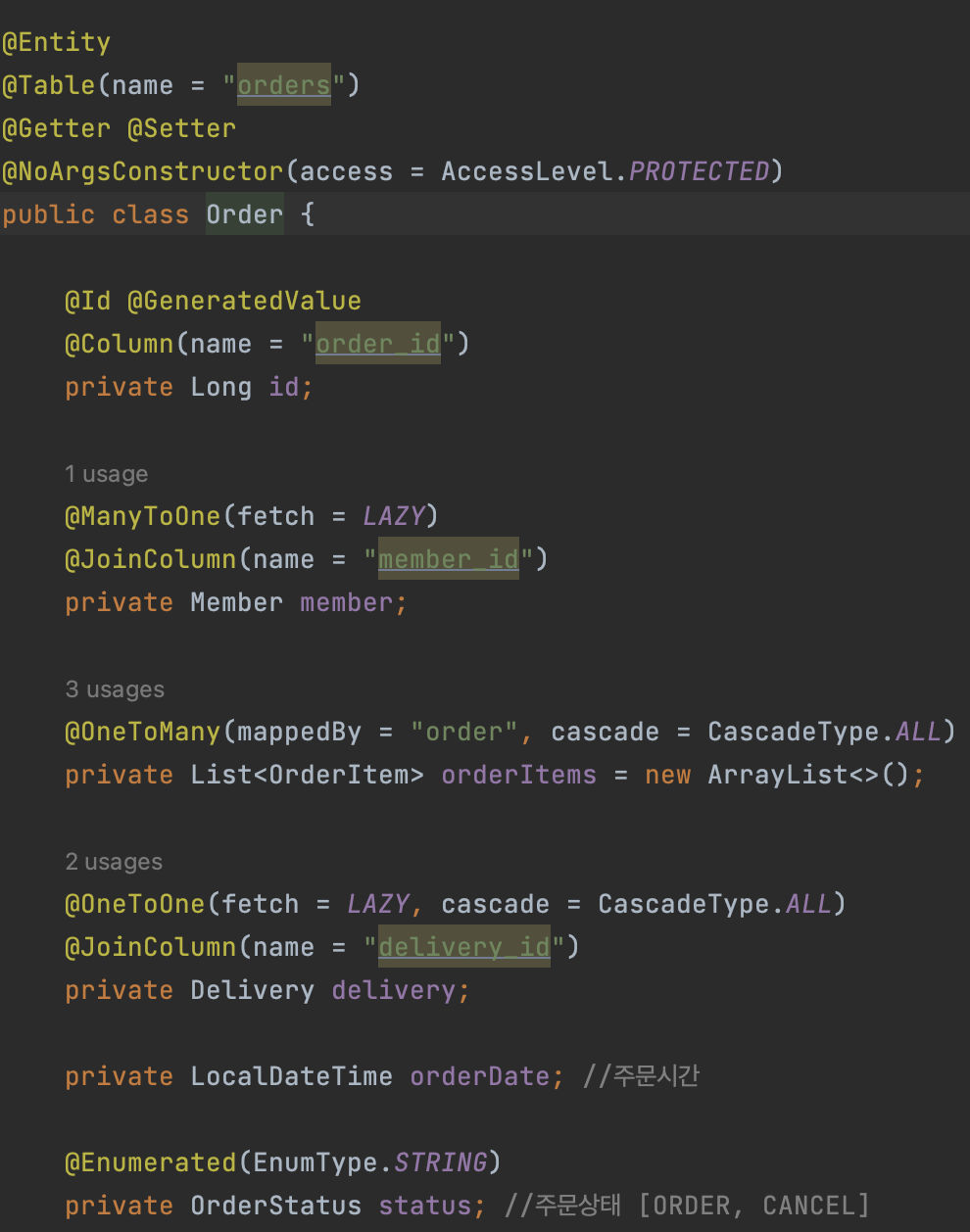
📍 v1. 엔티티 직접 노출
- 양방향 매핑 때문에 무한 루프 돌아서 jackson이 당황
- 지연로딩 설정해둬서 프록시라 jackson이 당황
그냥 말도 안됨.
📍 v2. 엔티티를 DTO로 변환
lazyloading으로 인해 db쿼리가 너무 많이 나감
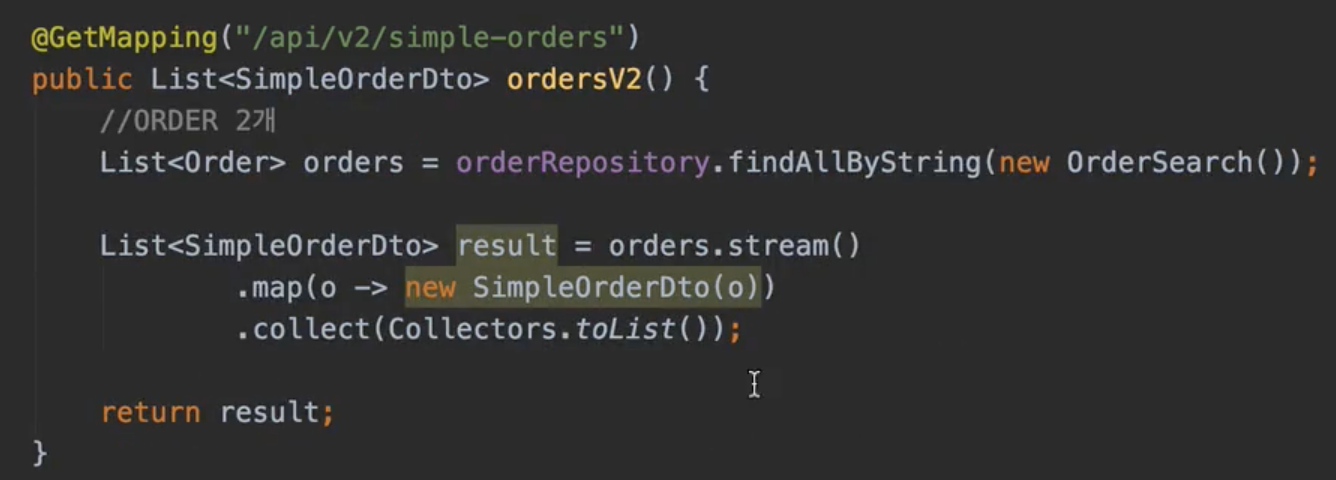
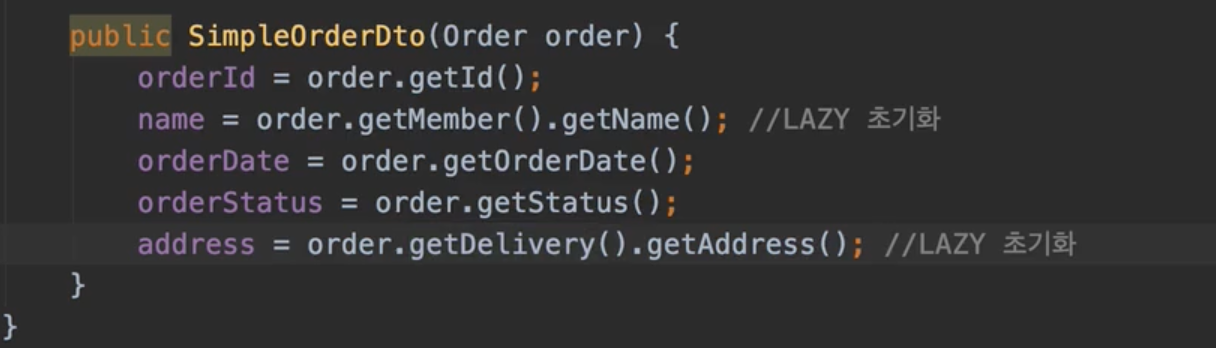
쿼리가 총 1 + N + N번 실행된다.
- order 조회 1번(order 조회 결과 수가 N이 된다.)
- order -> member 지연 로딩 조회 N 번
- order -> delivery 지연 로딩 조회 N 번
=> 소위 N+1 문제 (첫번째 쿼리의 결과인 N만큼 쿼리 추가 실행)
cf) 지연 로딩은 영속성 컨텍스트에 있으면 영속성 컨텍스트에 있는 엔티티를 사용하고 없으면 SQL을 실행한다.
따라서 같은 영속성 컨텍스트에서 이미 로딩한 member 엔티티를 추가로 조회하면 SQL을 실행하지 않는다. (ex. 한 member가 여러번 order)
📍 v3. 엔티티를 DTO로 변환 + fetch join 최적화
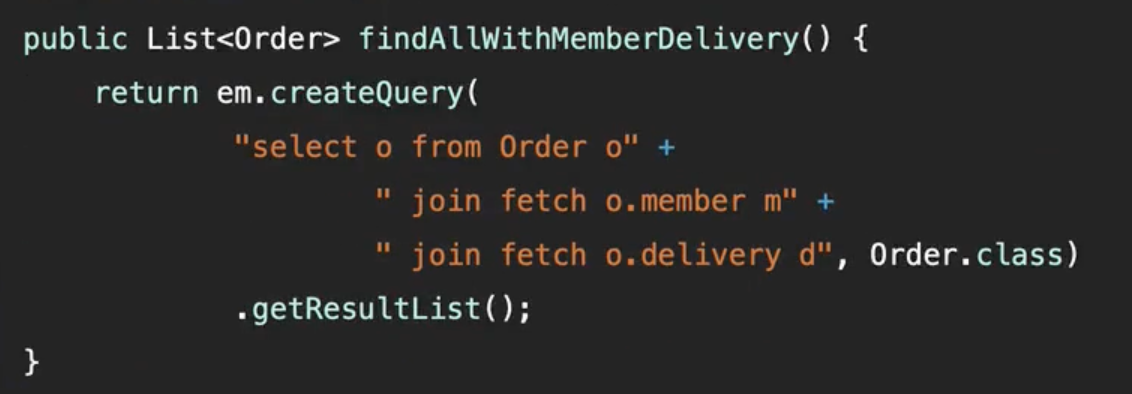
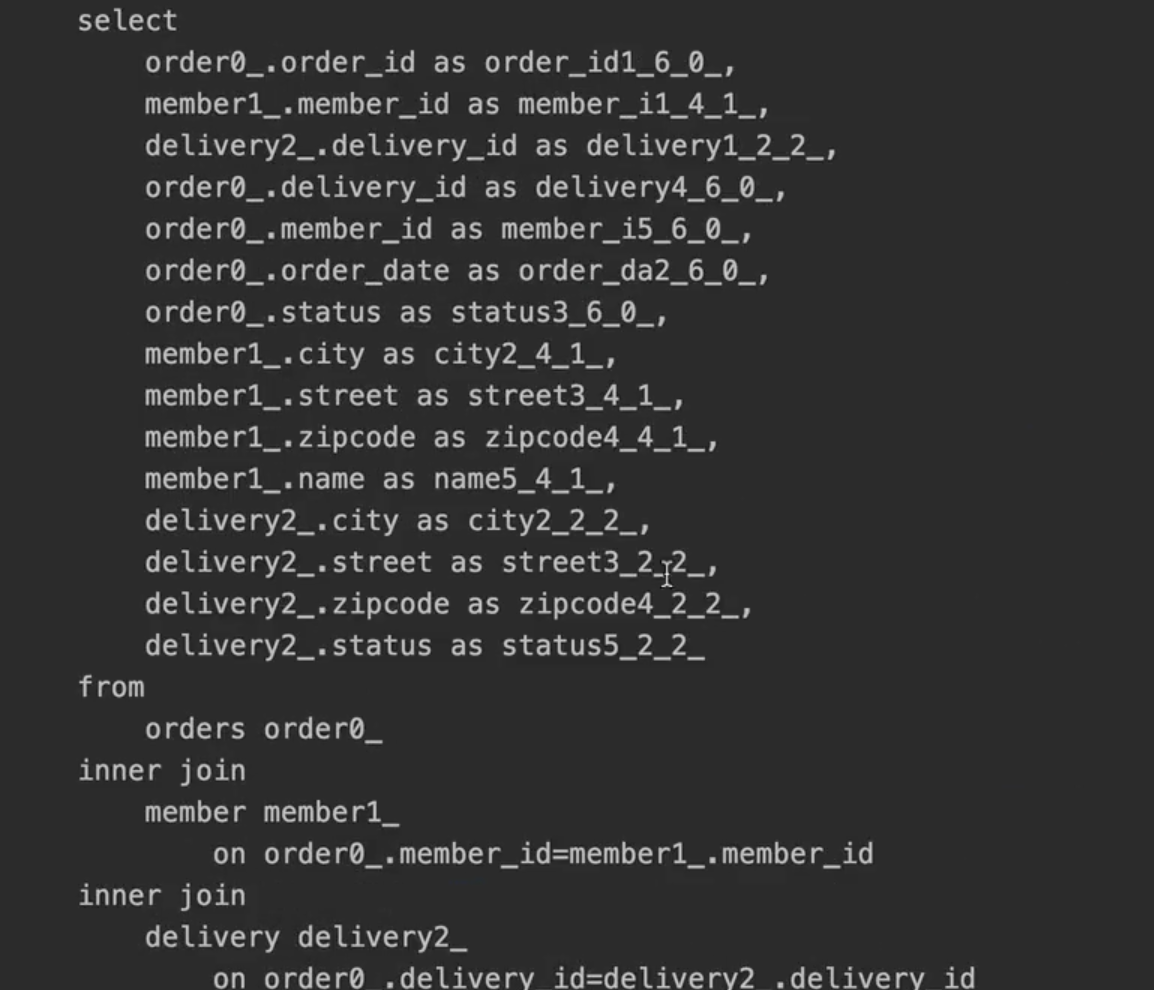
fetch join, n+1 이쪽은 여전히 좀 아리송해서 강의를 계기로 정리해봤다!
- N+1 문제와 FetchType
- EAGER : JPQL에서 N+1문제 발생
- jpql은 “select m from Member m”을 그대로 sql로 변환 → member만 select → member만 가지고와서 봤더니 어라 즉시 로딩이네 → member 10개면 team select 10개 나감 → n+1문제
- em.find면 jpa가 join해줘서 쿼리 1번
- LAZY : 나중에 comments 필요할 때 호출하기 때문에 N+1문제 발생 (그래도 comments 필요없으면 쿼리 1개, 필요하면 1+N 날리는거기 때문에 LAZY 선호) -> jpql의 fetch join으로 해결
- EAGER : JPQL에서 N+1문제 발생
- join vs fetch join (https://cobbybb.tistory.com/18)
- join : SELECT 대상만 조회하여 영속화 (JOIN 대상에 대한 영속성 관여x)
- ex. post만 조회한다면 comments는 조회되지 않아 접근 불가
- 조회의 주체가 되는 Entity만 SELECT 해서 영속화하기 때문에 데이터는 필요하지 않지만 연관 Entity가 검색조건에는 필요한 경우에 주로 사용됨
- fetch join : SELECT 대상과 FETCH JOIN 대상 엔티티 함께 조회하여 영속화
- ex. post와 comments를 동시에 조회
- Fetch Join이 걸린 Entity 모두 영속화하기 때문에 FetchType이 Lazy인 Entity를 참조하더라도
이미 영속성 컨텍스트에 들어있기 때문에 따로 쿼리가 실행되지 않은 채로 N+1문제가 해결됨
- join : SELECT 대상만 조회하여 영속화 (JOIN 대상에 대한 영속성 관여x)
- FetchType.EAGER vs fetch join https://mighty96.github.io/til/fetch_fetchjoin/
📍 v4. JPA에서 DTO로 바로 조회
일반적인 SQL을 사용할 때 처럼 원하는 값을 선택해서 조회 new 명령어를 사용해서 JPQL의 결과를 DTO로 즉시 변환
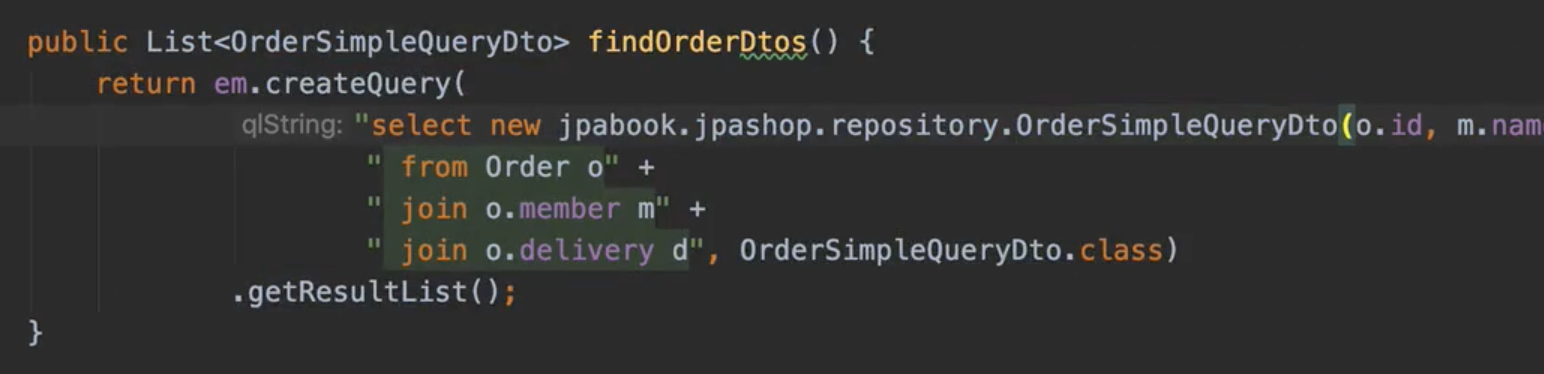
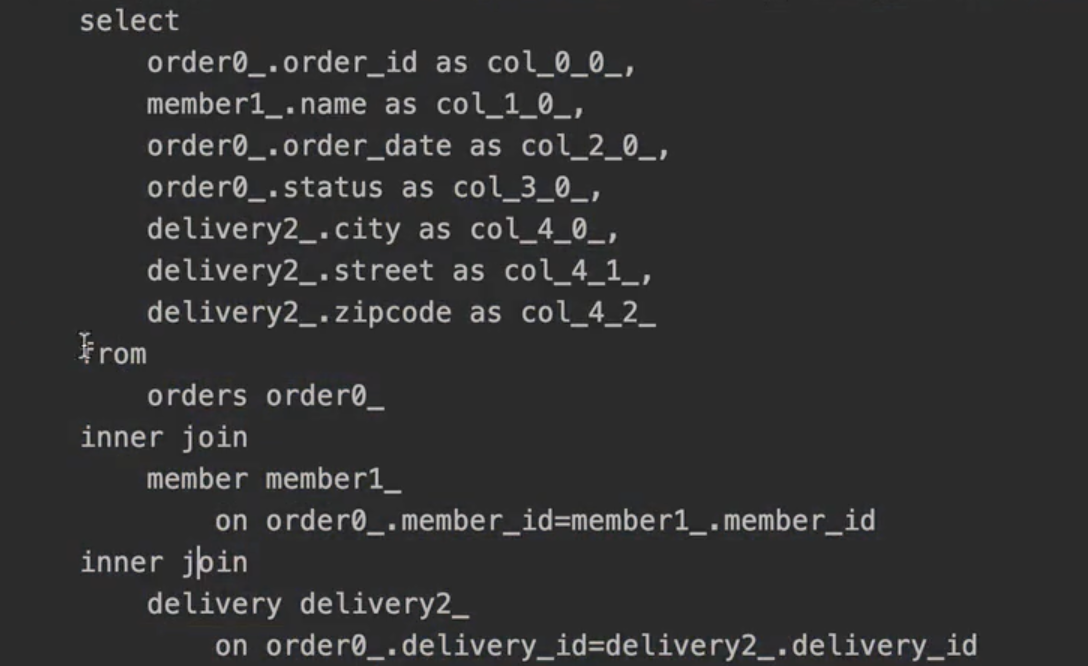
v3보다 select 절에 들어가는 데이터가 줄어들었다.
v3 : order를 가져오는데 내가 원하는거만 fetch join. order을 건드리지 않음. 재사용성 굿
v4 : 재사용성 별로. API 스펙에 맞춘 코드가 리포지토리에 들어감. 성능최적화에서는 조금 더 나음(근데 생각보다 미비). 코드상 지저분
이 방법 선택할 경우 영한님께서는 보통 순수한 엔티티를 반환하는 리포지토리와 dto를 반환하는 리포지토리 분리 하신다고 한다.
📍 정리
엔티티를 DTO로 변환하거나(v3), DTO로 바로 조회하는(v4) 두가지 방법은 각각 장단점이 있다.
둘중 상황에 따라 서 더 나은 방법을 선택하면 된다.
엔티티로 조회하면 리포지토리 재사용성도 좋고, 개발도 단순해진다. 따라
서 권장하는 방법은 다음과 같다.
쿼리 방식 선택 권장 순서
1. 우선 엔티티를 DTO로 변환하는 방법을 선택한다. (v2)
2. 필요하면 페치 조인으로 성능을 최적화 한다. 대부분의 성능 이슈가 해결된다. (v3)
3. 그래도 안되면 DTO로 직접 조회하는 방법을 사용한다. (v4)
4. 최후의 방법은 JPA가 제공하는 네이티브 SQL이나 스프링 JDBC Template을 사용해서 SQL을 직접 사용
4. 영한님의 JPA 활용2편의 [섹션 4 : API 개발 고급 - 컬렉션 조회 최적화] 강의를 40%정도 들었다.
@OneToMany에서의 성능 최적화 (컬렉션 조회)
db 입장에서 1:N 조회는 뻥튀기.
예를 들어 일이 1고, 다쪽이 3면 조인하면 3줄로 뻥튀기 (주문 하나에 주문내역 3개면 조인하면 3줄)
강의에 사용되는 예제는 다음과 같다. 앞 강의에 이어 이번엔 OrderItems(그리고 그 안의 Item)까지 같이 조회하려함!
📍 v1. 엔티티 직접 노출
별로다
📍 v2. 엔티티를 DTO로 변환
지연로딩으로 N+1문제 발생. 근데 퀄렉션이라 더 나감.
- order 1번 (결과 N)
- member , address N번(order 조회 수 만큼)
- orderItem N번(order 조회 수 만큼)
- item N번(orderItem 조회 수 만큼)
📍 v3. 엔티티를 DTO로 변환 + fetch join 최적화
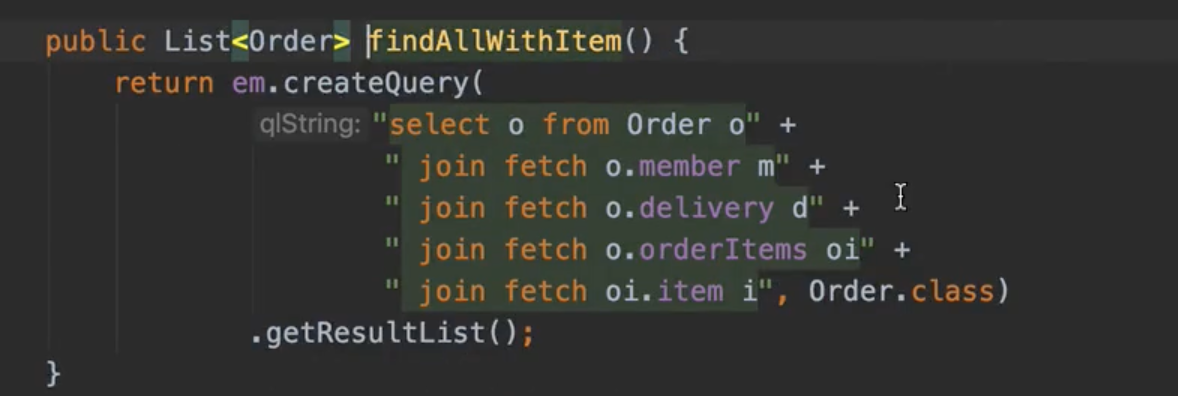
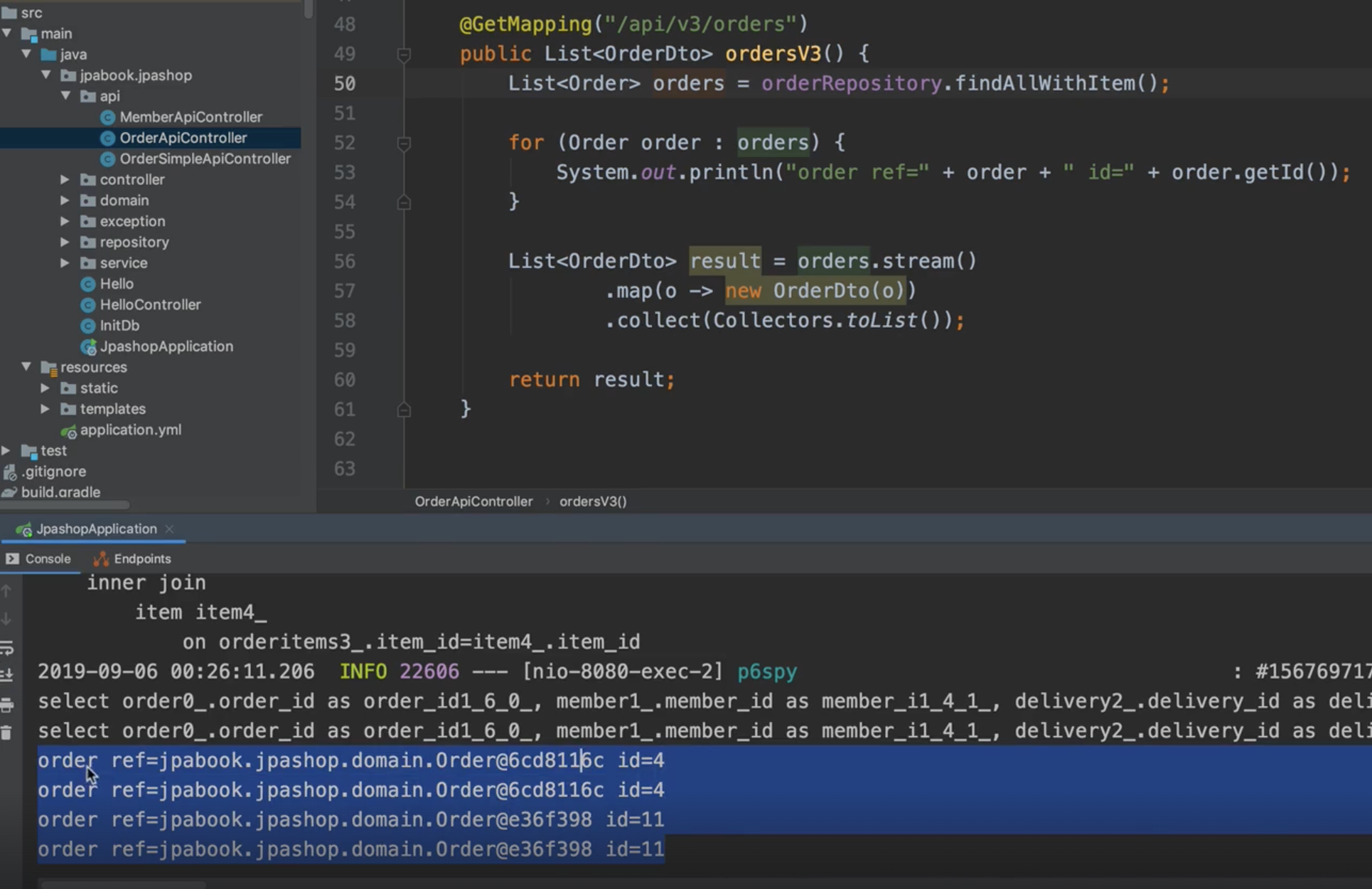
뻥튀기. order 2개인데 4개 나옴. 중복.
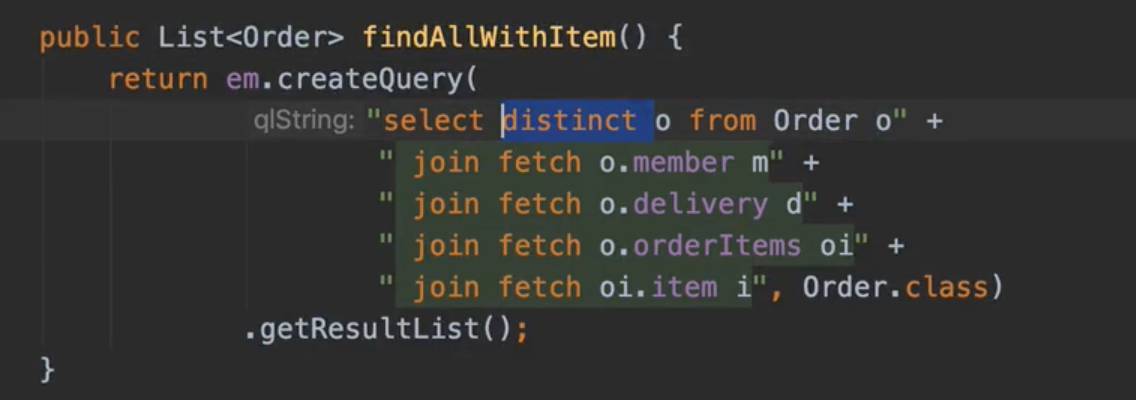
distinct 명령어 추가!
jpa에서 distinct 붙어있으면 order가 같은 id값 갖고있으면 중복 제거
근데 얘가 db단에서 작동하지는 않음 (db의 distinct 명령어는 모든 컬럼의 데이터가 같아야 똑같다고 인식)
distinct 를 사용한 이유는 1대다 조인이 있으므로 데이터베이스 row가 증가한다. 그 결과 같은 order 엔티티의 조회 수도 증가하게 된다. JPA의 distinct는 SQL에 distinct를 추가하고, 더해서 같은 엔티티가 조회되면, 애플리케이션에서 중복을 걸러준다. 이 예에서 order가 컬렉션 페치 조인 때문에 중복 조회 되는 것을 막아준다.
치명적 단점 : 페이징 불가능
1:N을 fetch join하는 순간 페이징 쿼리 아예 안나감!!!
컬렉션 페치 조인을 사용하면 페이징이 불가능하다. 하이버네이트는 경고 로그를 남기면서 모든 데이터를 DB에서 읽어오고, 메모리에서 페이징 해버린다(매우 위험하다). 자세한 내용은 자바 ORM 표준 JPA 프로그래밍의 페치 조인 부분을 참고하자.
1:N join하면 row가 뻥튀기되기 때문에 페이징 불가해짐 (order가 아니라 orderitem으로 페이징이 되어버림..)
=> 1:N fetch join에서는 페이징 하면 안된다. member나 delivery, item 괜찮. orderitem은 컬렉션이라 불가!
+) 컬렉션 fetch join은 1개만 가능!
컬렉션 페치 조인은 1개만 사용할 수 있다. 컬렉션 둘 이상에 페치 조인을 사용하면 안된다. 데이터가 부정합하게 조회될 수 있다. 자세한 내용은 자바 ORM 표준 JPA 프로그래밍을 참고하자.
5. 기타
- 직렬화 : 객체 또는 데이터를 바이트(byte) 형태로 변환하는 것
(객체에 저장된 데이터를 스트림에 쓰기write 위해 연속적인serial 데이터로 변환하는 것) - SPOF (Single Point of Failure) : 시스템 구성 요소 중에서, 동작하지 않으면 전체 시스템이 중단되는 요소
- 가용성 : 서버와 네트워크 또는 다양한 시스템의 정상적으로 사용 가능한 정도 (정상동작시간/전체사용시간)
- failover : 장애 대비 기능 (https://oriyong.tistory.com/80)
- 실패(fail)를 끝낸다(over)
- 시스템에 장애가 생기면 미리 준비해둔 다른 시스템으로 대체해서 운영
- 운영 되고 있는 시스템 : active
- 같은 세팅으로 구성된 대기 시스템 : passive
- 운영중에 active 시스템에 문제가 생기면 passive 시스템이 active 상태로 변경되면서 이어서 운영
- 서버 다중화 했을 때 세션의 문제점을 해결하는 방법 (https://smjeon.dev/web/sticky-session/)(https://cl8d.tistory.com/77)
- sticky session : 특정 세션의 요청을 처음 처리한 서버로만 전송
- session clustering : 세션들을 하나로 묶어 클러스터로 관리
- session server 분리 (session storage 구성)
- NoSQL
- 관계형 데이터베이스가 아닌 다양한 형태의 데이터 저장 및 관리를 위한 데이터베이스 기술을 일컫는 용어
- 관계형 데이터베이스와 비교하여 스키마의 유연성, 읽기/쓰기 성능, 확장성 등에서 강함
- 데이터 모델의 유연성과 확장성을 강조하며, 대용량 데이터 처리나 다양한 형태의 데이터 구조를 다루는 데 특히 적합
- 하지만 이에 따라 데이터 무결성이나 트랜잭션 처리와 같은 측면에서는 일부 제약이 있을 수 있음
- Redis
- NoSQL 데이터베이스 중 하나. key-value 스토어 유형
- 인메모리 데이터 저장소
- 주요 사용 사례 : 캐싱, 세션 관리, 실시간 분석, 메시지 큐 등
- 단일 서버 또는 클러스터 형태로 운영할 수 있다.
- DB는 데이터를 물리 디스크에 직접 쓰기 때문에 서버를 껐다 켜도 데이터가 사라지지 않음. 하지만 매번 디스크에 접근해야하기 때문에 사용자 많아질 수록 느려짐.
- 샤딩 vs 파티셔닝 (https://hudi.blog/db-partitioning-and-sharding/)
- 둘 다 데이터베이스 분할 방법!
- 파티셔닝 : 하나의 데이터베이스 안에서 하나의 테이블을 여러 테이블로 분리
- 매우 큰 테이블을 여러개의 테이블로 분할하는 작업
- 큰 데이터를 여러 테이블로 나눠 저장하기 때문에 쿼리 성능이 개선될 수 있다.
- 데이터는 물리적으로 여러 테이블로 분산하여 저장되지만, 사용자는 마치 하나의 테이블에 접근하는 것과 같이 사용할 수 있다
- 샤딩 : 동일한 스키마를 가지고 있는 여러대의 데이터베이스 서버들에 데이터를 작은 단위로 나누어 분산 저장하는 기법
- 물리적으로 서로 다른 컴퓨터에 데이터를 저장하므로, 쿼리 성능 향상과 더불어 부하가 분산되는 효과까지 얻을 수 있다.
- 즉, 샤딩은 데이터베이스 차원의 수평 확장(scale-out)인 셈
- 파티셔닝은 모든 데이터를 동일한 컴퓨터에 저장하지만, 샤딩은 데이터를 서로 다른 컴퓨터에 분산한다
1. [가상 면접 사례로 배우는 대규모 시스템 설계 기초]의 [1장. 사용자 수에 따른 규모 확장성]을 읽었다.
이 책 진짜진짜 재밌다!! 너무 재밌고 어렵지도 않아서 술술 읽히고 즐겁다 ㅎㅎㅎ
📍 어떤 데이터베이스를 사용할 것인가
- 관계형 데이터베이스 (RDBMS) .. join
- 아무래도 보통 얘를 쓴다
- 비 관계형 데이터베이스 (NoSQL)
- NoSQL이 바람직한 상황
- 아주 낮은 응답 지연시간(latency) 요구될 때
- 다루는 데이터가 비정형(unstructured)라 관계형 데이터가 아닐 때
- 데이터(JSON, YML, XML 등)를 직렬화하거나 역직렬화 할 수 있기만 하면 될 때
- 아주 많은 양의 데이터를 저장해야할 때
- NoSQL이 바람직한 상황
📍 수직적 규모 확장 vs 수평적 규모 확장
- scale up (수직정 규모 확장) : 서버에 고사양 자원(더 좋은 cpu, 더 많은 ram 등)을 추가하는 행위
- 서버로 유입되는 트래픽 양 적을 때는 얘가 good
- 장점 : 단순
- 단점
- 한계 있다 (cpu, 메모리 무한대 증설 불가)
- 장애에 대한 자동복구(failover) 방안이나 다중화 방안 x -> 장애 발생시 완전 중단
- scale out (수평적 규모 확장) : 더 많은 서버를 추가하여 성능을 개선하는 행위
- 대규모 애플리케이션 지원할 때는 얘가 good
📍 웹 서비스 다중화
1) 로드 밸런서
웹 서버가 하나일 때 웹 서버가 다운되면 사용자는 웹 사이트 접속 불가.
또한 너무 많은 사용자 접속해 웹 서버 한계 도달하면 응답 속도 느려지거나 접속 불가해질수도.
=> 로드밸런서 도입!
- 로드밸런서 : 부하 분산 집합 (load balancing set)에 속한 웹 서버들에게 트래픽 부하를 고르게 분산하는 역할
- 과정
- 사용자는 로드밸런서의 공개 ip로 접속
- 웹 서버 간 통신에는 사설 ip 사용
(사설 ip : 같은 네트워크에 속한 서버 사이의 통신에만 쓰일 수 있는 ip 주소. 인터넷으로는 접근 불가) - 로드밸런서는 이 사설 ip로 웹서버와 통신
- 로드밸런서에 웹 서버를 또 추가하면 no failover(장애 자동복구 실패) 해소. 웹 계층 가용성 향상
- 서버1 다운시 모든 트래픽 서버2로
- 유입 트래픽 폭증하면 로드 밸런서 있기 때문에 서버 그냥 서버 하나더 추가하면 된다.
2) 무상태(stateless) 웹 계층
웹 계층을 수평적으로 확장하기 위해서는 상태 정보(ex. 사용자 세션 데이터)를 웹 계층에서 제거해야한다.
-> 상태 정보를 NoSQL같은 지속성 저장소(공유 저장소)에 보관하고, 필요할 때 가져오도록 -> 상태 정보를 웹 서버로부터 물리적 분리
📍 데이터베이스 다중화
1) replication
- master-slave
- master
- 데이터 원본
- 쓰기 연산(insert, update, delete)은 여기서만 가능
- slave
- 데이터 사본
- 읽기 연산만 가능
- 대부분의 애플리케이션은 읽기 연산의 비중이 쓰기 연산보다 훨씬 높다. 그러므로 slave 수 > master 수
- 장점
- 더 나은 성능 : 쓰기 연산은 master에, 읽기 연산은 slave들에 -> 병렬 처리할 수 있는 query 수 증가
- 안정성 : 자연재해 등으로 db 일부 파괴되어도 데이터 보존 (다중화)
- 가용성 : 하나의 db서버에 장애 발생해도 다른 서버의 데이터 가져와 계속 서비스 가능
2) 샤딩
- 대규모 DB를 샤드(shard)라는 작은 단위로 분할
- 모든 샤드는 같은 스키마를 쓰지만 샤드에 보관되는 데이터 사이에는 중복이 없다
- 유의점 : 샤딩 키를 어떻게 정하느냐
- 샤딩 키 : 데이터가 어떻게 분산될지 정하는 하나 이상의 칼럼으로 구성된다.
- 샤딩 키를 통해 올바른 DB에 질의를 보내어 데이터 조회나 변경을 처리하므로 중요
- 샤딩 키를 정할 때는 데이터를 고르게 분할 할 수 있도록 하는것이 가장 중요
- 단점
- 데이터의 재샤딩
- 유명인사 문제 (핫스팟 키) : 특정 샤드에 질의 집중되어 서버 과부하
- 여러 샤드에 걸친 데이터 조인하기 힘들다
📍 캐시와 CDN을 통한 응답시간 개선
1) 캐시
- 캐시: 값비싼 연산 결과 또는 자주 참조되는 데이터를 메모리에 두고, 뒤이은 요청이 보다 빨리 처리될 수 있도록 하는 저장소
- 캐시 계층 : 데이터가 잠시 보관되는 곳. db보다 훨씬 빠르다
- 장점
- 성능 개선
- db 부하 줄임
- 캐시 계층 규모 독립적으로 확장시키기 가능
- 캐시 전략 중 하나인 읽기 주도형 캐시 전략 (read-through)
- 데이터가 캐시에 있으면 캐시에서 데이터를 읽어 웹 서버에 데이터 반환
- 데이터가 캐시에 없으면 db에서 해당 데이터를 읽어와 캐시에 적고 웹 서버에 데이터 반환
- 캐시 사용시 유의점
- 언제 써야하나? 캐시는 데이터 갱신은 자주 일어나지 않지만 참조는 빈번하게 일어날 때
- 어떤 데이터를 캐시? 캐시는 휘발성 메모리. 영속적으로 보관해야하는 데이터는 두면 안됨. 중요 데이터는 지속적 저장소에 둬야함.
- 캐시 속 데이터 언제 만료? 만료 정채 없으면 계속 남아 있다 (만료 기한 너무 짧아도 길어도 안됨)
- 일관성 어떻게 유지? 일관성은 데이터 저장소의 원본과 캐시 내의 사본이 같은지 여부. 저장소의 원본을 갱신하는 연산과 캐시를 갱신하는 연산은 단일 트랜잭션으로 처리되어야 한다.
- 장애에 어떻게 대처? 캐시 서버 한대만 두면 SPOF될 가능성있다. 여러 지역에 캐시 서버 분산해야함.
- 캐시 메모리 얼마나 크게? 너무 작으면 데이터가 자주 캐시에서 밀려나서(eviction) 캐시 성능 떨어짐. 캐시 메모리 과할당해라.
- 데이터 방출(eviction) 정책 뭘로? 캐시 꽉 차면 새로운 데이터 넣기 위해 기존 데이터 내보내야함. LRU(Least Recently Used), LFU(Least Frequently Used), FIFO(First In First Out) 등.
2) CDN (Content Delivery Network)
- CDN : 정적 콘텐츠를 전송하는 데에 쓰이는 지리적으로 분산된 서버의 네트워크
- 이미지, 비디오, CSS, JavaScript 파일 등 캐시 가능
- 동작 과정
- 사용자가 웹사이트에 방문
- 그 사용자에게 가장 가까운 CDN서버가 정적 콘텐츠 전달 (당연히 사용자가 CDN서버로부터 멀면 멀수록 느림)
- CDN서버의 캐시에 해당 이미지 없으면 origin서버에 요청해 파일 가져와 CDN에 저장한 후 파일 반환
- CDN 사용시 유의점
- 비용 : CDN으로 들어가고 나가는 데이터 전송 양에 따라 요금 냄 -> 자주 사용하지 않는 콘텐츠는 빼라
- 적절한 만료 시한 설정 : 시의성이 중요한(time-sensitive) 콘텐츠 경우 만료 시점 잘 정해야. 너무 길지도 짧지도 않게.
- CDN 장애에 대한 대처 방안 : CDN 자체가 죽었을 경우 웹사이트가 어떻게 동작해야하는지 고려해야함. 만약 일시적으로 응답 없으면, 해당 문제 감지하여 원본 서버로부터 직접 콘텐츠를 가져오도록 클라이언트를 구성하는게 필요할수도
- 콘텐츠 무효화(invalidation) 방법
📍 데이터 센터
- 지리적라우팅(geoDNS-routing, geo-routing) : 장애가 없는 상황에서 사용자는 가장 가까운 데이터 센터로 안내된다.
- geoDNS : 사용자의 위치에 따라 도메인 이름을 어떤 IP주소로 변환할지 결정할 수 있도록 해주는 DNS 서비스
📍 메시지 큐
시스템을 더 큰 규모로 확장하기 위해서는 시스템의 컴포넌트를 분리하여, 각자 독립적으로 확장될 수 있도록 해야한다.
이를 위해 메시지 큐를 사용할 수 있다.
- 메시지 큐 (https://tecoble.techcourse.co.kr/post/2021-09-19-message-queue/)
- 프로세스 또는 프로그램 간에 데이터를 교환할 때 사용하는 통신 방법 중에 하나
- 메시지 지향 미들웨어(비동기 메시지를 사용하는 응용 프로그램들 사이에서 데이터를 송수신하는 것)
- 즉, 메시지를 저장하는 임시 버퍼이며 비동기적으로 전송 (메시지를 전송 및 수신하기 위해 중간에 메시지 큐를 두는 것)
- 메시지의 무손실 보장 (메시지 큐에 일단 보관된 데이터는 소비자가 꺼낼 때까지 안전히 보관된다)
- 메시지 큐를 이용하면 서비스 또는 서버 간 결합이 느슨해져서, 규모 확장성이 보장되어야 하는 안정적 애플리케이션 구성에 좋다.
- 생산자는 소비자가 죽어있어도 메시지를 발행할 수 있고, 소비자는 생산자 서비가 죽어있어도 메시지를 수신할 수 있다.
📍 정리
시스템 규모 확장을 위해 살펴본 기법들
- 웹 계층은 무상태 계층으로
- 모든 계층에 다중화 도입
- 가능한 한 많은 데이터를 캐시
- 여러 데이터 센터를 지원
- 정적 콘텐츠는 CDN을 통해 서비스
- 데이터 계층은 샤딩을 통해 규모 확장
- 각 계층은 독립적 서비스로 분할
- 시스템을 지속적으로 모니터링하고 자동화 도구들 활용
2. 영한님의 JPA 활용2편의 [섹션 2 : API 개발 고급 - 준비] 강의를 들었다.
📍 데이터 세팅
본격적인 강의 전에 @PostConstruct를 활용해 데이터를 미리 세팅해두는 작업.
얼마전 강의에서 본 내용이 나와서 반가웠다!
생성자 호출 -> 의존성 주입 -> @PostConstruct
@PostConstruct와 @Transactional을 같이사용하면 트랜잭션이 적용되지 않는다~ (초기화 코드 호출 이후 트랜잭션 AOP가 적용되기 때문)
📍 영속성 전이, 고아 객체
아 그리고 오랜만에 봐서 그런가 JPA의 cascade, orphan removal 쪽이 또 가물가물하길래..^^
예전에 정리해 둔 내용을 다시 봤다. 흑흑 왜 자꾸 까먹을까..
cascade
- 특정 엔티티를 영속 상태로 만들 때 연관된 엔티티도 함께 영속 상태로 만들고 싶은 경우 사용
- 이런식으로 cascade 옵션 달아주면 em.persist(parent) 한방으로 parent와 child들을 전부 저장할 수 있다.
- 주의) 영속성 전이는 연관관계 매핑과 아무 관련 없다.
그저 엔티티를 영속화할 때 연관된 엔티티도 함께 영속화하는 편리함을 제공할 뿐! - 언제 사용? 하나의 부모가 자식을 관리할 때 (ex. 게시판-첨부파일)
- 첨부파일은 한 게시판에서만 관리 : cascade 굿
- 그 파일을 여러군데에서 관리 (또는 다른 entity에서도 관리) : 쓰면안됨
- => 소유주가 하나일 때! 단일 entity에 완전히 종속될 때! 라이프사이클이 똑같을 때!
orphan removal
- orphanRemoval = true : 부모 엔티티와 연관관계 끊어진 자식 엔티티 자동 삭제
- parent.getChildren().remove(0) -> 자동으로 delete from child where ~ 쿼리 나감
- 언제 사용?
- 참조하는 곳이 하나일 때! 특정 엔티티가 개인 소유할 때!
- @onetoone, @onetomany만 가능
- 참고) 고아 객체 제거 기능 활성화 시, 부모 제거하면 자식도 함께 제거 (마치 cascadetype.REMOVE처럼)
영속성 전이 + 고아 객체 , 생명주기
- 스스로 생명주기를 관리하는 엔티티는 em.persist로 영속화, em.remove로 제거 → em을 통해서 생명주기 관리
- cascade, orphanremoval 다 키면 -> 부모 엔티티를 통해 자식 엔티티의 생명주기 관리
3. 영한님의 JPA 활용2편의 [섹션 3 : API 개발 고급 - 지연 로딩과 조회 성능 최적화] 강의를 들었다.
@ManyToOne, @OneToOne에서의 성능 최적화
강의에 사용되는 예제는 다음과 같다. 이중 Member와 Delivery를 포함한 Order 조회!
📍 v1. 엔티티 직접 노출
- 양방향 매핑 때문에 무한 루프 돌아서 jackson이 당황
- 지연로딩 설정해둬서 프록시라 jackson이 당황
그냥 말도 안됨.
📍 v2. 엔티티를 DTO로 변환
lazyloading으로 인해 db쿼리가 너무 많이 나감
쿼리가 총 1 + N + N번 실행된다.
- order 조회 1번(order 조회 결과 수가 N이 된다.)
- order -> member 지연 로딩 조회 N 번
- order -> delivery 지연 로딩 조회 N 번
=> 소위 N+1 문제 (첫번째 쿼리의 결과인 N만큼 쿼리 추가 실행)
cf) 지연 로딩은 영속성 컨텍스트에 있으면 영속성 컨텍스트에 있는 엔티티를 사용하고 없으면 SQL을 실행한다.
따라서 같은 영속성 컨텍스트에서 이미 로딩한 member 엔티티를 추가로 조회하면 SQL을 실행하지 않는다. (ex. 한 member가 여러번 order)
📍 v3. 엔티티를 DTO로 변환 + fetch join 최적화
fetch join, n+1 이쪽은 여전히 좀 아리송해서 강의를 계기로 정리해봤다!
- N+1 문제와 FetchType
- EAGER : JPQL에서 N+1문제 발생
- jpql은 “select m from Member m”을 그대로 sql로 변환 → member만 select → member만 가지고와서 봤더니 어라 즉시 로딩이네 → member 10개면 team select 10개 나감 → n+1문제
- em.find면 jpa가 join해줘서 쿼리 1번
- LAZY : 나중에 comments 필요할 때 호출하기 때문에 N+1문제 발생 (그래도 comments 필요없으면 쿼리 1개, 필요하면 1+N 날리는거기 때문에 LAZY 선호) -> jpql의 fetch join으로 해결
- EAGER : JPQL에서 N+1문제 발생
- join vs fetch join (https://cobbybb.tistory.com/18)
- join : SELECT 대상만 조회하여 영속화 (JOIN 대상에 대한 영속성 관여x)
- ex. post만 조회한다면 comments는 조회되지 않아 접근 불가
- 조회의 주체가 되는 Entity만 SELECT 해서 영속화하기 때문에 데이터는 필요하지 않지만 연관 Entity가 검색조건에는 필요한 경우에 주로 사용됨
- fetch join : SELECT 대상과 FETCH JOIN 대상 엔티티 함께 조회하여 영속화
- ex. post와 comments를 동시에 조회
- Fetch Join이 걸린 Entity 모두 영속화하기 때문에 FetchType이 Lazy인 Entity를 참조하더라도
이미 영속성 컨텍스트에 들어있기 때문에 따로 쿼리가 실행되지 않은 채로 N+1문제가 해결됨
- join : SELECT 대상만 조회하여 영속화 (JOIN 대상에 대한 영속성 관여x)
- FetchType.EAGER vs fetch join https://mighty96.github.io/til/fetch_fetchjoin/
📍 v4. JPA에서 DTO로 바로 조회
일반적인 SQL을 사용할 때 처럼 원하는 값을 선택해서 조회 new 명령어를 사용해서 JPQL의 결과를 DTO로 즉시 변환
v3보다 select 절에 들어가는 데이터가 줄어들었다.
v3 : order를 가져오는데 내가 원하는거만 fetch join. order을 건드리지 않음. 재사용성 굿
v4 : 재사용성 별로. API 스펙에 맞춘 코드가 리포지토리에 들어감. 성능최적화에서는 조금 더 나음(근데 생각보다 미비). 코드상 지저분
이 방법 선택할 경우 영한님께서는 보통 순수한 엔티티를 반환하는 리포지토리와 dto를 반환하는 리포지토리 분리 하신다고 한다.
📍 정리
엔티티를 DTO로 변환하거나(v3), DTO로 바로 조회하는(v4) 두가지 방법은 각각 장단점이 있다.
둘중 상황에 따라 서 더 나은 방법을 선택하면 된다.
엔티티로 조회하면 리포지토리 재사용성도 좋고, 개발도 단순해진다. 따라
서 권장하는 방법은 다음과 같다.
쿼리 방식 선택 권장 순서
1. 우선 엔티티를 DTO로 변환하는 방법을 선택한다. (v2)
2. 필요하면 페치 조인으로 성능을 최적화 한다. 대부분의 성능 이슈가 해결된다. (v3)
3. 그래도 안되면 DTO로 직접 조회하는 방법을 사용한다. (v4)
4. 최후의 방법은 JPA가 제공하는 네이티브 SQL이나 스프링 JDBC Template을 사용해서 SQL을 직접 사용
4. 영한님의 JPA 활용2편의 [섹션 4 : API 개발 고급 - 컬렉션 조회 최적화] 강의를 40%정도 들었다.
@OneToMany에서의 성능 최적화 (컬렉션 조회)
db 입장에서 1:N 조회는 뻥튀기.
예를 들어 일이 1고, 다쪽이 3면 조인하면 3줄로 뻥튀기 (주문 하나에 주문내역 3개면 조인하면 3줄)
강의에 사용되는 예제는 다음과 같다. 앞 강의에 이어 이번엔 OrderItems(그리고 그 안의 Item)까지 같이 조회하려함!
📍 v1. 엔티티 직접 노출
별로다
📍 v2. 엔티티를 DTO로 변환
지연로딩으로 N+1문제 발생. 근데 퀄렉션이라 더 나감.
- order 1번 (결과 N)
- member , address N번(order 조회 수 만큼)
- orderItem N번(order 조회 수 만큼)
- item N번(orderItem 조회 수 만큼)
📍 v3. 엔티티를 DTO로 변환 + fetch join 최적화
뻥튀기. order 2개인데 4개 나옴. 중복.
distinct 명령어 추가!
jpa에서 distinct 붙어있으면 order가 같은 id값 갖고있으면 중복 제거
근데 얘가 db단에서 작동하지는 않음 (db의 distinct 명령어는 모든 컬럼의 데이터가 같아야 똑같다고 인식)
distinct 를 사용한 이유는 1대다 조인이 있으므로 데이터베이스 row가 증가한다. 그 결과 같은 order 엔티티의 조회 수도 증가하게 된다. JPA의 distinct는 SQL에 distinct를 추가하고, 더해서 같은 엔티티가 조회되면, 애플리케이션에서 중복을 걸러준다. 이 예에서 order가 컬렉션 페치 조인 때문에 중복 조회 되는 것을 막아준다.
치명적 단점 : 페이징 불가능
1:N을 fetch join하는 순간 페이징 쿼리 아예 안나감!!!
컬렉션 페치 조인을 사용하면 페이징이 불가능하다. 하이버네이트는 경고 로그를 남기면서 모든 데이터를 DB에서 읽어오고, 메모리에서 페이징 해버린다(매우 위험하다). 자세한 내용은 자바 ORM 표준 JPA 프로그래밍의 페치 조인 부분을 참고하자.
1:N join하면 row가 뻥튀기되기 때문에 페이징 불가해짐 (order가 아니라 orderitem으로 페이징이 되어버림..)
=> 1:N fetch join에서는 페이징 하면 안된다. member나 delivery, item 괜찮. orderitem은 컬렉션이라 불가!
+) 컬렉션 fetch join은 1개만 가능!
컬렉션 페치 조인은 1개만 사용할 수 있다. 컬렉션 둘 이상에 페치 조인을 사용하면 안된다. 데이터가 부정합하게 조회될 수 있다. 자세한 내용은 자바 ORM 표준 JPA 프로그래밍을 참고하자.
5. 기타
- 직렬화 : 객체 또는 데이터를 바이트(byte) 형태로 변환하는 것
(객체에 저장된 데이터를 스트림에 쓰기write 위해 연속적인serial 데이터로 변환하는 것) - SPOF (Single Point of Failure) : 시스템 구성 요소 중에서, 동작하지 않으면 전체 시스템이 중단되는 요소
- 가용성 : 서버와 네트워크 또는 다양한 시스템의 정상적으로 사용 가능한 정도 (정상동작시간/전체사용시간)
- failover : 장애 대비 기능 (https://oriyong.tistory.com/80)
- 실패(fail)를 끝낸다(over)
- 시스템에 장애가 생기면 미리 준비해둔 다른 시스템으로 대체해서 운영
- 운영 되고 있는 시스템 : active
- 같은 세팅으로 구성된 대기 시스템 : passive
- 운영중에 active 시스템에 문제가 생기면 passive 시스템이 active 상태로 변경되면서 이어서 운영
- 서버 다중화 했을 때 세션의 문제점을 해결하는 방법 (https://smjeon.dev/web/sticky-session/)(https://cl8d.tistory.com/77)
- sticky session : 특정 세션의 요청을 처음 처리한 서버로만 전송
- session clustering : 세션들을 하나로 묶어 클러스터로 관리
- session server 분리 (session storage 구성)
- NoSQL
- 관계형 데이터베이스가 아닌 다양한 형태의 데이터 저장 및 관리를 위한 데이터베이스 기술을 일컫는 용어
- 관계형 데이터베이스와 비교하여 스키마의 유연성, 읽기/쓰기 성능, 확장성 등에서 강함
- 데이터 모델의 유연성과 확장성을 강조하며, 대용량 데이터 처리나 다양한 형태의 데이터 구조를 다루는 데 특히 적합
- 하지만 이에 따라 데이터 무결성이나 트랜잭션 처리와 같은 측면에서는 일부 제약이 있을 수 있음
- Redis
- NoSQL 데이터베이스 중 하나. key-value 스토어 유형
- 인메모리 데이터 저장소
- 주요 사용 사례 : 캐싱, 세션 관리, 실시간 분석, 메시지 큐 등
- 단일 서버 또는 클러스터 형태로 운영할 수 있다.
- DB는 데이터를 물리 디스크에 직접 쓰기 때문에 서버를 껐다 켜도 데이터가 사라지지 않음. 하지만 매번 디스크에 접근해야하기 때문에 사용자 많아질 수록 느려짐.
- 샤딩 vs 파티셔닝 (https://hudi.blog/db-partitioning-and-sharding/)
- 둘 다 데이터베이스 분할 방법!
- 파티셔닝 : 하나의 데이터베이스 안에서 하나의 테이블을 여러 테이블로 분리
- 매우 큰 테이블을 여러개의 테이블로 분할하는 작업
- 큰 데이터를 여러 테이블로 나눠 저장하기 때문에 쿼리 성능이 개선될 수 있다.
- 데이터는 물리적으로 여러 테이블로 분산하여 저장되지만, 사용자는 마치 하나의 테이블에 접근하는 것과 같이 사용할 수 있다
- 샤딩 : 동일한 스키마를 가지고 있는 여러대의 데이터베이스 서버들에 데이터를 작은 단위로 나누어 분산 저장하는 기법
- 물리적으로 서로 다른 컴퓨터에 데이터를 저장하므로, 쿼리 성능 향상과 더불어 부하가 분산되는 효과까지 얻을 수 있다.
- 즉, 샤딩은 데이터베이스 차원의 수평 확장(scale-out)인 셈
- 파티셔닝은 모든 데이터를 동일한 컴퓨터에 저장하지만, 샤딩은 데이터를 서로 다른 컴퓨터에 분산한다