
1. 책 [가상 면접 사례로 배우는 대규모 시스템 설계 기초]의 [2장. 개략적인 규모 추정]을 읽었다.
📍개략적인 규모 추정
- 보편적으로 통용되는 성능 추시상에서 사고 실험을 행하여 추정치를 계산하는 행위
- 어떤 설계가 요구사항에 부합할 것인지를 보기 위한 것
📍 2의 제곱수
데이터 볼륨의 단위를 2의 제곱수를 표현하면 어떻게 되는지를 우선 알아야 한다.
1바이트 = 8비트 (최소 단위)(ASCII 문자 하나가 차지하는 메모리 크기)
| 축약형 | 2의 제곱 | 근사치 | 이름 |
| 1KB | 2^10B | 1,000(1천) | 1킬로바이트 |
| 1MB | 2^20B | 1,000,000(1백만) | 1메가바이트 |
| 1GB | 2^30B | 1,000,000,000(10억) | 1기가바이트 |
| 1TB | 2^40B | 1,000,000,000,000(1조) | 1테라바이트 |
| 1PB | 2^50B | 1,000,000,000,000(1000조) | 1페타바이트 |
📍 모든 프로그래머가 알아야 하는 응답지연값
| 축약형 | 10의 제곱 | 이름 |
| 1ns | 10^-9초 | nanosecond(나노초) |
| 1μs | 10^-6초 | microsecond(마이크로초) |
| 1ms | 10^-3초 | millisecond(밀리초) |
책 34p에 통상적인 컴퓨터 연산들의 처리 속도 표가 나와있다! 필요하면 참고~ 요약하자면 다음과 같다
- 메모리는 빠르지만 디스크는 아직도 느리다
- 디스크 탐색(seek)는 가능한 피하라
- 단순한 압축 알고리즘은 빠르다
- 데이터를 인터넷으로 전송하기 전에 가능하면 압축하라
- 데이터 센터는 보통 여러 지역(region)에 분산되어 있고, 센터들 간 데이터 주고받는 데에 시간이 걸린다.
📍 가용성에 관계된 수치들
- 고가용성 : 시스템이 오랜 시간 동안 지속적으로 중단 없이 운영될 수 있는 능력
- %로 표현
- 대부분의 서비스는 99%~100% 사이의 값을 가짐
- 가용시간은 관습적으로 숫자 9를 사용해 표시
- 9가 많으면 많을수록 좋다.
- ex) 가용률 99% = 하루 장애 시간 14.4분 = 주당 장애 시간 1.68시간 = 개월당 장애시간 7.31 = 연간 장애시간 3.65일
📍 예제 : 트위터 QPS와 저장소 요구량 측정
<가정>
- 월간 능동 사용자는 3억 명
- 50%의 사용자가 트위터 매일 사용
- 평균적으로 각 사용자는 매일 2건의 트윗 올림
- 미디어 포함 트윗은 10%정도
- 데이터는 5년간 보관된
추정
- QPS(Query Per Second) 추정치
- 일간 능동 사용자 = 3억 * 50% = 1.5억
- QPS = 1.5억 * 2트윗 / 24시간 / 3600초 = 약 3500
- 최대 QPS = 보통 2 * QPS = 7000
- 미디어 저장을 위한 저장소 요구량
- 평균 트윗 크기
- tweed_id에 64B
- 텍스트에 140B
- 미디어에 1MB
- 미디어 저장소 요구량 : 1.5억 * 2 * 10% * 1MB = 30TB/일
- 5년간 미디어를 보관하기 위한 저장소 요구량 : 30TB * 365 * 5 = 약 55PB
- 평균 트윗 크기
📍 팁
- 개략적인 규모 추정 관련 면접에서 중요한 것은 문제를 풀어나가는 절차!
- 올바른 절차를 밟느냐가 결과를 내는 것보다 중요
- 근사치를 활용한 계산
- ex. 99987/9.1 이런거 실제로 계산하는거 시간낭비. 적절히 근사치 골라서 계산. 예를 들어 100,000/10 이런식으로
- 가정들은 적어두라. 나중에 살펴볼 수 있도록
- 단위를 붙여라 (안 붙이면 헷갈림)
- 많이 출제되는 문제 : QPS, 최대 QPS, 저장소 요구량, 캐시 요구량, 서버 수 등 추정
2. 테코톡에 올라온 [락] 시리즈를 쫙 봤다.
- Lock : 데이터 접근을 Lock(막는) 장치
- DB의 일관성과 무결성을 유지하기 위해 트랜잭션의 순차적 진행을 보장할 수 있는 직렬화 장치
- 여러개의 트랜잭션에서 동시에 접근해서 수정하려 할 때 데이터의 일관성이 깨질 수 있다. 그래서 잠금을 해야한다.
- 여러 사용자들이 존재하는 환경에서 동시성 제어를 위해 필요
- Optimistic Lock : 충돌 발생X 가정 -> 충돌나면 그때 조치 취함
- 낙관적인 : 기본적으로 데이터 갱신시 충돌이 발생하지 않을 것이라고 낙관적으로 보는 것
- 비선점적인 : 데이터 갱신시 충돌이 발생하지 않을 것이라고 예상하기 때문에, 우선적으로 락을 걸지 않는다.
- 어플리케이션 락 -> Version을 사용해 관리 (JPA에서는 @Version)
- 충돌 방지
- 장 : 데드락 가능성 적고 성능상 이점
- 단 : 충돌 발생시 오버헤드 발생 (다 롤백해야하기 때문)
- Pessimistic Lock : 매번 충돌 발생O 가정 -> 락걸고 시작
- 비관적인 : 기본적으로 데이터 갱신이 충돌이 발생할 것이라고 비관적으로 보고 미리 잠금을 거는 것 (동시에 수정할 가능성이 높다고 가정)
- 선점적인 : 데이터 갱신시 충돌이 발생할 것이라고 예상하기 때문에, 우선적으로 락을 건다. (조회할 때부터 건다)
- 가져올 때 DB에 락을 건다
- Mode 설정 및 쿼리에 직접 사용. DB단에서 설정 가능.
- 데이터베이스 락
- 무결성의 장점
- 데드락의 위험성
- 연산의 종류
- Shared Lock(S Lock) : read에 대한 Lock
- 다른 사용자가 동시에 읽을 수는 있지만, Update Delete 방지
- SELECT ... LOCK IN SHARE MODE / SELECT ... FOR SHARE
- S Lock이 걸려있으면 다른 트랜잭션은 S Lock은 걸 수 있지만, X Lock은 걸 수 없다
- Exclusive Lock(X Lock) : read&write에 대한 Lock
- 다른 사용자가 읽기, 수정, 삭제 모두를 불가능하게 함
- SELECT ... FOR UPDATE / UPDATE / DELETE
- 등 수정 쿼리를 날릴 때 각 row에 걸리는 Lock
- X Lock 걸려있으면 다른 트랜잭션은 S Lock, X Lock 둘 다 걸 수 없다
- Shared Lock(S Lock) : read에 대한 Lock
- 장 : 충돌에 대한 오버헤드 줄어듦. 무결성 지키기 용이
- 단 : 충돌이 없으면 오버헤드 발생
- 각각 어떨 때 쓰면 좋을까요?
- Optimisstic Lock
- 동시 업데이트가 거의 없는 경우
- 이유 : 롤백 할 가능성 높다. 빈번하게 일어날 수 있다.
- Pessimistic Lock : 비관적 잠금
- 동시 업데이트가 빈번한 경우
- (롤백을 하기 힘든) 외부 시스템과 연동한 경우
- Optimisstic Lock
- Lock의 단위

- Lock을 남발했을 때의 문제점1 : Blocking
- Lock들의 경합이 발생하여 특정 세션이 작업을 진행하지 못하고 멈춰 선 상태
- 데이터에 대해 하나의 트랜잭션이 X Lock을 걸면 다른 트랜잭션들은 어떠한 Lock도 걸지 못하고 대기해야함
- 풀리는 시점 : 트랜잭션이 commit / rollback
- 해결방안
- 트랜잭션 짧게 정의
- 같은 데이터를 갱신하는 트랜잭션이 동시에 수행되지 않도록 설계
- LOCK TIMEOUT을 이용하여 잠금해제 시간을 조절
- Lock을 남발했을 때의 문제점2 : DeadLock(교착상태)
- 해결방안
- 트랜잭션 진행방향을 같은방향으로 처리
- 트랜잭션 처리속도 최소화
- LOCK TIMEOUT을 이용하여 잠금해제 시간을 조절
- 해결방안
- Lock vs Transaction
- Lock : 동시성 제어
- 동시에 발생하는 수정 요청에 대한 데이터 일관성을 지키기 위한 매커니즘
- Transaction : All or Nothing (원자성)
- 트랜잭션 격리 수준 : 여러 트랜잭션에 대해 각 트랜잭션들을 어떻게 처리할지에 대한 전
- 트랜잭션 격리 수준을 구현하는 방법중 하나가 Lock
- Lock : 동시성 제어
<로건과의 대화>
낙관적 Lock이든 비관적 Lock이든 아무것도 안 걸음 + 충돌 발생 -> 동시성 문제 발생!!
낙관적 Lock 걸음 + 충돌 발생 -> 에러 핸들링
비관적 Lock 걸음 + 충돌 발생 -> 동시성 문제 안 발생 (근데 예외상황은 언제나 있다..)
3. 구구의 [FileTest]를 기반으로 File 클래스에 대해 학습했다.
우테코 레벨4에서는 스프링 직접 만들어보기 시리즈가 미션이다.
첫번째 미션은 바로바로 Tomcat 만들기!!
본격적인 미션에 앞서 사전지식을 위해 코치 구구가 제공한 FileTest를 학습했다.
웹서버는 사용자가 요청한 html파일을 제공할 수 있어야 한다.
File 클래스를 사용해 파일을 읽어오고, 사용자에게 전달한다.
📍 File 클래스
- 파일 또는 폴더를 다룰 수 있는 클래스 -> File 인스턴스는 파일일수도 디렉토리일수도!
- File 객체를 생성한다고 파일이나 폴더가 생기지 않는다.
- 파일과 폴더가 없어도 예외가 발생하지 않는다.
- 여부를 알아보려면 객체 생성 뒤 exists() 메소드를 호출해야한다.
- exists() false면 : createNewFile(), mkdir() 등을 사용해 새로운 파일이나 폴더 생성 가능
- exists() true면 : delete(), getName(), getParent() 등 사용 가능
https://www.devkuma.com/docs/java/file-class/
+) file vs path (https://www.baeldung.com/java-path-vs-file)
- 둘 다 파일 및 디렉토리 경로 다루는데 사용됨
- 일반적으로 Java 7 이후에는 path 클래스 권장 (더 강력한 파일 조작 기능 제공)
📍 resource 디렉토리 경로 찾기

ClassLoader의 getResource() 메소드로 해당 리소스를 찾을 수 있다.
해당 리소스의 경로를 가져오기 위해서는 getFile() 메소드를 사용한다.
📍 파일 내용 읽기

https://parkadd.tistory.com/113
4. 구구의 [IOStreamTest]를 기반으로 InputStream과 OutputStream에 대해 학습했다.
📍 데이터 입출력
- 데이터는 사용자로부터 키보드, 마우스 등을 통해 입력 될 수 있고, 파일 또는 네트워크를 통해 입력될 수 있음.
- 모니터, 파일 등으로도 출력할 수도 있음.
자바에서 데이터는 Stream을 통해 입출력됨
- Stream은 단일 방향으로 연속적으로 흘러가는 것을 의미, 데이터가 출발지에서 나와 도착지로 흘러간다는 개념
- 프로그램이 출발지/도착지인지에 따라 스트림의 종류가 결정됨.
- 데이터를 입력 받을 때 - InputStream
- 데이터를 출력 할 때 - OutputStream
- +) FilterStream은 InputStream이나 OutputStream에 연결될 수 있다.
읽거나 쓰는 데이터를 수정할 때 사용한다. (e.g. 암호화, 압축, 포맷 변환)
📍 java.io 패키지

- 바이트 단위 입출력 스트림 : 그림, 멀티미디어, 문자등 모든 종류의 데이터들을 주고 받을 수 있다.
- 문자 단위 입출력 스트림 : 오로지 문자만 주고받을 수 있게 특화되어 있다.
InputStream : 바이트로 데이터 읽음
InputStreamReader : 문자로 데이터 읽음
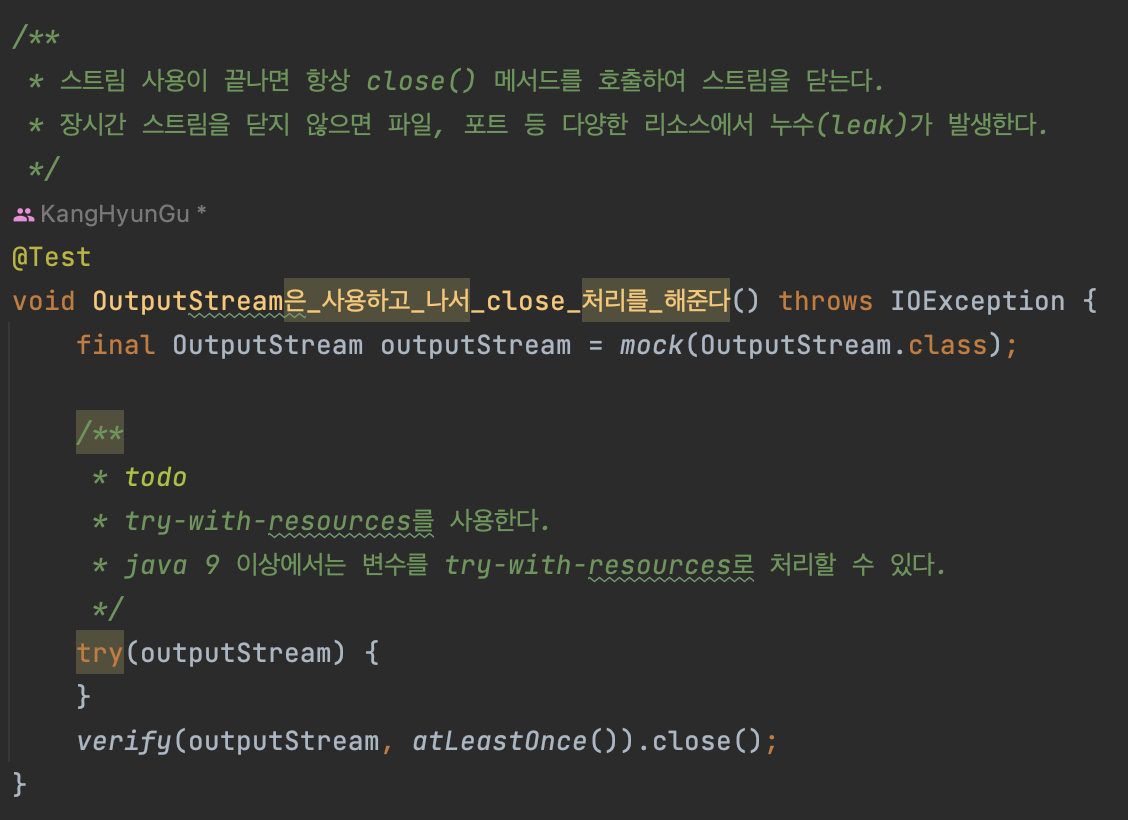
📍 OutputStream
- write()

- 사용 후 close 필수
- try-with-resources
- try에 자원 객체를 전달하면, try 코드 블록이 끝나면 자동으로 자원을 종료해주는 기능
- 즉, 따로 finally 블록이나 모든 catch 블록에 종료 처리를 하지 않아도 된다.
- 이 때, try에 전달할 수 있는 자원은 AutoCloseable 인터페이스의 구현체로 한정된다.
- try-with-resources
📍 InputStream
- read()

InputStream을 InputStreamReader로 변환 후 문자열로 변환 (다른 방법)
- 사용 후 close 필수
📍 FilterStream


- BufferedOutputStream
- 기본적인 파일 입출력 클래스들은 파일을 직접 읽거나 쓸때마다 직접 하드(보조기억장치)에 접근하기 때문에 성능 좋지 않음
- 이 문제를 해결하기 위해 사용하는 것이 버퍼
- 데이터를 읽어올 때 한번에 읽어 버퍼에 두거나, 데이터를 쓸 때 버퍼에 써두고 한번에 출력

- BufferedInputStream
