
1. DI 학습테스트를 했다.
📍 IoC (Inversion Of Control)



메인클래스에서 객체를 생성하고 관계를 설정해주고 있다.
하지만 메인 클래스에서 객체 생성과 관계 설정을 맡는게 적절한가?
생성해야 할 객체가 더 많아진다면?


객체 생성과 관계 설정의 책임을 main에서 factory로 이동
새로 추가한 factory는 일종의 IoC 컨테이너다.
객체의 제어 권한을 factory에게 넘겼다.
클라이언트(Main)가 능동적으로 사용할 클래스를 만들고 연결하지 않는다.
클라이언트는 팩터리가 제공하는 클래스를 사용하면 된다. 구체 클래스를 몰라도 된다.


소스코드 외부 파일인 properties로 런타임에 어떤 객체를 사용할지 동적으로 결정할 수 있다.
팩터리를 보면 어떤 객체가 생성되고, 어떤 객체가 연결되는지 알 수 있다.
현재 팩터리 클래스는 특정 객체만 생성, 연결 가능하다.
다른 객체의 생성, 연결, 라이프 사이클을 관리하는 팩터리를 만들면 어떨까?
-> 우리의 factory를 bean factory로 바꿔보자

예제의 프로퍼티 파일처럼 어떤 클래스를 사용할지 외부에서 결정하기 위해 XML을 사용한다. 하지만 XML로 관리하기 불편하다.
지금은 클래스에 @Configuration 을 붙이면 XML 대신 자바 코드로 설정 가능하다.
스프링 IoC의 종류
- Dependency Lookup(DL)
- 의존성 풀(dependency pull)
- 의존성 풀에서 필요한 객체를 직접 가져오는 방식
- 직접 필요한 의존관계를 찾는 것
final ApplicationContext context = new ClassPathXmlApplicationContext("exchange-rate-context.xml");
final ExchangeRateRenderer renderer = context.getBean("exchangeRateRenderer", ExchangeRateRenderer.class);- Dependency Injection(DI)
- 의존관계를 외부에서 주입받는 것
- 각 클래스간의 의존성을 자신이 아닌 외부(컨테이너)에서 주입
- 생성자 주입, 수정자 주입, 필드 주입
The main difference between the two approaches is "who is responsible for retrieving the dependencies".
Usually, in DI(dependency injection) your component isn't aware of the DI container and dependencies "automagically" appear (e.g. you just declare some setters/ constructor parameters and the DI container fills them for you).
In, DL (dependency lookup) you have to specifically ask for what you need. What this means in practice is that you have a dependency on the context (in spring the Application context) and retrieve whatever you need from it.
📍학습테스트 진행 내용
stage0 : 정적 참조 (서비스, DAO 클래스를 static 키워드를 사용하여 구현)



UserService는 UserDao에 밀접하게 결합되어 있다. -> 테스트하기 어렵다
테스트 DB를 사용하려면 코드 수정 불가피
stage1: 생성자 주입 (서비스 클래스의 생성자 파라미터에 DAO 객체를 전달한다)
0단계의 주요 문제는 정적 메서드만 있어서 클래스 간에 매우 긴밀한 결합이 발생한다는 것이다.
우리는 의존하는 객체를 필요에 따라 교체할 수 있게 만들고 싶다.
-> 다른 구현체로 교체할 수 있도록 만들어보자!



stage2: 인터페이스로 생성자 주입 (DAO를 인터페이스로 확장한다.서비스 클래스의 생성자 파라미터에 DAO의 구현체를 전달한다)


인터페이스의 구현 객체를 직접 생성해서 넣어준다.
stage3: 제어의 역전
stage2에서 객체는 능동적으로 자신이 사용할 클래스를 결정하고, 직접 객체를 생성했다.
하지만 제어의 역전이라는 개념이 적용되면 객체는 자신이 사용할 객체를 직접 선택하고 생성하지 않는다.
모든 제어 권한을 자신이 아닌 다른 대상에게 위임한다.

/**
* 스프링의 BeanFactory, ApplicationContext에 해당되는 클래스
*/
class DIContainer {
private final Set<Object> beans;
public DIContainer(final Set<Class<?>> classes) throws Exception {
this.beans = createBeans(classes);
for (Object bean : this.beans) {
setFields(bean);
}
}
// 기본 생성자로 빈을 생성한다. (객체 생성)
// 전달 받은 클래스를 객체로 생성한다.
private Set<Object> createBeans(final Set<Class<?>> classes) throws Exception {
Set<Object> beans = new HashSet<>();
for (Class<?> aClass : classes) {
Constructor<?> constructor = aClass.getDeclaredConstructor();
constructor.setAccessible(true);
Object bean = constructor.newInstance();
beans.add(bean);
}
return beans;
}
// 빈 내부에 선언된 필드를 각각 셋팅한다. (관계 설정)
// 각 필드에 빈을 대입(assign)한다.
// 객체의 내부 필드의 타입에 맞는 객체(bean)를 찾아서 대입(assign)한다.
private void setFields(final Object bean) {
Field[] fields = bean.getClass().getDeclaredFields();
for (Field field : fields) {
Class<?> fieldType = field.getType();
beans.stream()
.filter(it -> isAssignableType(fieldType, it))
.findFirst()
.ifPresent(it -> assignField(bean, field, it));
}
}
private boolean isAssignableType(final Class<?> type, final Object it) {
Class<?> aClass = it.getClass();
return type.isAssignableFrom(aClass);
}
private void assignField(final Object bean, final Field field, final Object it) {
field.setAccessible(true);
try {
field.set(bean, it);
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
}
}
// 빈 컨텍스트(DI)에서 관리하는 빈을 찾아서 반환한다.
@SuppressWarnings("unchecked")
public <T> T getBean(final Class<T> aClass) {
Object o = beans.stream()
.filter(it -> isAssignableType(aClass, it))
.findFirst()
.get();
return (T) o;
}
}
stage4: 알아서 클래스 읽어서 bean으로 등록하게
- stage3에서 구현한 기능을 기본적으로 제공한다.
- 생성자 파라미터로 패키지명을 받아서 클래스를 찾는 ClassPathScanner를 구현한다.
- @Service, @Repository가 존재하는 클래스만 객체로 생성한다.
- 객체에서 @Inject를 붙인 필드만 필터하고 타입에 맞는 객체(bean)를 찾아서 대입(assign)한다.

public class ClassPathScanner {
public static Set<Class<?>> getAllClassesInPackage(final String packageName) {
Reflections reflections = new Reflections(packageName);
Set<Class<?>> classes = new HashSet<>();
classes.addAll(reflections.getTypesAnnotatedWith(Service.class));
classes.addAll(reflections.getTypesAnnotatedWith(Repository.class));
return classes;
}
} public static DIContainer createContainerForPackage(final String rootPackageName) throws Exception {
Set<Class<?>> classes = ClassPathScanner.getAllClassesInPackage(rootPackageName);
return new DIContainer(classes);
}
Context로 객체와 객체 간의 의존 관계를 설정한다. (언제? 컴파일 말고 런타임에)
서비스, DAO 객체는 하나만 존재해도 충분하다. -> 서버 환경에서 최적의 성능을 내기 위해서 싱글톤 패턴 사용
📍 컴파일 타입 의존성 주입 vs 런타임 의존성 주입
컴파일 타임 의존성 주입이라고 하는 것은 클래스 간의 의존성이 코드 컴파일 시점에 결정되고 정적으로 고정되는 것을 의미합니다.
스프링의 경우, 의존성은 XML 설정, 어노테이션 또는 자바 설정 클래스와 같은 외부 리소스를 통해 정의되며, 이러한 설정 정보를 바탕으로 런타임에 객체를 생성하고 의존성을 주입합니다.
따라서 스프링을 사용한 경우, 의존성 주입은 런타임에 이루어지는 것이고, 설정 클래스 자체가 컴파일 타임 의존성 주입이라기보다는 의존성 설정을 위한 메타데이터 역할을 합니다.
컴파일 타임에 이미 알려진 정적 의존성이 있는 경우, 컴파일러가 해당 의존성을 검증하고 코드를 컴파일할 때 의존성 주입이 이루어집니다.
public class MyService {
private MyDependency dependency;
public MyService() {
this.dependency = new MyDependency(); // 컴파일 타임에 의존성 주입
}
// ...
}
2. Servlet 학습테스트를 했다.
📍 Servlet은 최초 1회만 생성
Servlet은 웹 어플리케이션의 생명 주기 동안 하나의 인스턴스만 생성되고 이 인스턴스가 여러 클라이언트 요청에 대해 서비스를 제공합니다. 이를 통해 서버 리소스를 효율적으로 관리할 수 있습니다. 따라서 서블릿 컨테이너 (예: Apache Tomcat)는 서블릿 클래스를 로드하고 초기화한 후에 이를 재사용하며, 각 요청마다 새로운 스레드가 생성되어 서블릿의 service() 메서드를 호출합니다.
이러한 특성으로 다음과 같은 이점을 제공합니다:
1. 자원 공유: 여러 클라이언트 간에 공통된 자원을 사용할 때 유용하며, 서블릿 컨텍스트를 통해 데이터를 공유할 수 있습니다.
2. 성능 향상: 서블릿 인스턴스를 재사용함으로써 객체 생성 및 소멸에 드는 비용을 절감하고 빠른 응답을 제공할 수 있습니다.
3. 메모리 절약: 여러 인스턴스를 생성하는 대신 단일 인스턴스를 사용하므로 메모리 사용량이 줄어듭니다.
그러나 주의점도 있습니다. 서블릿은 멀티스레드 환경에서 동작하므로 동시에 여러 요청을 처리할 때 스레드 안전성에 신경을 써야 합니다. 또한, 싱글톤 패턴을 오용하면 상태 공유로 인한 문제가 발생할 수 있으므로 신중하게 설계해야 합니다.
각 서블릿 객체는 하나만 존재. 근데 싱글톤은 아니다!
이유: 톰캣이 구조상 서블릿을 한번 실행할 뿐이지 생성자 호출하면 하나 더 생성할 수 있긴함. 그니까 싱글톤은 아님
📍 Servlet 학습테스트

3번 요청 보냈을 때
init 1회
doFilter & service 3회
destroy 1회
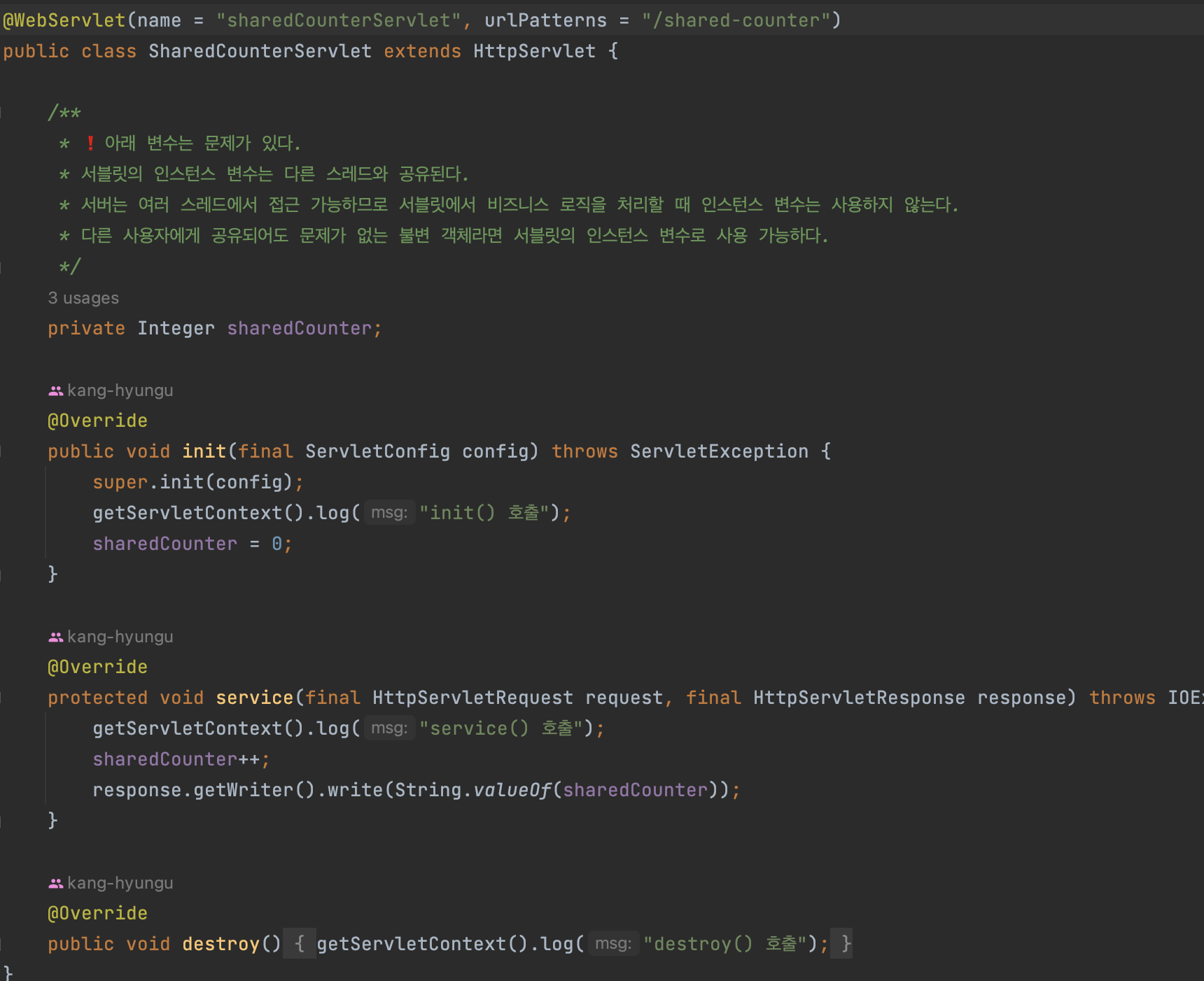

서블릿은 객체를 최초에 한번만 만들어두고 계속 사용한다.
그러므로 인스턴스 변수가 공유된다.
=> 서블릿에 상태를 두는건 좋지 않은 선택이다


servlet의
service() : HTTP 요청 메서드에 상관없이 모든 유형의 요청에 대해 호출됨
doGet() : HTTP GET요청에 대해서만 호출됨
📍Filter 학습테스트
doFilter메서드는 service메서드 호출 직전에 호출된다.



encoding을 따로 설정해줘야 하는 이유? 따로 설정안해주면 이상한걸로 인코딩함.
If no charset is specified, ISO-8859-1 will be used.
The setCharacterEncoding, setContentType, or setLocale method must be called before getWriter and before committing the response for the character encoding to be used.
📍 FilterChain
Servlet의 FilterChain은 서블릿 필터(Filter)가 여러 개 있을 때, 이 필터들을 연쇄적으로 실행시키는 데 사용되는 인터페이스입니다. FilterChain은 필터들의 체인을 구성하고 다음 필터로 요청을 전달하거나 요청을 최종적으로 서블릿으로 전달하는 역할을 합니다.

- 클라이언트로부터의 요청이 서블릿 컨테이너에 도달하면, 필터 체인의 첫 번째 필터부터 시작합니다.
- 첫 번째 필터에서 doFilter() 메서드를 호출하여 요청을 다음 필터로 전달합니다. 이 때, 첫 번째 필터는 FilterChain 인터페이스의 구현체인 FilterChain 객체를 매개변수로 전달합니다.
- 두 번째 필터에서도 마찬가지로 doFilter() 메서드를 호출하여 요청을 다음 필터로 전달합니다. 이러한 과정이 필터 체인의 모든 필터를 거치게 됩니다.
- 필터 체인의 마지막 필터에서는 요청을 최종적으로 해당 요청을 처리할 서블릿으로 전달하거나, 필터 체인이 종료될 때 요청을 처리합니다.
📍 ServletResponse (참고)
Defines an object to assist a servlet in sending a response to the client. The servlet container creates a ServletResponse object and passes it as an argument to the servlet's service method.
To send binary data in a MIME body response, use the ServletOutputStream returned by getOutputStream().
To send character data, use the PrintWriter object returned by getWriter().
To mix binary and text data, for example, to create a multipart response, use a ServletOutputStream and manage the character sections manually.
The charset for the MIME body response can be specified explicitly using the setCharacterEncoding(java.lang.String) and setContentType(java.lang.String) methods, or implicitly using the setLocale(java.util.Locale) method. Explicit specifications take precedence over implicit specifications. If no charset is specified, ISO-8859-1 will be used.
The setCharacterEncoding, setContentType, or setLocale method must be called before getWriter and before committing the response for the character encoding to be used.

📍 MIME type (참고)
A media type indicates the nature and format of a document, file, or assortment of bytes.
구조
- type/subtype
- The type represents the general category into which the data type falls, such as video or text.
- The subtype identifies the exact kind of data of the specified type the MIME type represents.
For example, for the MIME type text, the subtype might be plain (plain text), html (HTML source code)
- type/subtype;parameter=value
- An optional parameter can be added to provide additional details
- For example, for any MIME type whose main type is text, you can add the optional charset parameter to specify the character set used for the characters in the data. (text/plain;charset=UTF-8)
Type
- Discrete types are types which represent a single file or medium, such as a single text or music file, or a single video.
- A multipart type represents a document that's comprised of multiple component parts, each of which may have its own individual MIME type; or, a multipart type may encapsulate multiple files being sent together in one transaction. For example, multipart MIME types are used when attaching multiple files to an email.
기타


