23.10.24
1. 조영호님의 [우아한 객체지향] 강의를 들었다.
https://www.youtube.com/watch?v=dJ5C4qRqAgA&t=4439s
어떻게 의존성을 관리해야 하는가?
📍 의존성
설계 : 코드를 어떻게 배치할 것인가
그럼 어디에 어떤 코드를 넣어야 할까? -> "변경"에 초점 (같이 변경되는 코드를 같이 넣어야함) -> 의존성
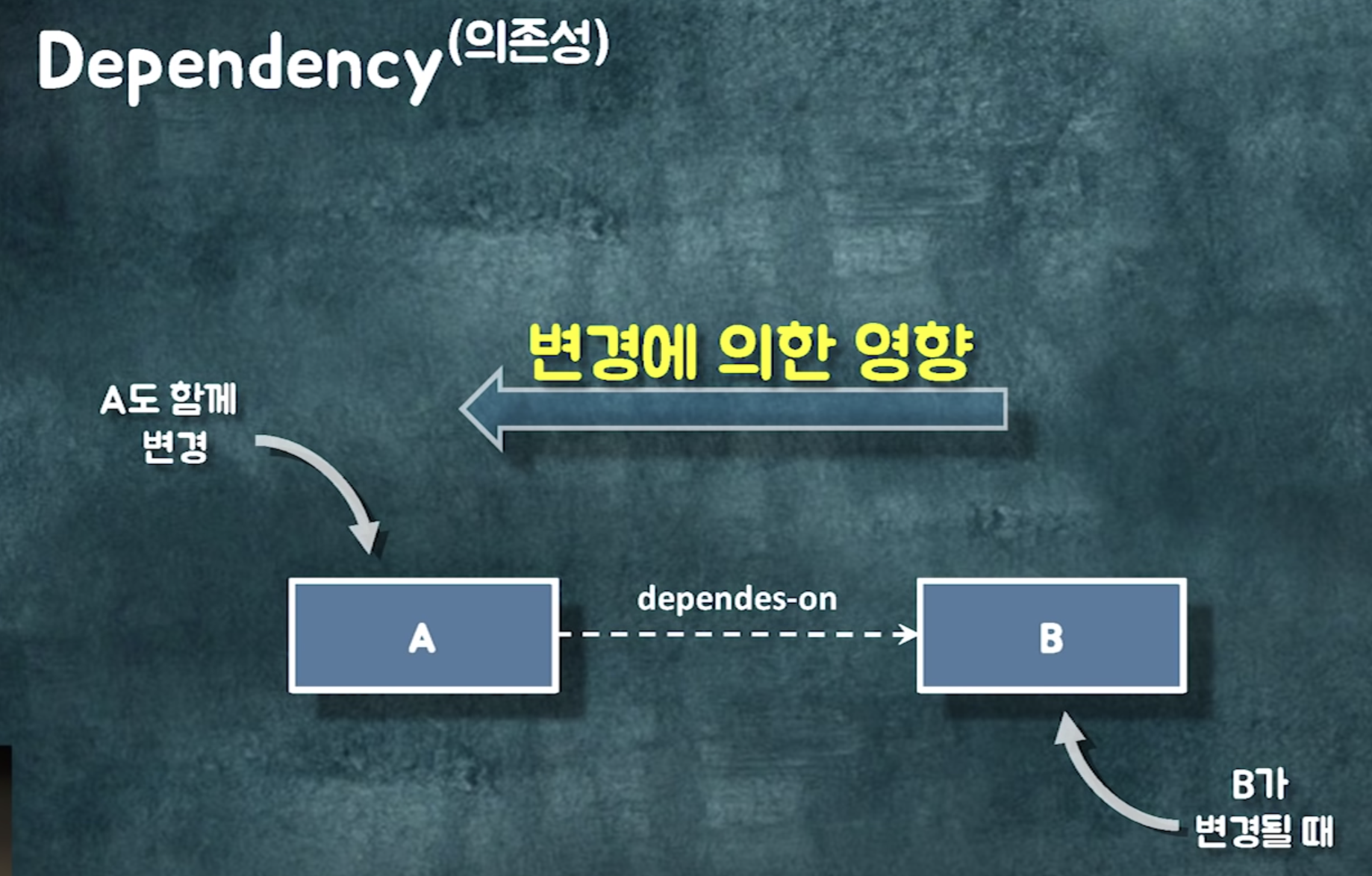
1. 클래스 사이의 dependency
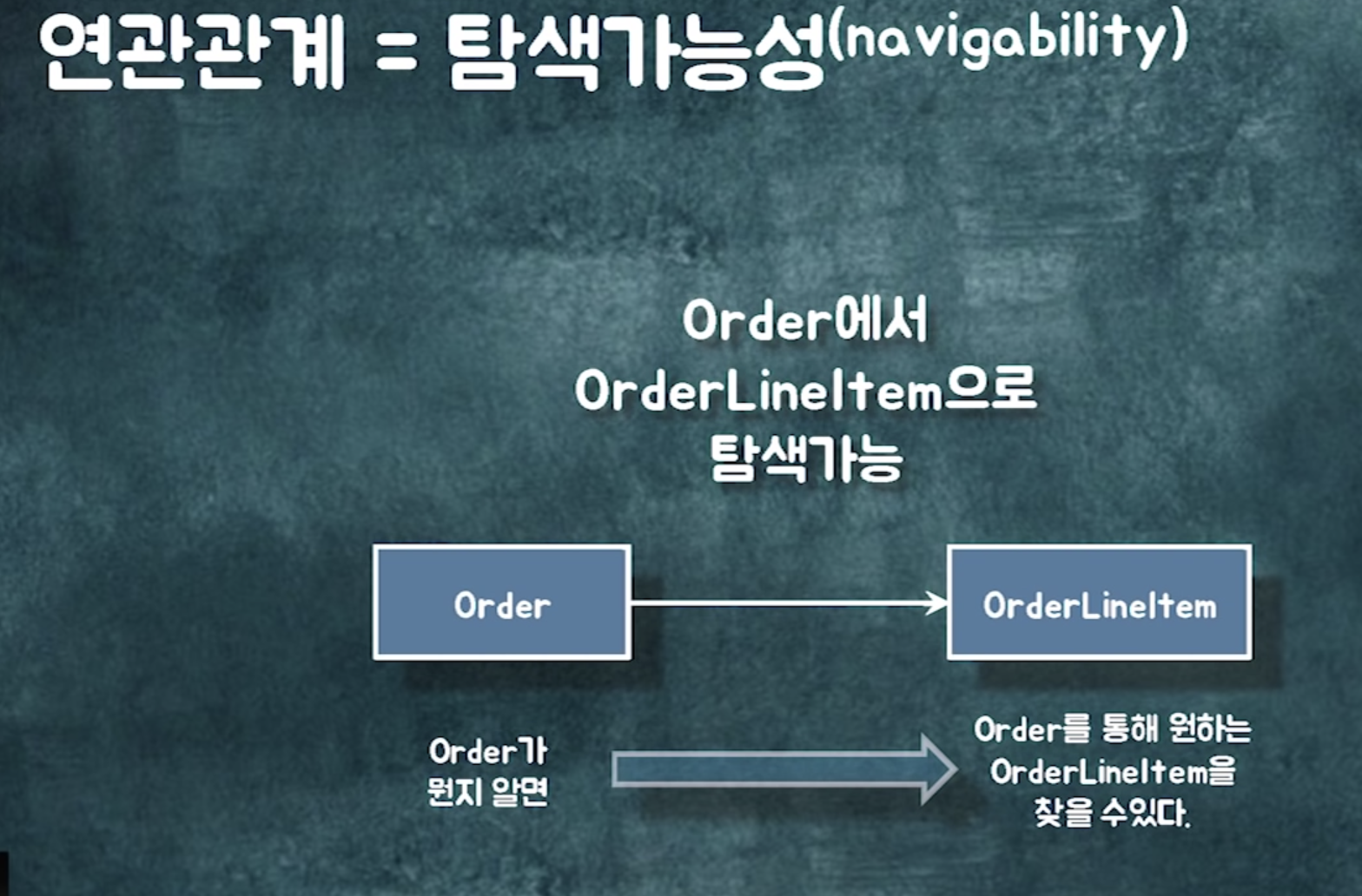
1)연관관계 : a에서 b로 이동할 수 있어요 (객체 참조) . 영구적으로 갈 수 있는 경로

2) 의존관계 : 파라미터 또는 반환값에 해당 타입이 나오거나, 메서드 안에서 해당 타입의 인스턴스를 만드는것 . 일시적으로 갈 수 있는 경로

3) 상속 관계 : extends

4) 실체화 관계 : implements

(상속 vs 실체화 : 상속은 구현이 바뀌더라도 영향받음. 인터페이스는 시그니처가 바뀌었을때만 영향받음)
2. 패키지 사이의 dependency
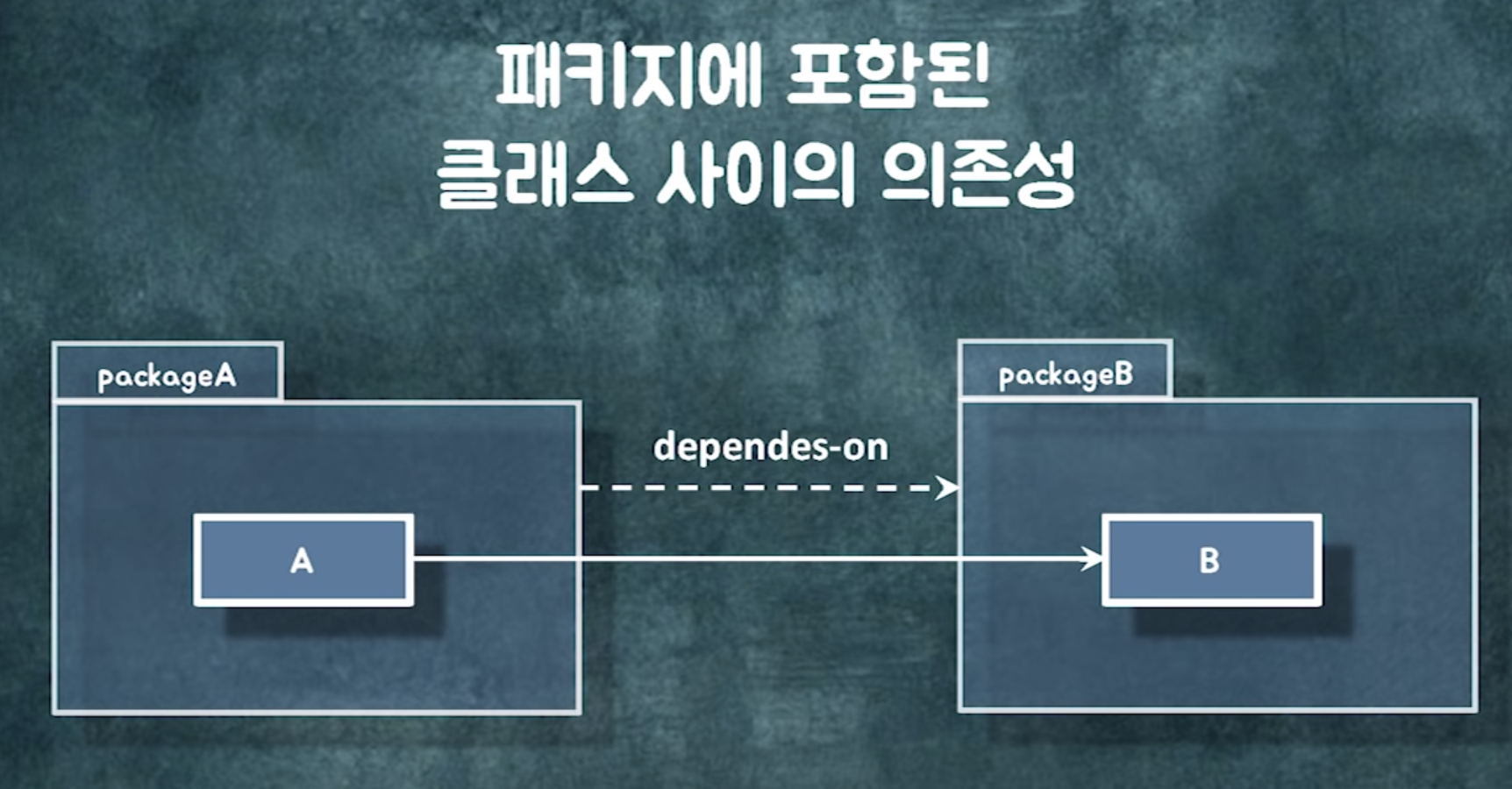
import에 따른 패키지 있으면 의존성 있는 거임
3. 의존성을 잘 관리하기 위한 몇가지 규칙
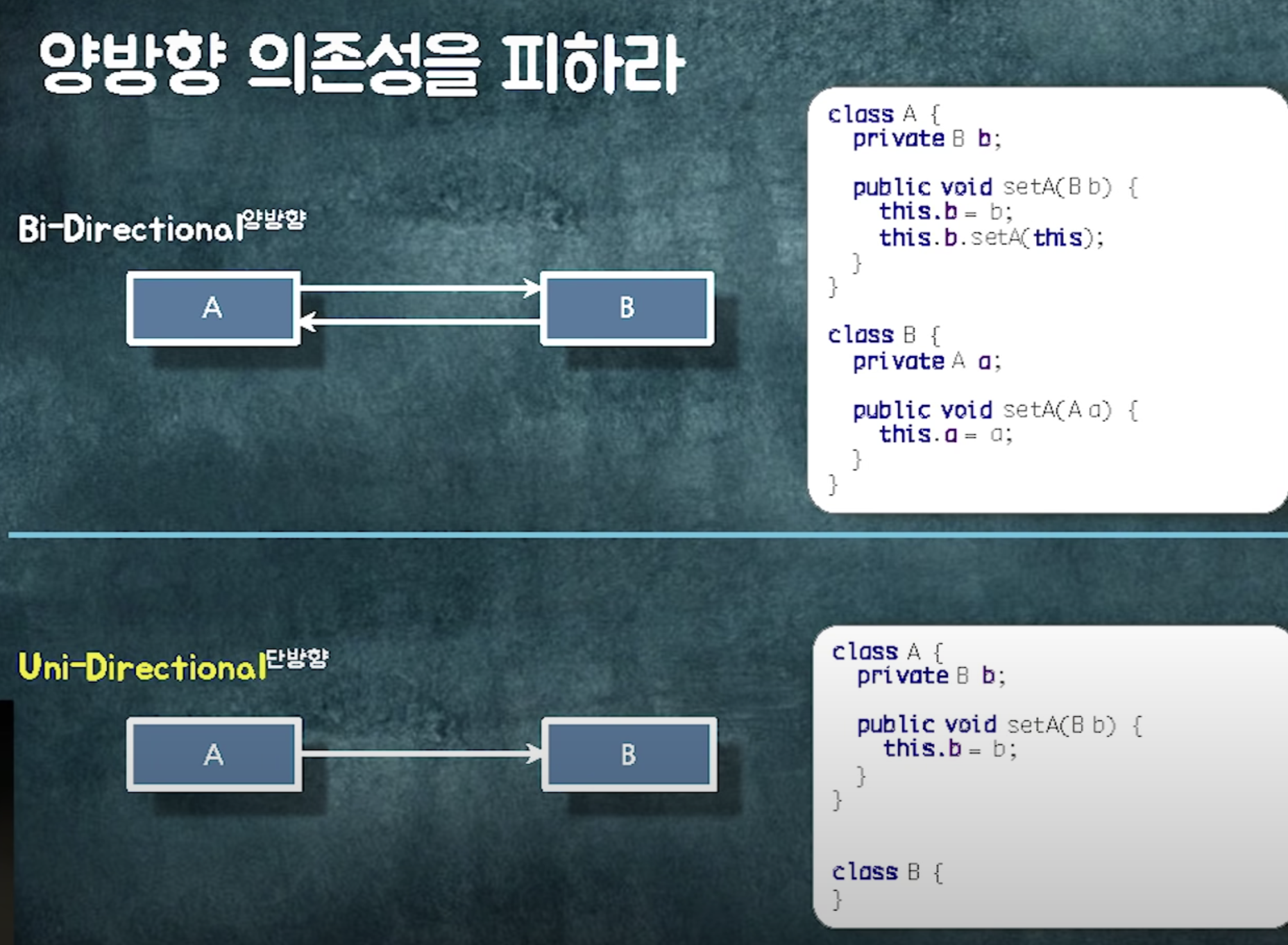
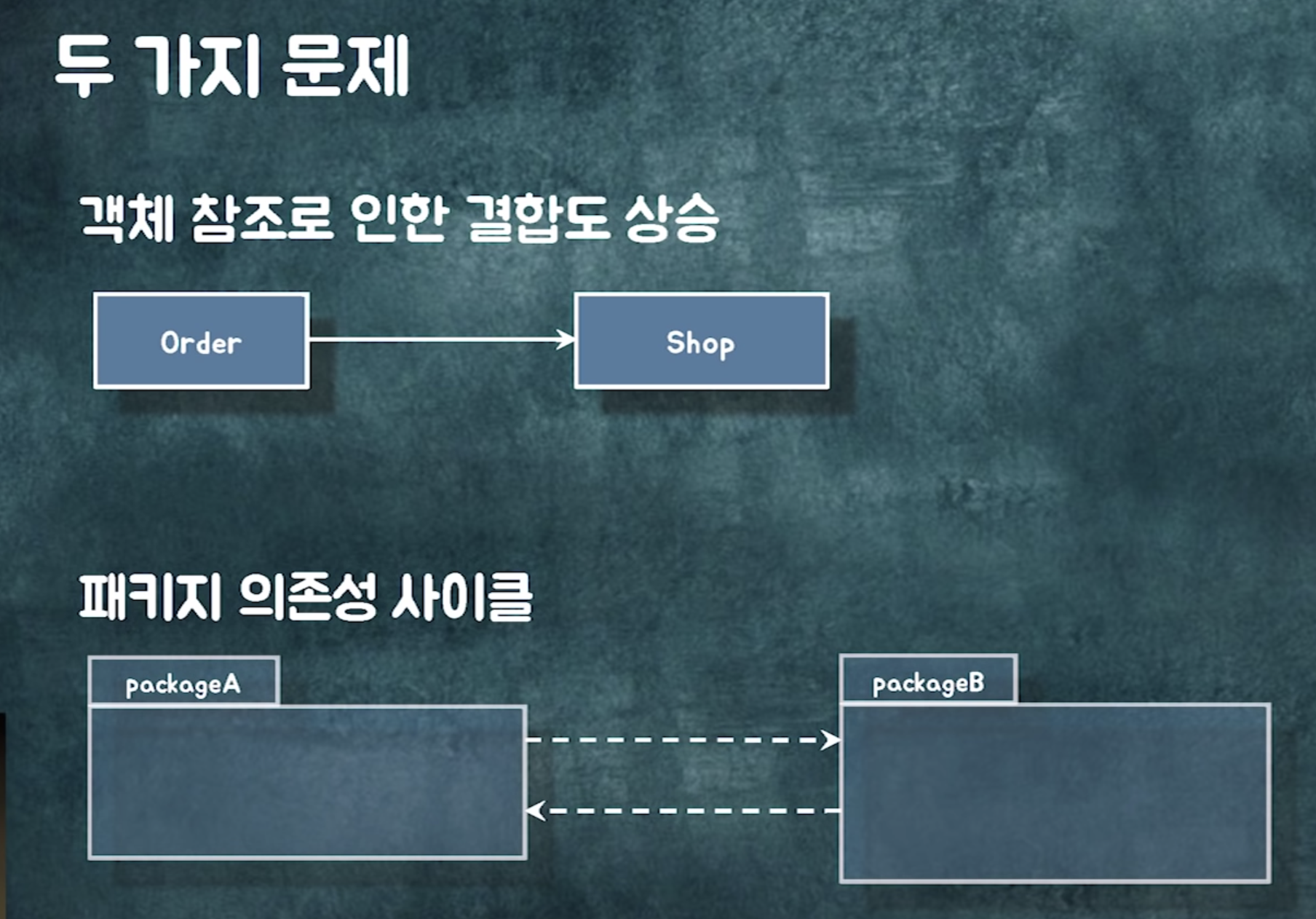
양방향 의존성이 생긴다는거 자체가, 두 클래스가 사실 하나의 클래스여야하는데 어거지로 찢어놓은 것
최대한 양방향 안생기게 노력해야함
컬렉션을 필드로 가지면 다양한 문제 발생
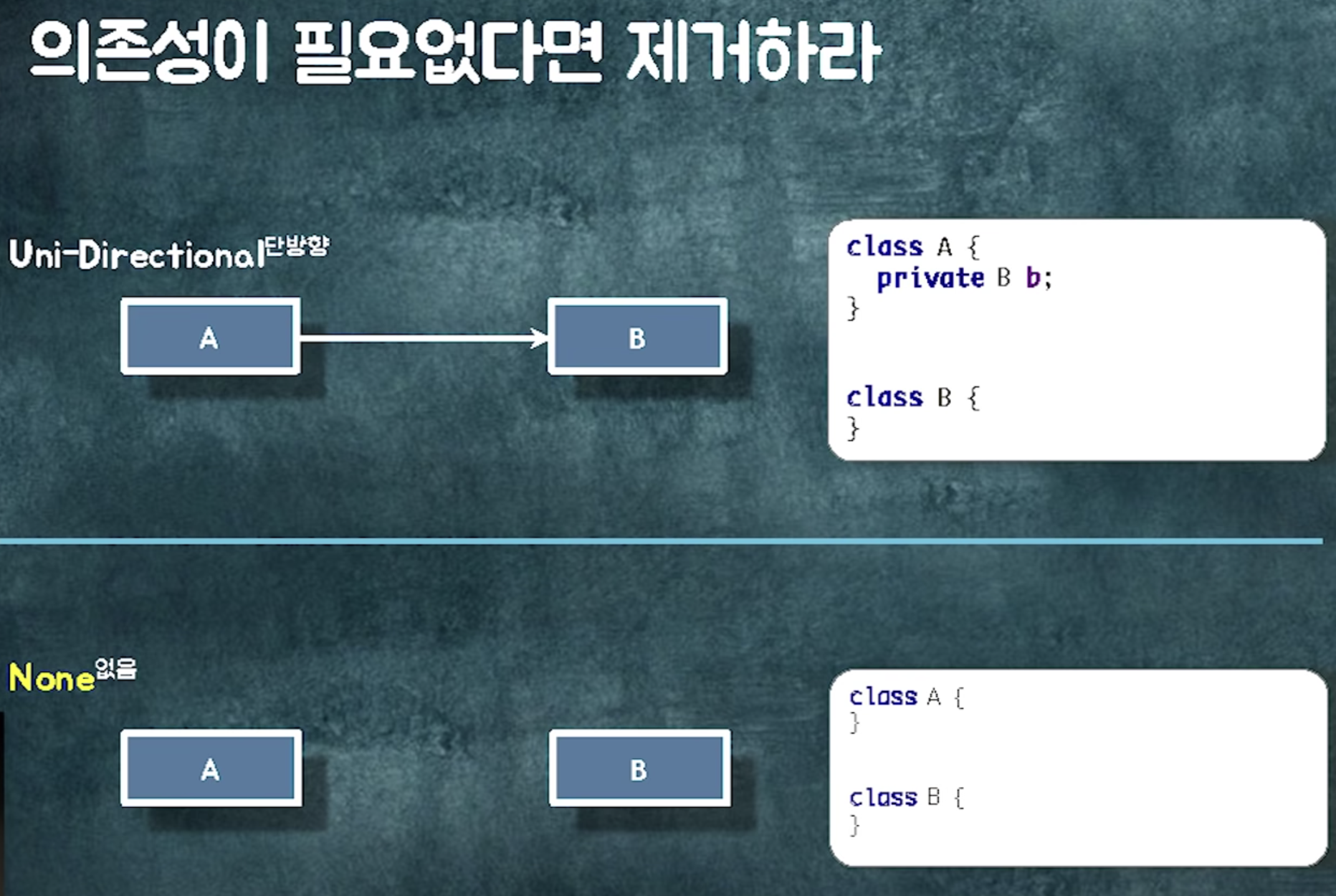
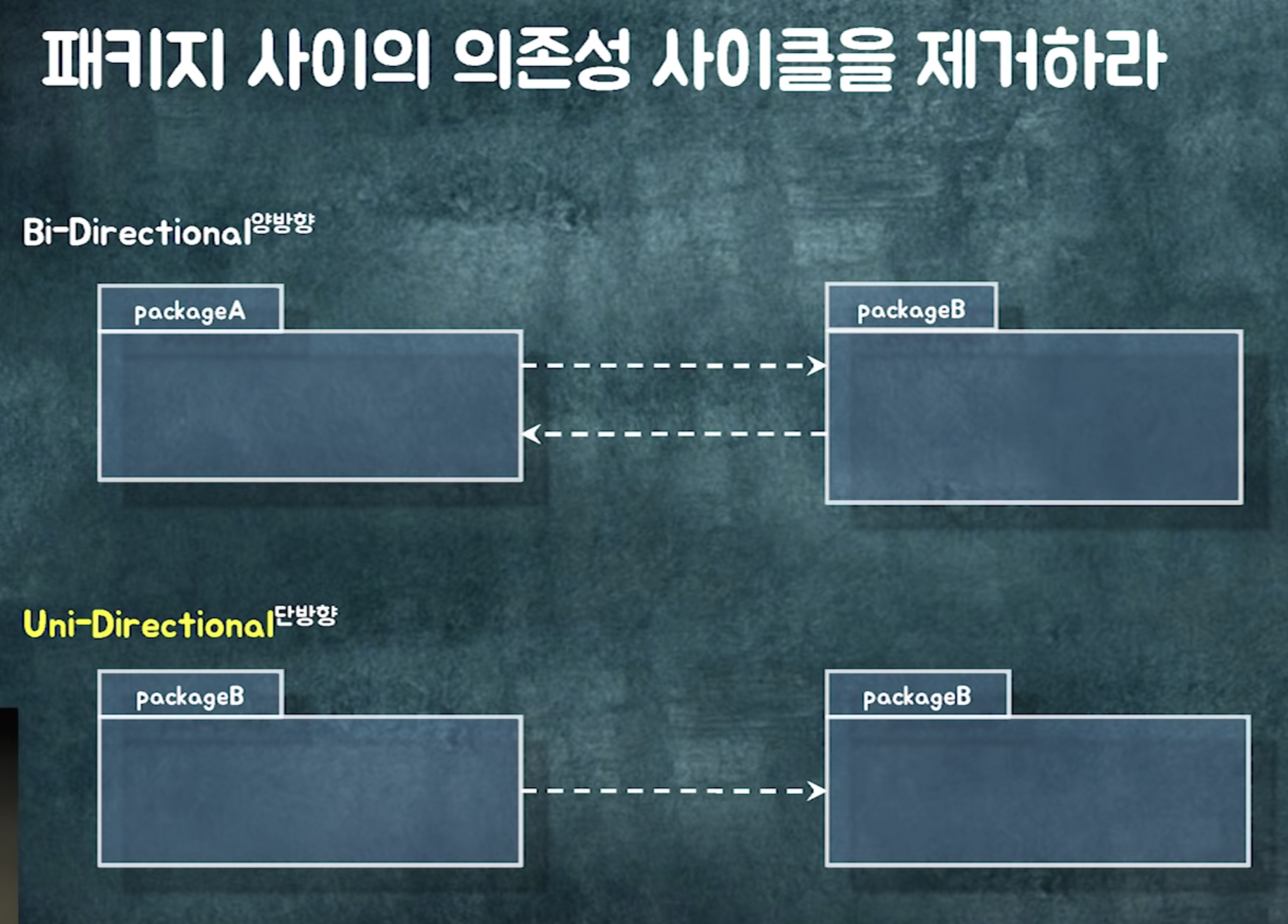
📍 예제 살펴보기
관계(의존성)
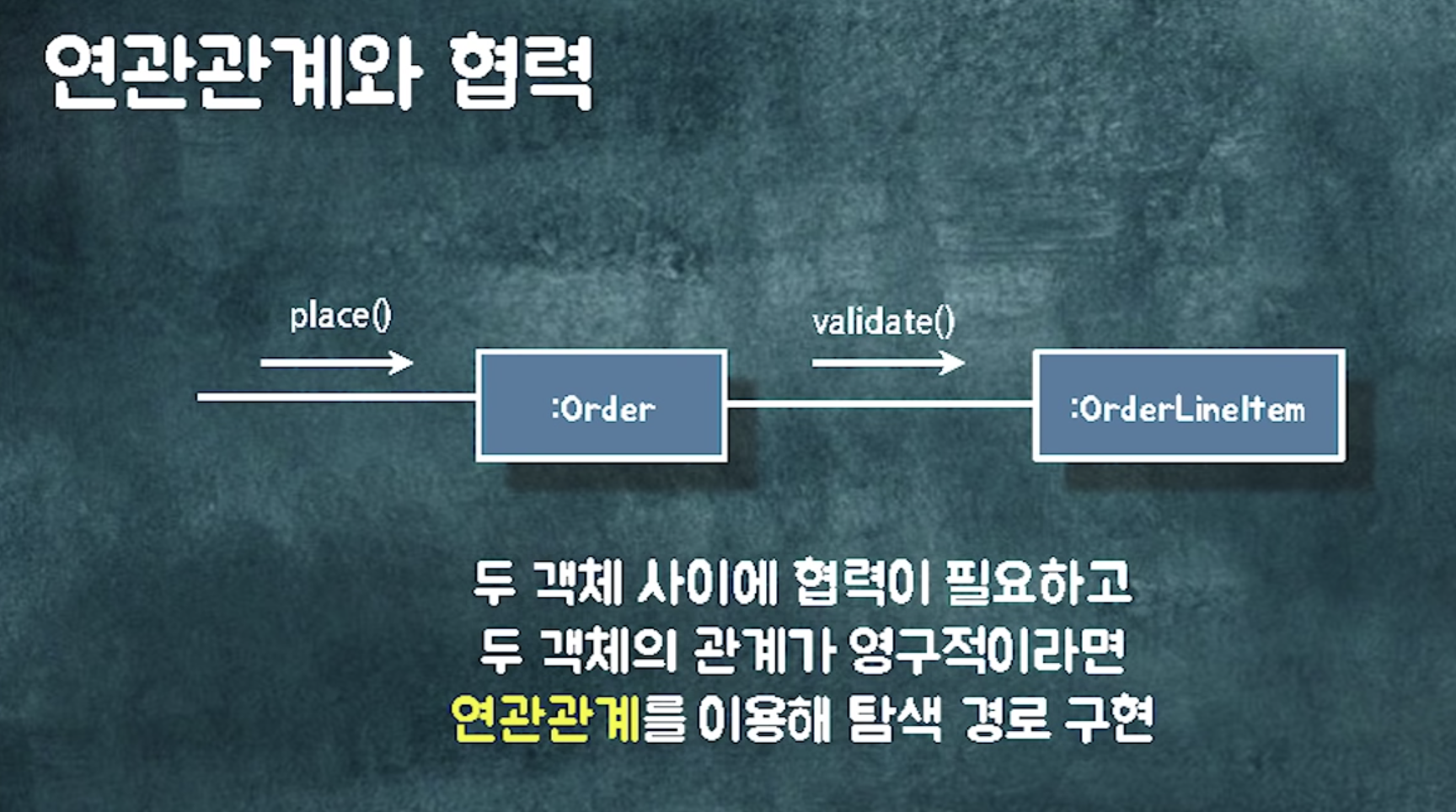
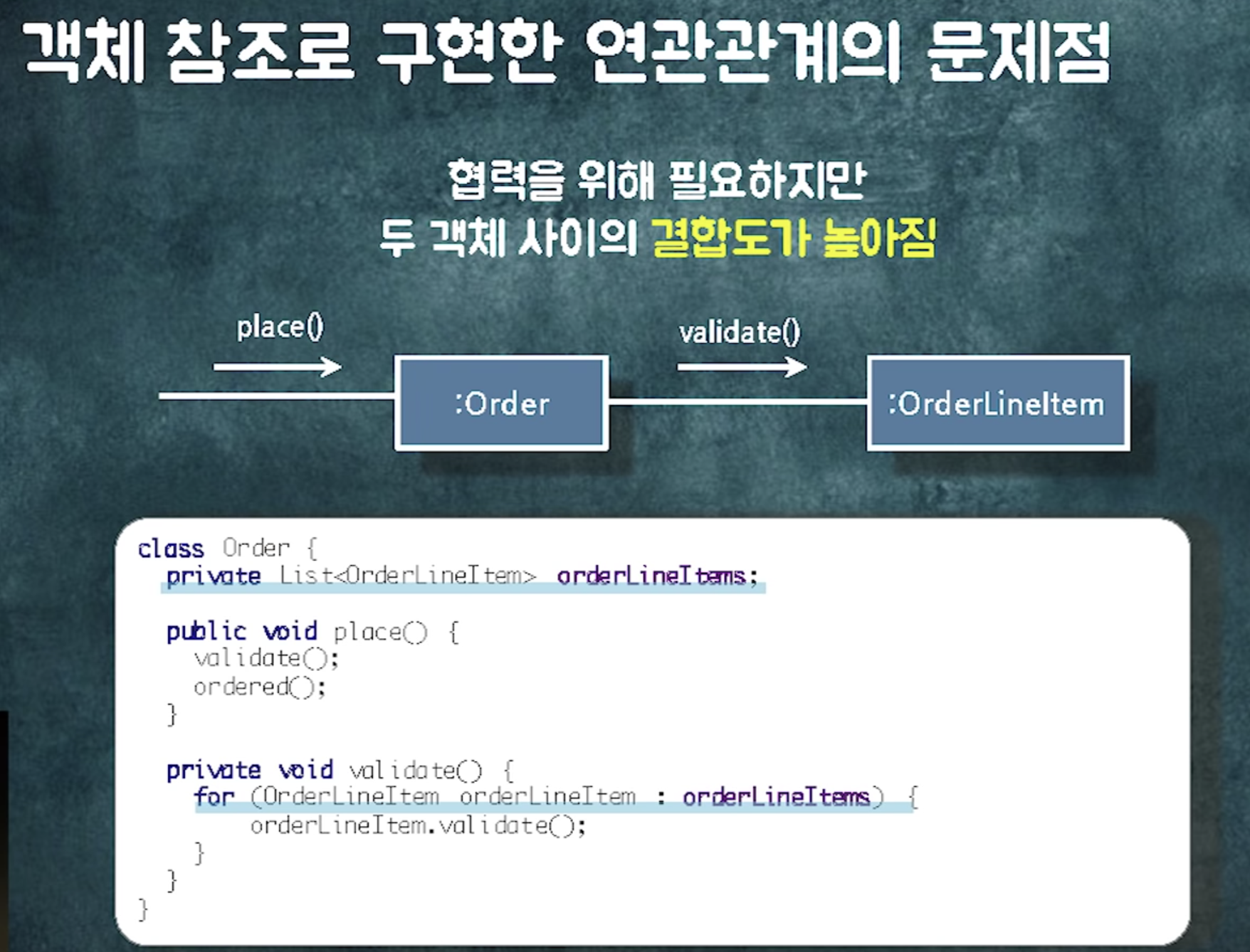
클래스와 클래스 사이의 관계가 있다 = 런타임에 a클래스의 인스턴스와 b클래스의 인스턴스가 어떤식으로든 협력한다
코드에 인스턴스 변수를 넣거나, 어떤 메소드의 파라미터에 넣는 것=a타입의 객체와 b타입의 객체는 런타임에 협력할것이다
관계는 방향성이 있어야한다!!!
객체는 방향성이 존재 (<-> db는 방향성 없음. fk하나 잡아놓으면 다 갈 수 있다)
=> 방향성을 결정하는 것이 중요!!! => 런타임에 객체들이 어떤식으로 협력하는지 보고 결정 (a객체가 b객체한테 메시지를 보내야해)
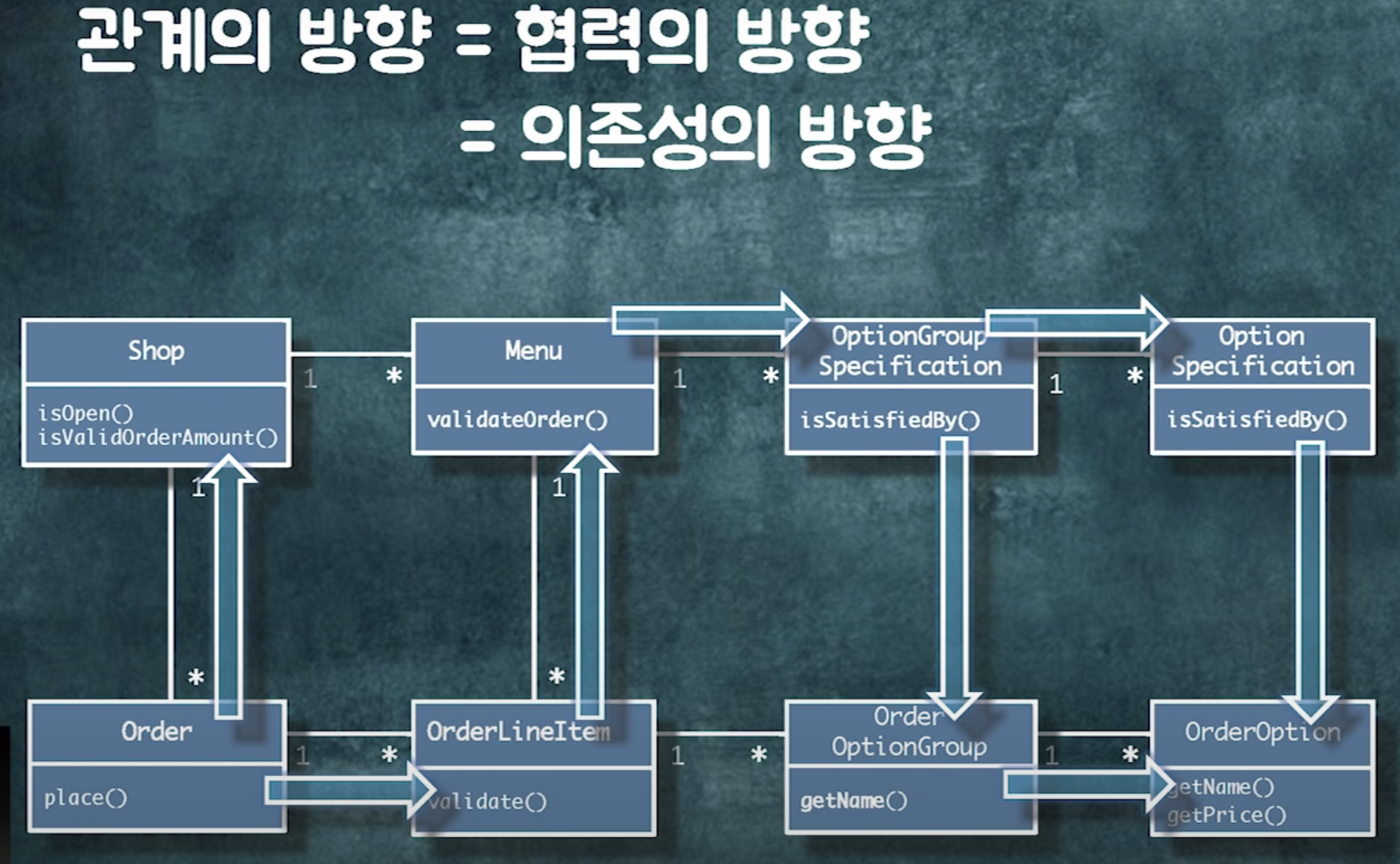
관계의 종류 결정하기
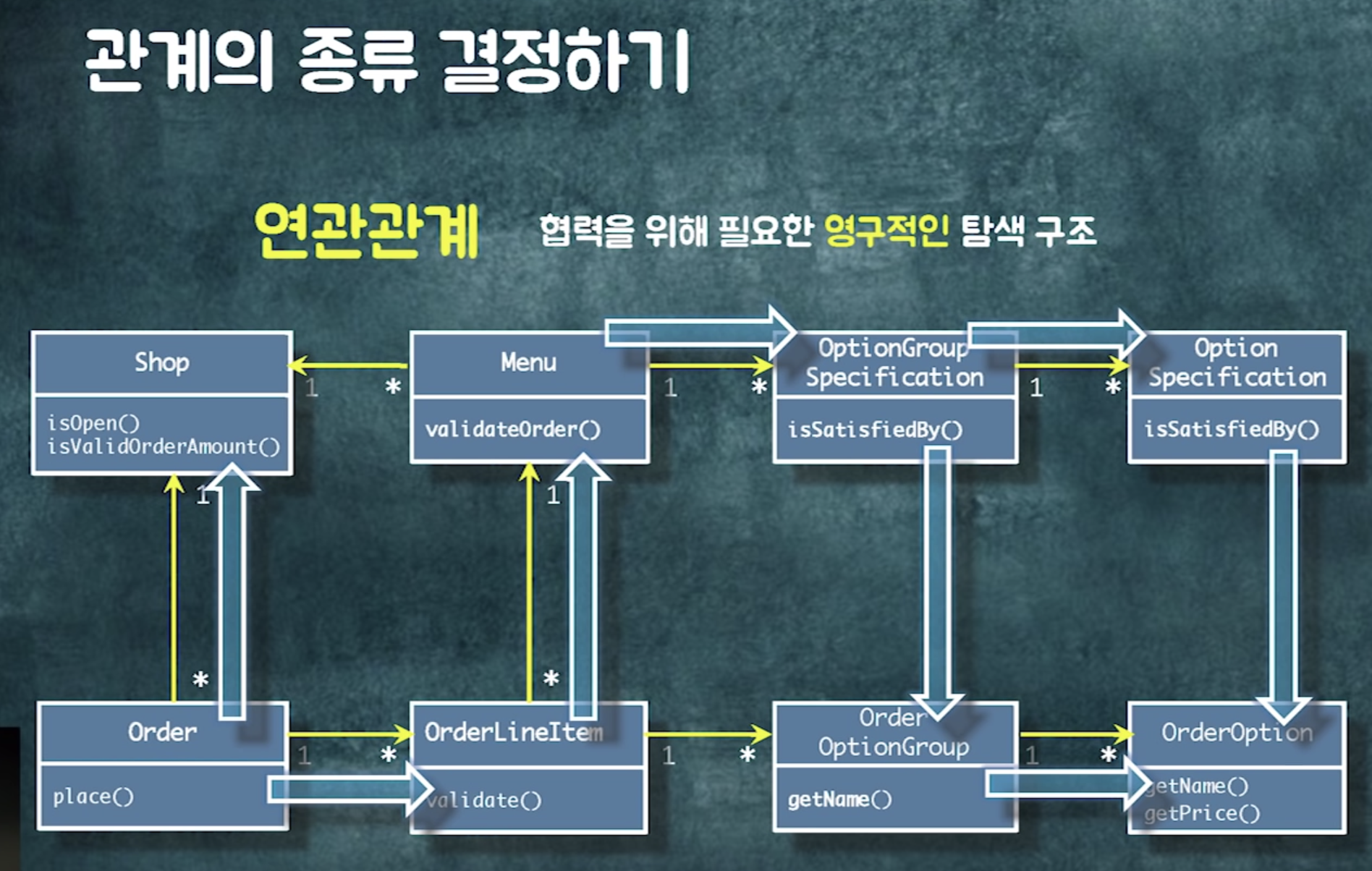
협력을 위해 객체 사이의 영구적인 탐색 구조를 잡아야 할 때 (탐색이 빈번하게 발생할 때)
원칙은 그런데.. 개발하다보면
데이터 구조에 영향을 받음.
데이터의 흐름을 따라감
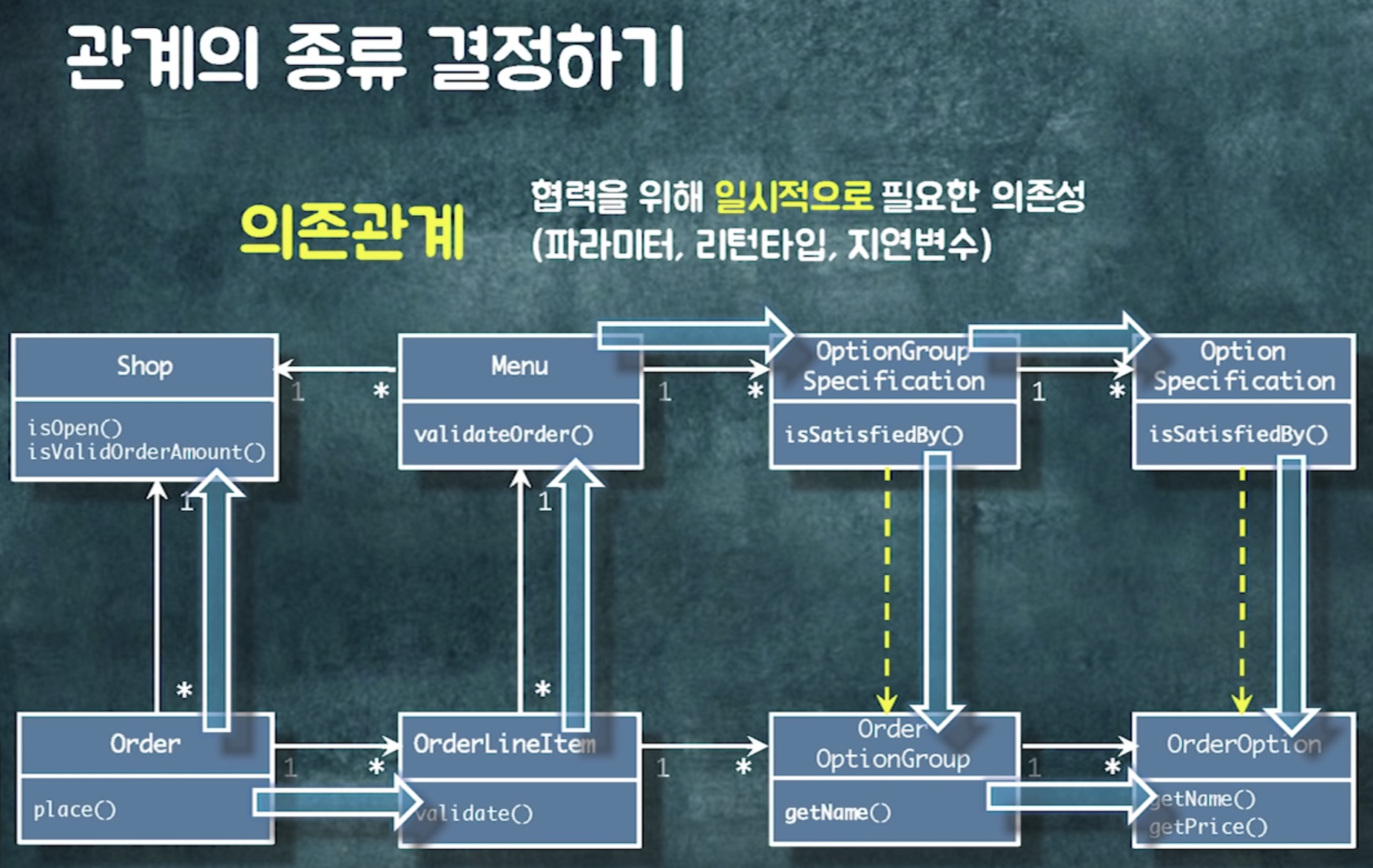
관계의 종류보다는 관계의 방향성이 중요.
내가 뭔가를 참조할 때는 항상 이유가 있어야함.
(내가 연관관계 또는 의존관계를 넣는 이유가 있어야함. 그리고 이건 런타임에 객체들이 어떤식으로 협력하느냐에 따라 달라짐)
두 객체간 통로가 영구적으로 유지되어야 하는 판단 근거가 있으면 연관관계 사용
연관관계는 개념. 객체참조는 구현방법.
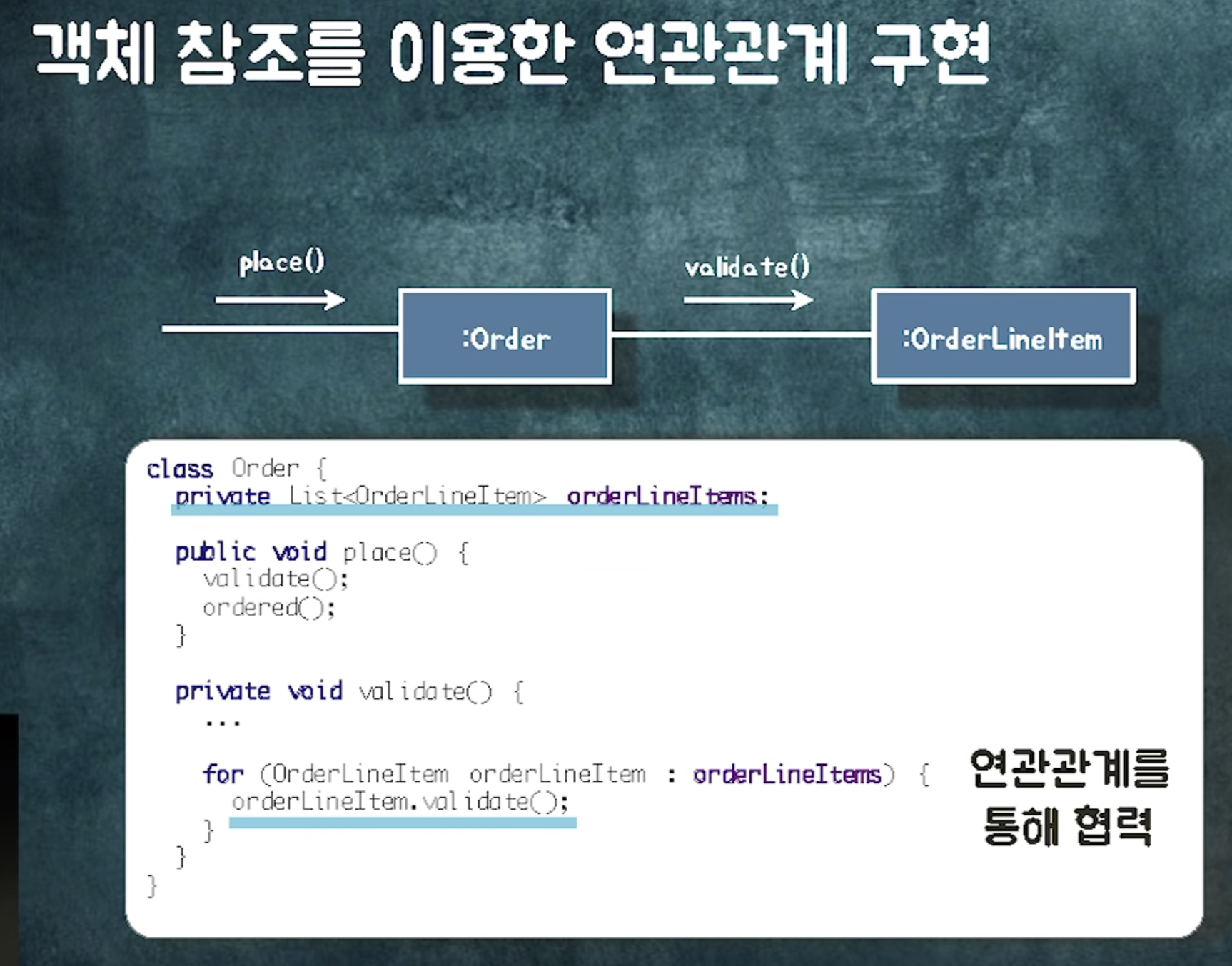
-> 연관관계를 구현할 수 있는 방법 중 하나가 객체참조

어떤 객체가 어떤 메시지를 받는다 = 그 객체의 public 메소드로 구현
(메시지를 받아야하기 때문에 메소드를 구현. 메시지를 결정하고 메소드를 만들어야함!!)

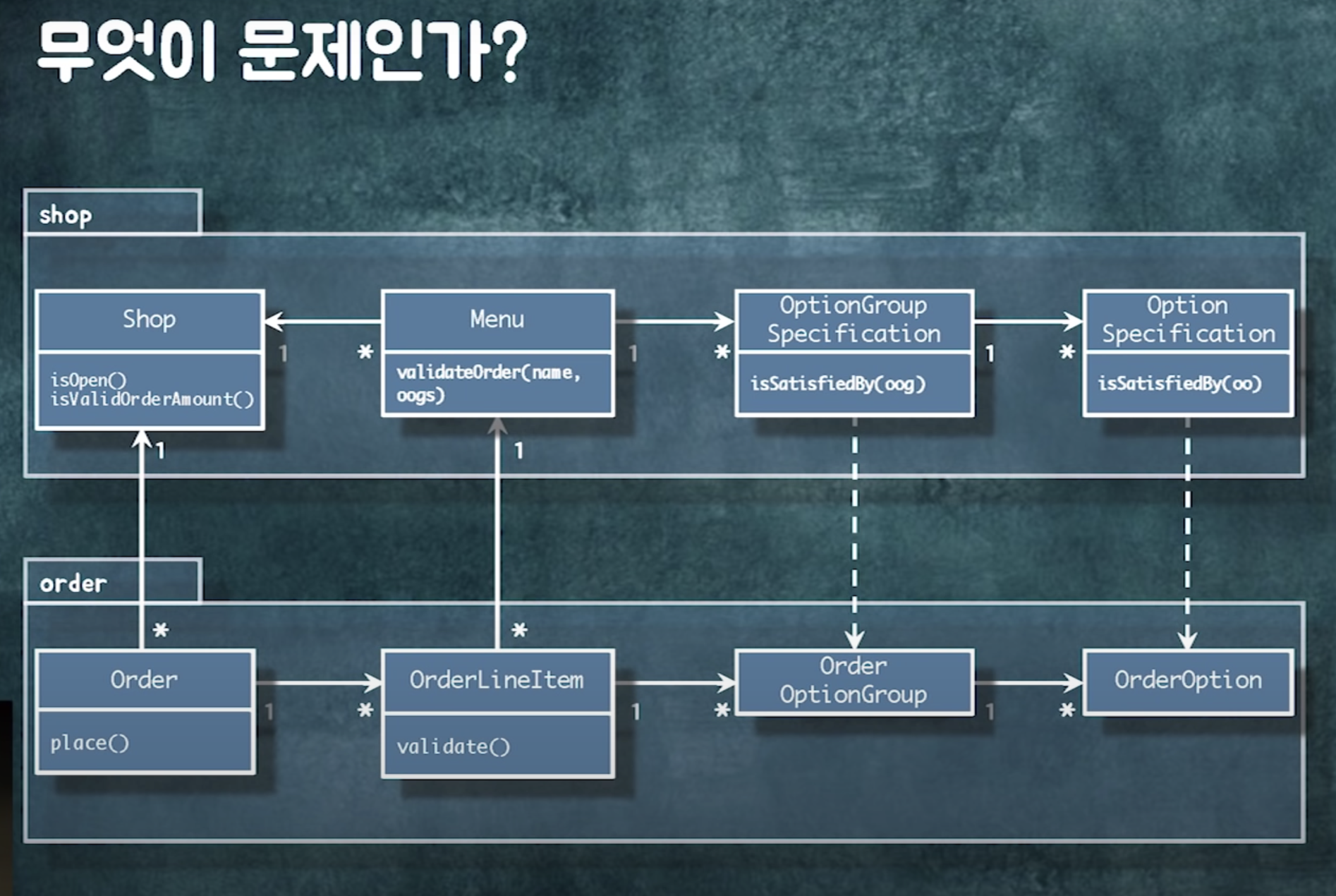
order라는 객체가 shop과 orderlineitem으로 이동할 수 있어야함.
order가 두 객체에게 메시지를 보낼 수 있어야함
영구적인 관계. 왜? 주문은 항상 어떤 가게의 주문. 항상 주문항목이 있다.
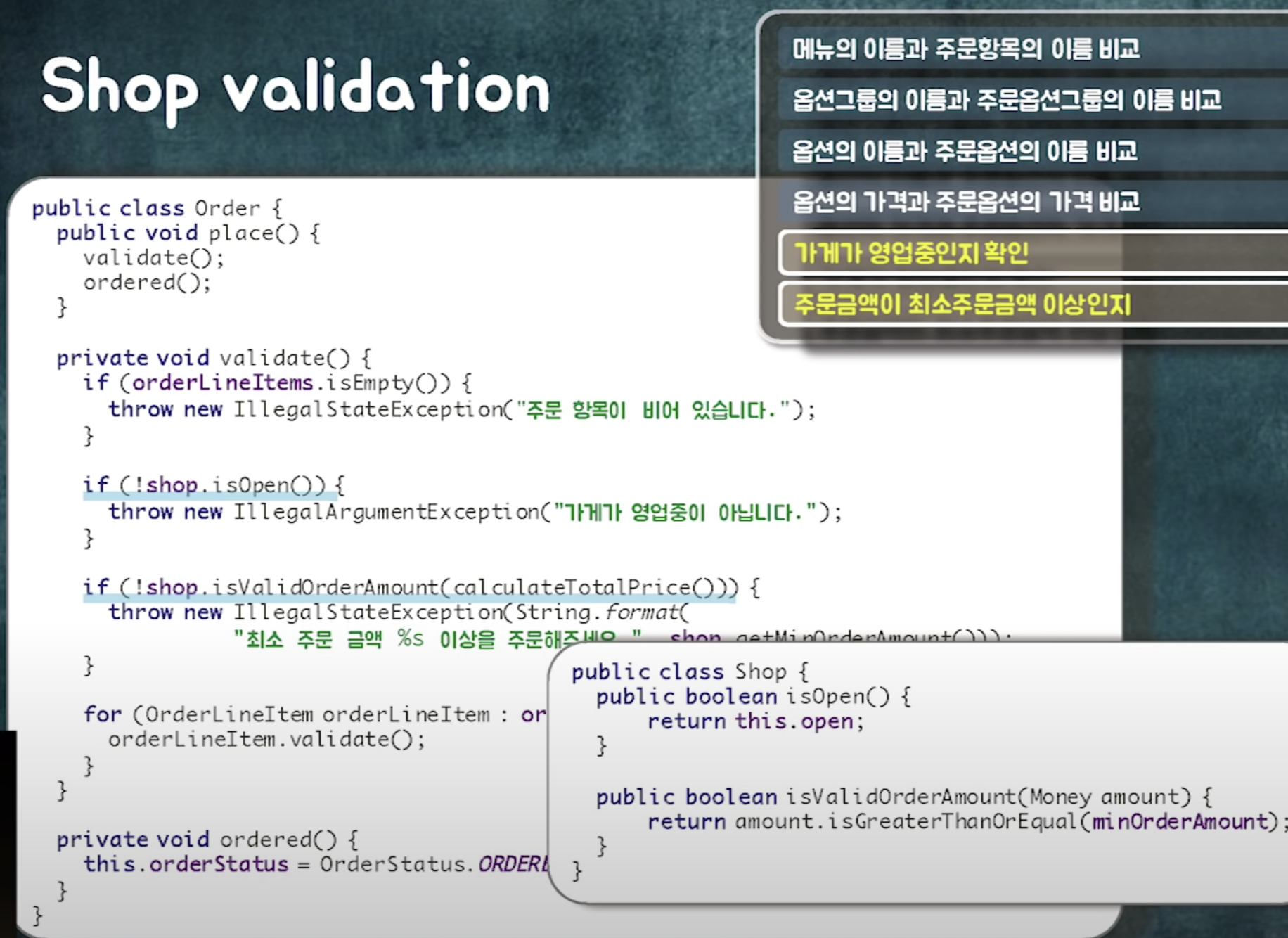
주문 항목 등의 데이터가 바뀌지 않았는지 검증
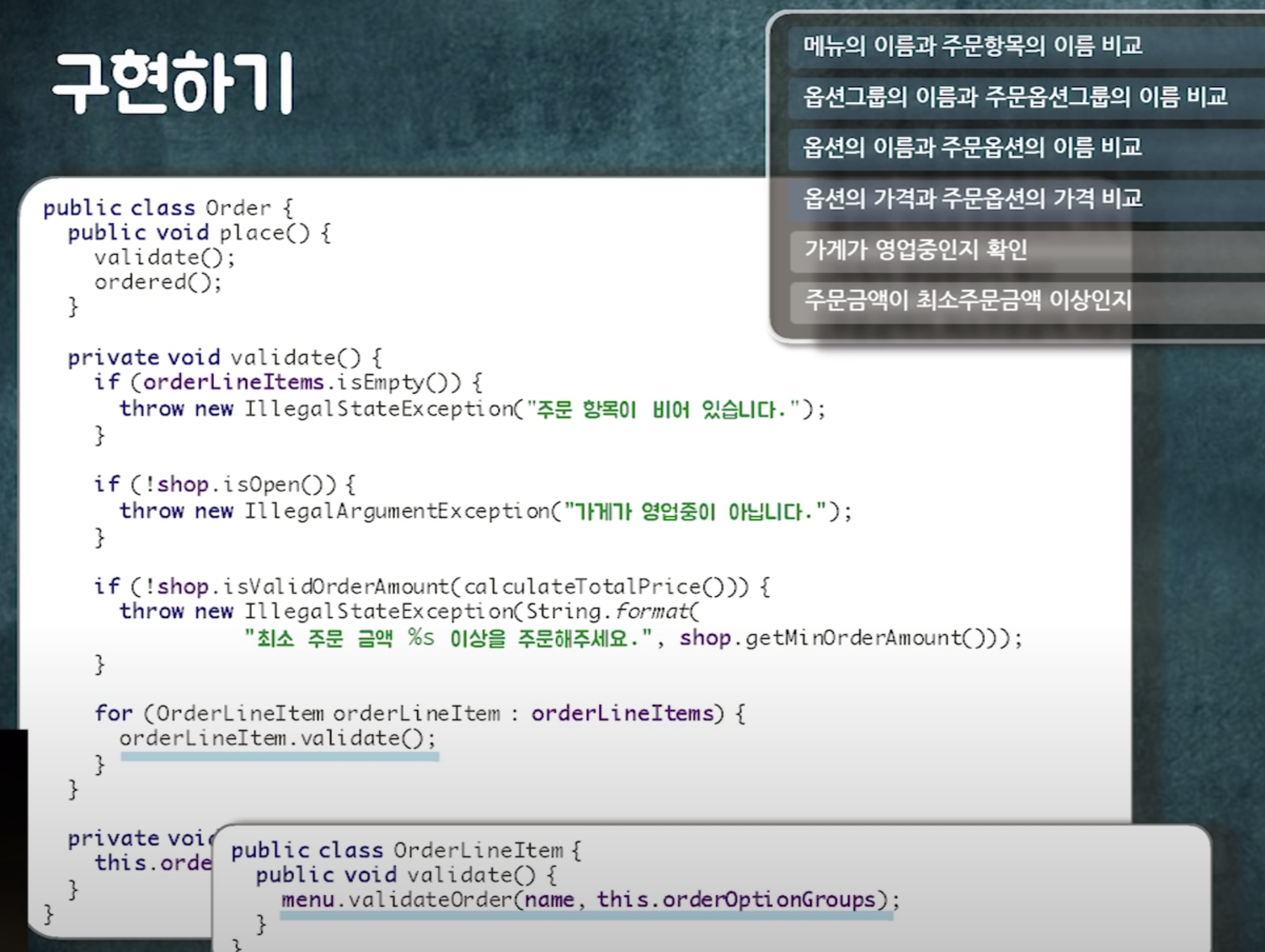
도메인(비즈니스 로직) 구현
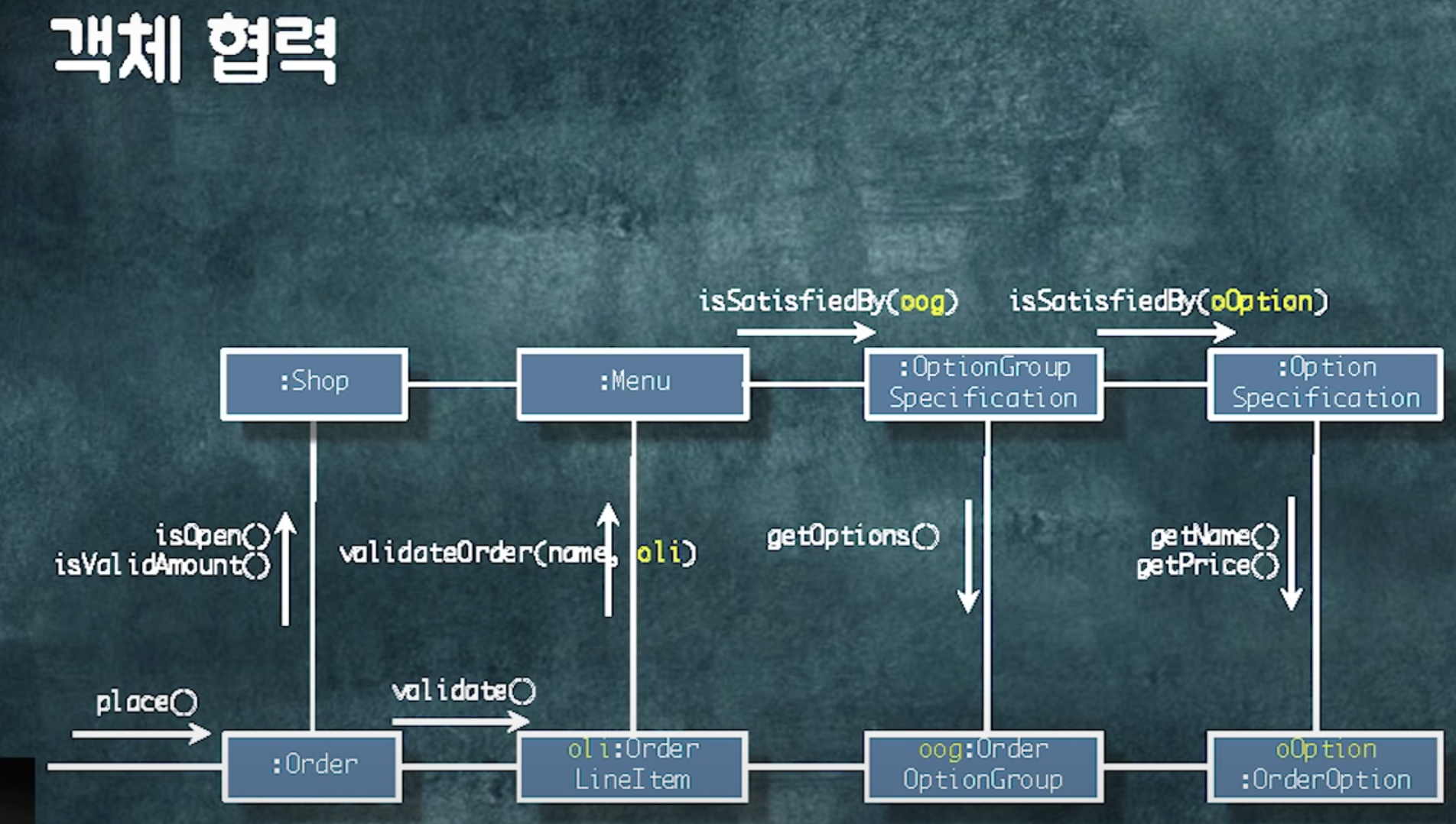
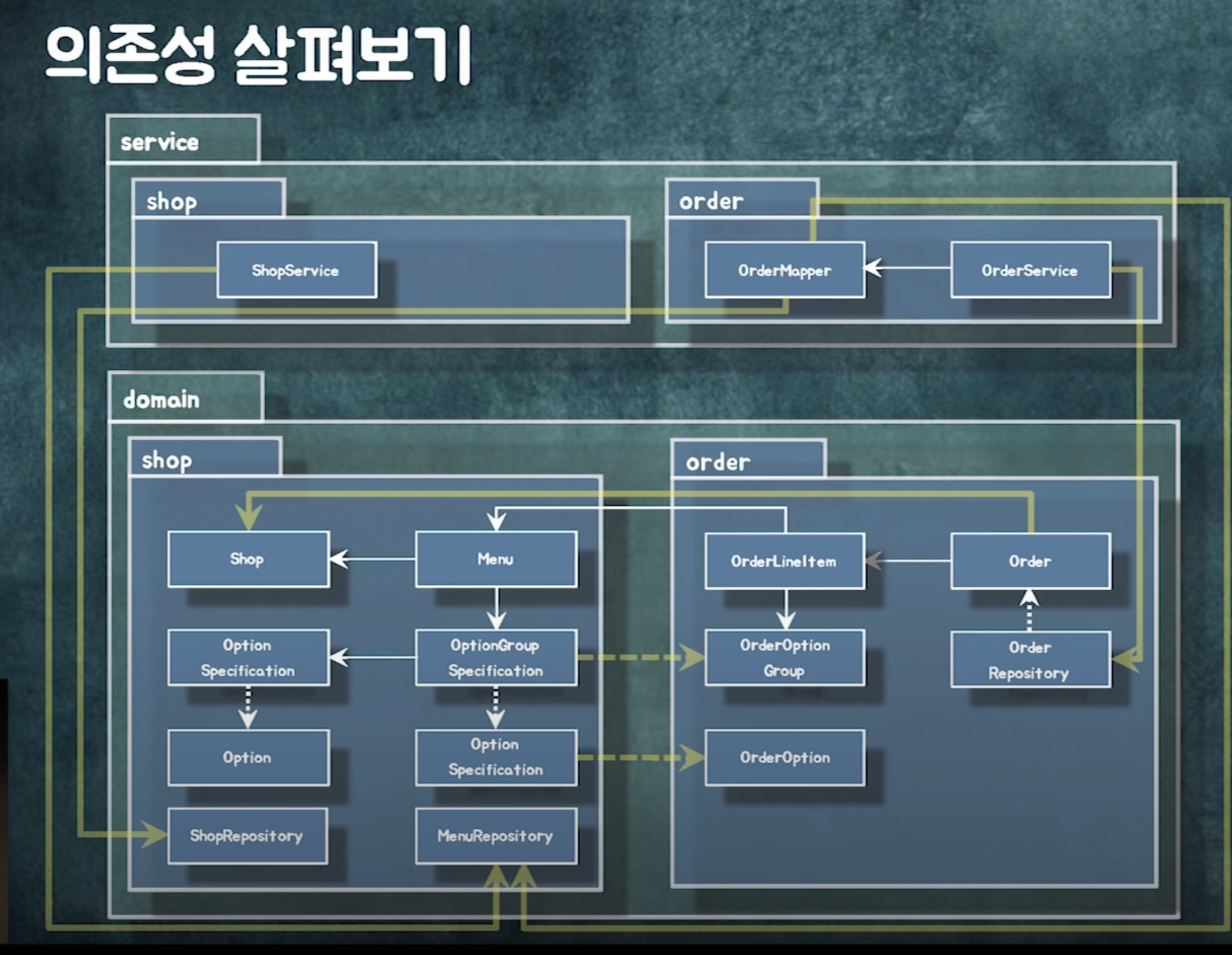
📍 설계 개선하기
설계 개선 : 객체들의 협력 관계나 이 메소드가 그 객체에 있는게 맞아?등을 확인하는 것
dependency가 어떻게 되는지 종이에 그려가며 확인

일단 짜고 dependency를 보며 개선하면 내가 원하는 구조로 나아감
1
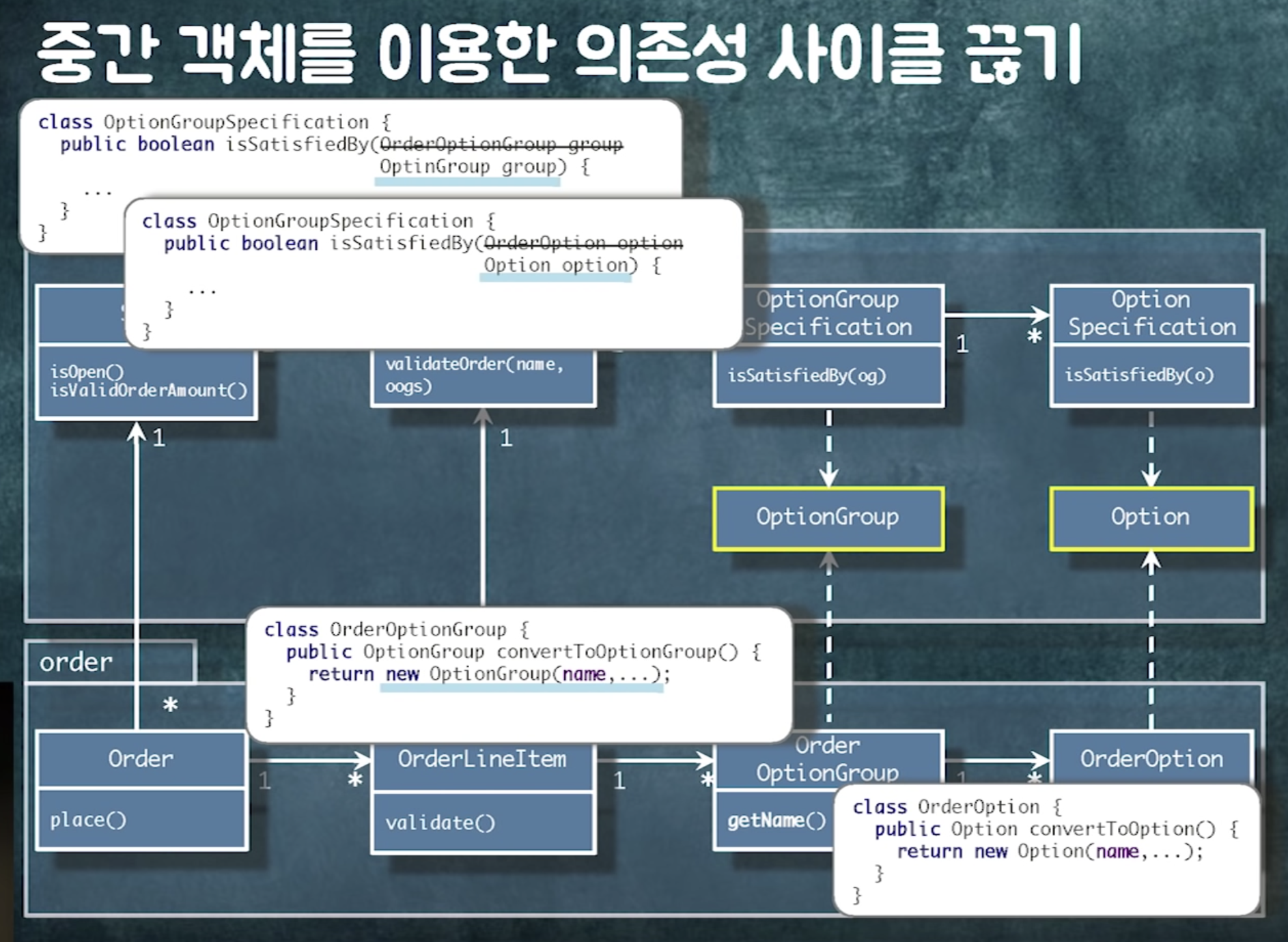
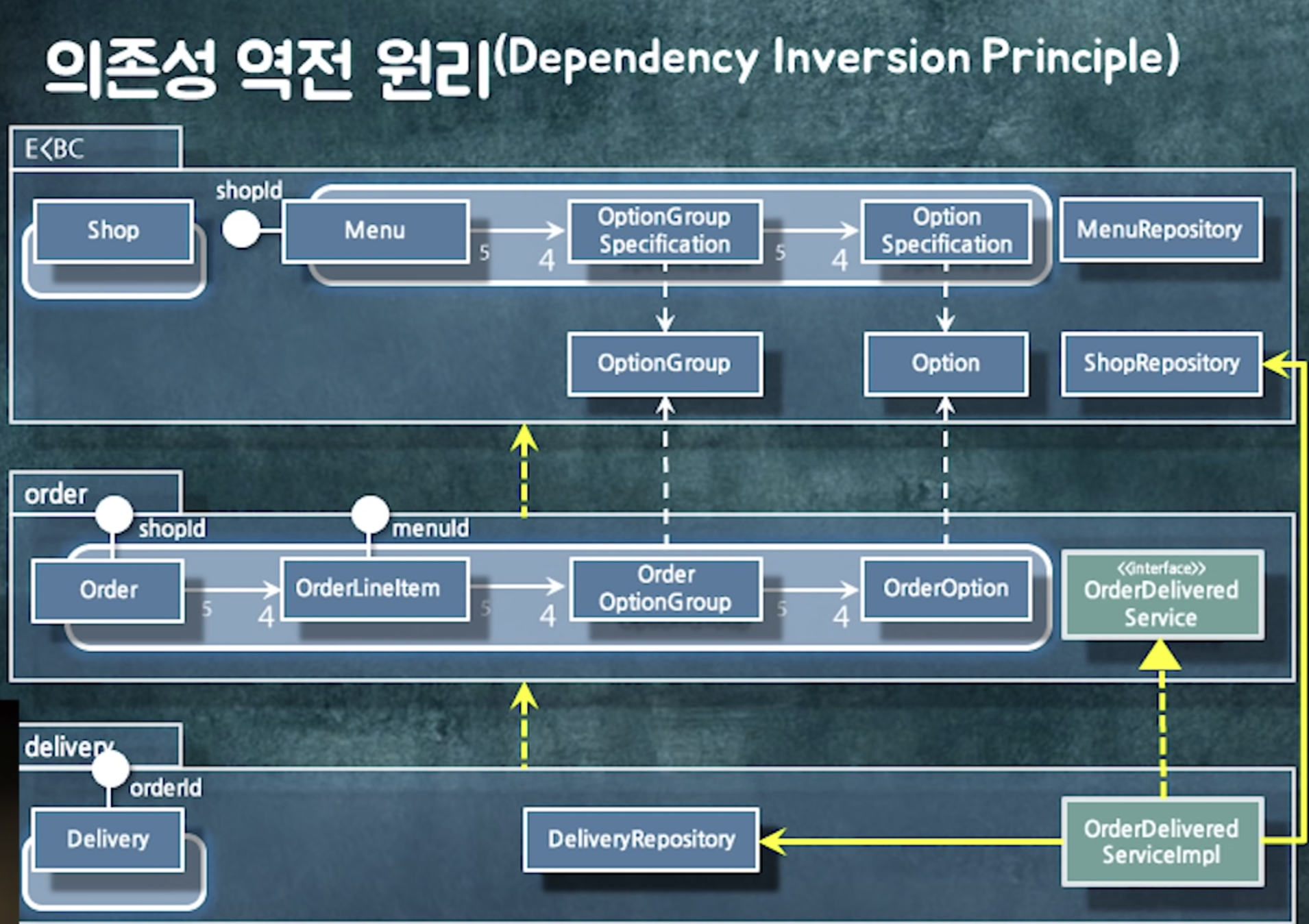
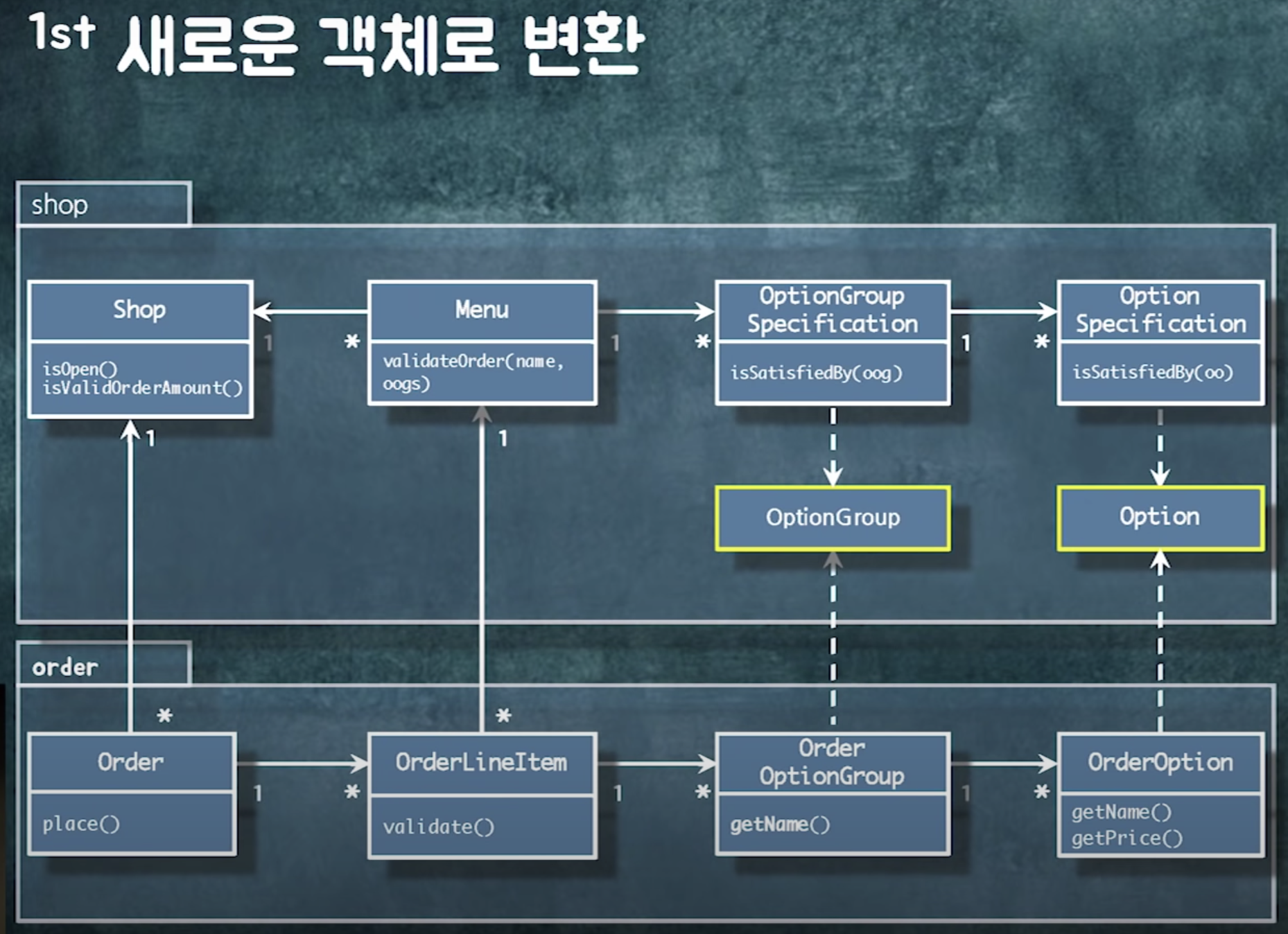
의존성 역전 원칙 : 구체적인 것보다 추상적인 것에 의존
추상화는 인터페이스나 추상클래스만이 아님. 추상화란 잘 변하지 않는 것. (a에 비해 b는 잘 변하지 않아 -> b는 추상적인 것)
optionGroup과 option은 필요한 데이터만 딱 갖고 있다. (잘 바뀌지 않음) -> 추상화 한 것
예를 들어 이렇게 해두면 order뿐만 아니라 cart속 optionGroup과 option도 동일한 로직으로 검증가능.
이렇게 의존성을 끊음으로서 재사용성이 증가.
2
연관관계란 order를 통해 orderlineitem을 찾을 수 있는 탐색 경로 제공하는 것
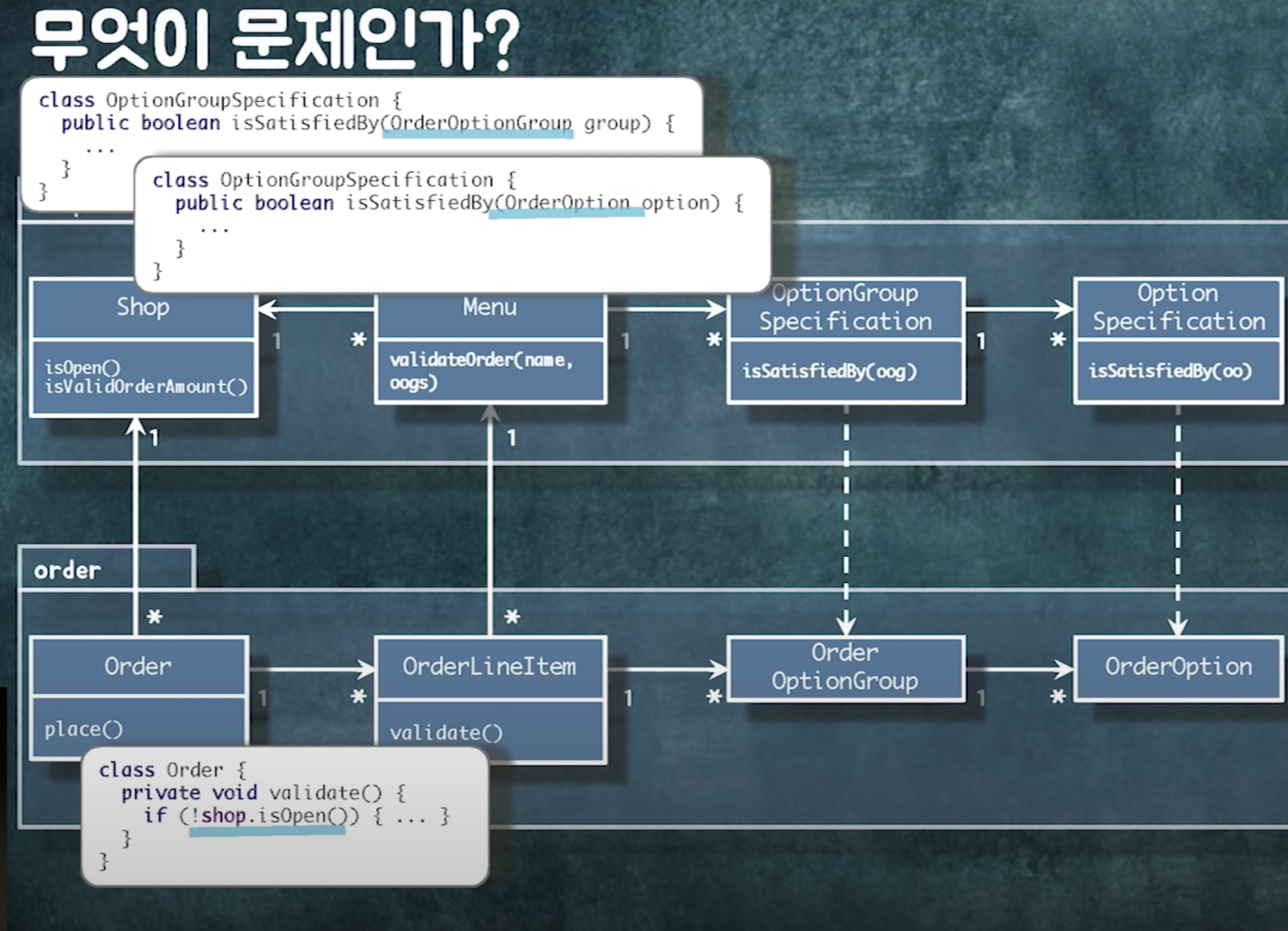
문제1)
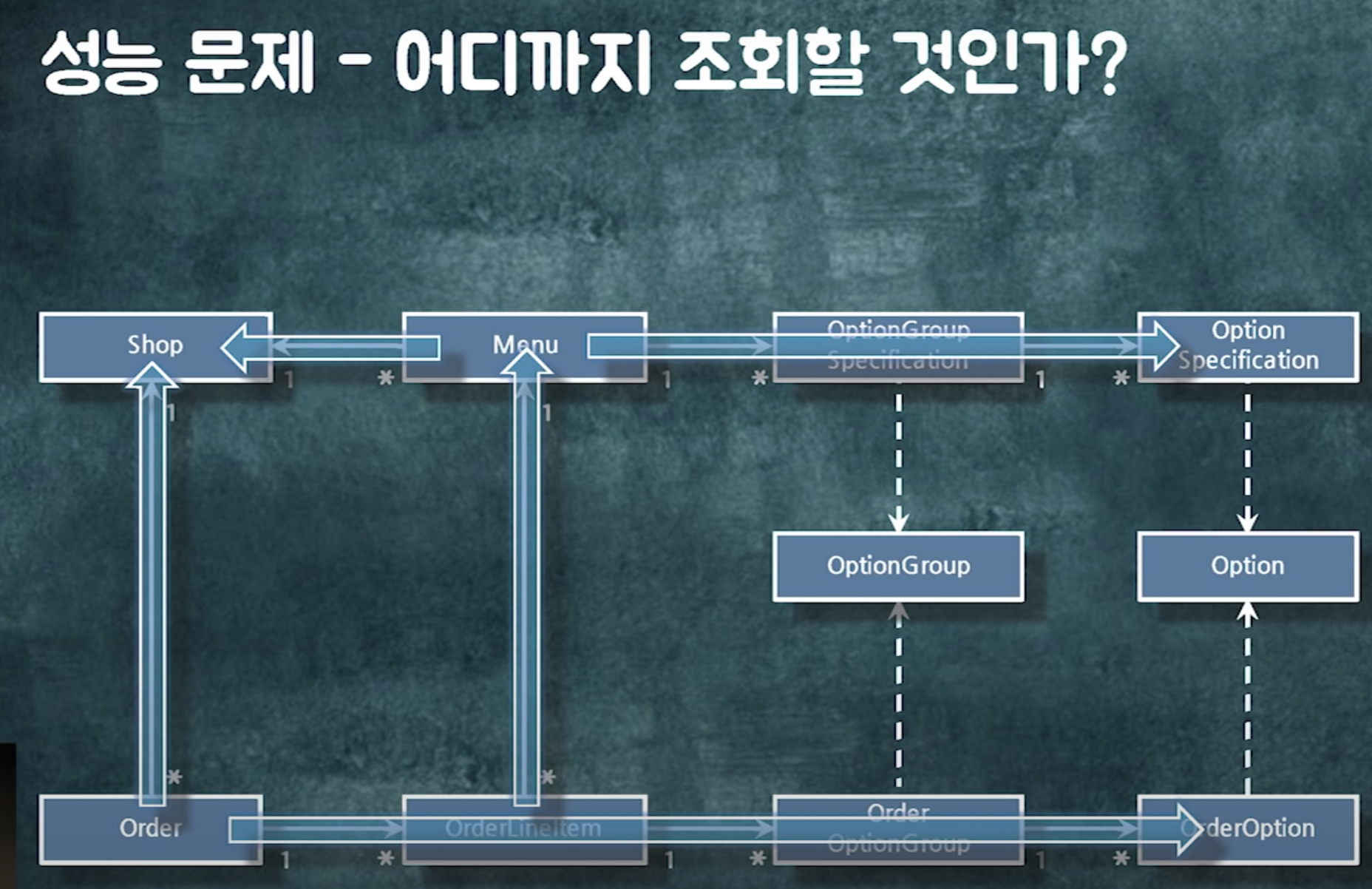

객체들이 다 연결되어 있음 -> 어디든 탐색 가능
-> 메모리상에서는 큰 이슈가 없는데, db로 매핑할 때 연관관계가 있는 순간 헬게이트 열림. 흔히 말하는 lazyloading 이슈
한번 조회하는데 관련 쿼리 쭉 나감. 어디까지 읽어야하는지?
객체가 다 연결해되어있기 때문에 어디까지 읽고 어디까지 읽지 말아야하는지에 대한 가이드가 없음
문제2)
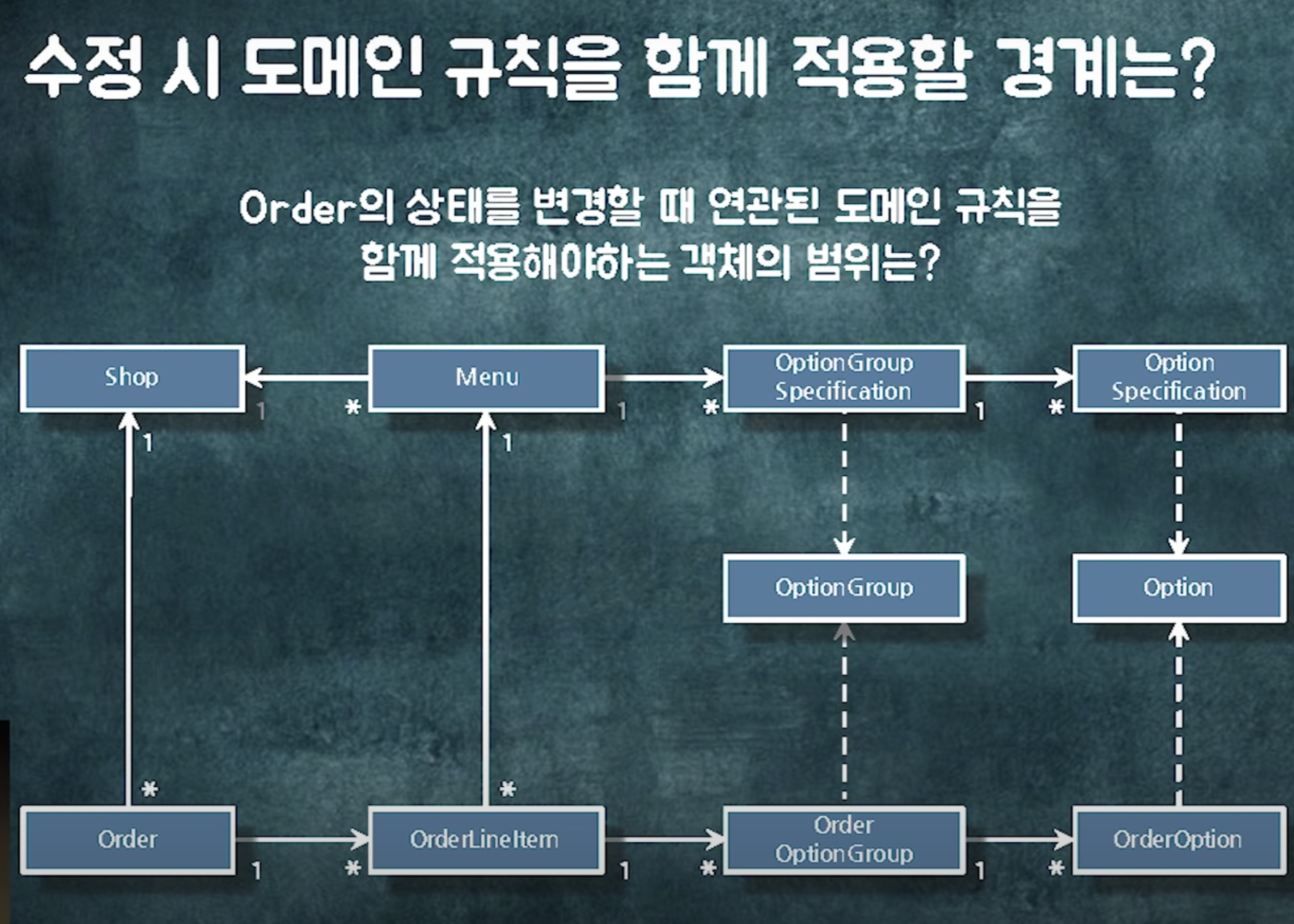
객체를 어디서부터 어디까지 수정해야해요?
order를 바꿀 때 shop도 바꾸고 orderoption도 바꾸고 등등..
order를 들고 연관관계를 통해서 다 뒤지고 다니면서 세팅. 끝. 과연?
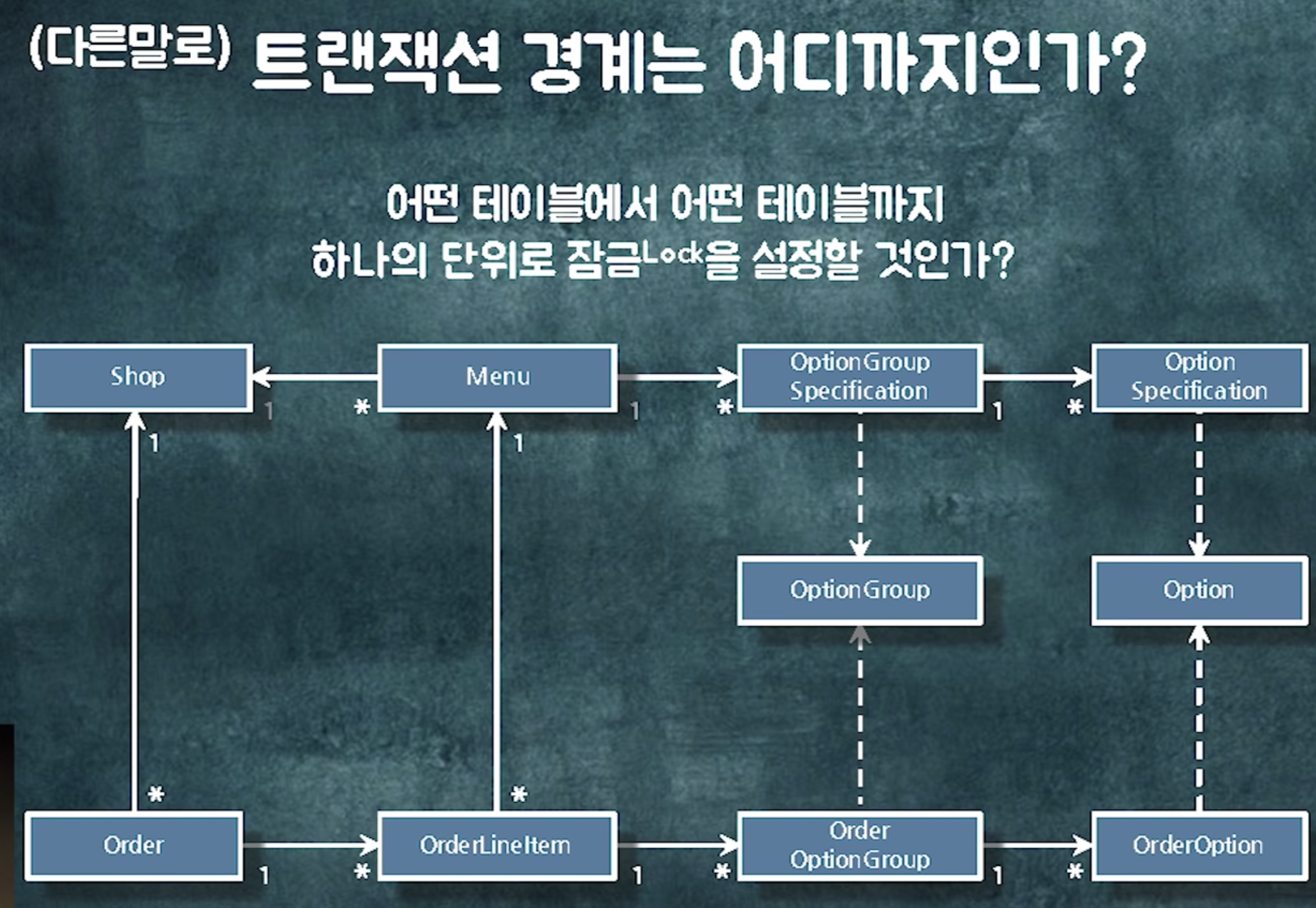
결국에는 롱 트랜잭션으로 물림.
-> 객체 참조를 통해 수정하고 있는 모든 것들이 하나의 트랜잭션으로 가버림 -> 트랜잭션의 경계가 모호해짐 -> 성능이슈 발생
객체참조는 성능 이슈를 놓치게 만듦. 연결되어있으니 걍 가면돼~ 저 객체를 같이 읽거나 수정하고 싶은데 객체 참조가 없네. 인스턴스 변수로 넣어버려~ 같은 의사결정을 쉽게 내리게 됨. -> 요구사항이 추가될 수록 트랜잭션이 점점 길어짐
주문 완료 되면 결제해야함~~
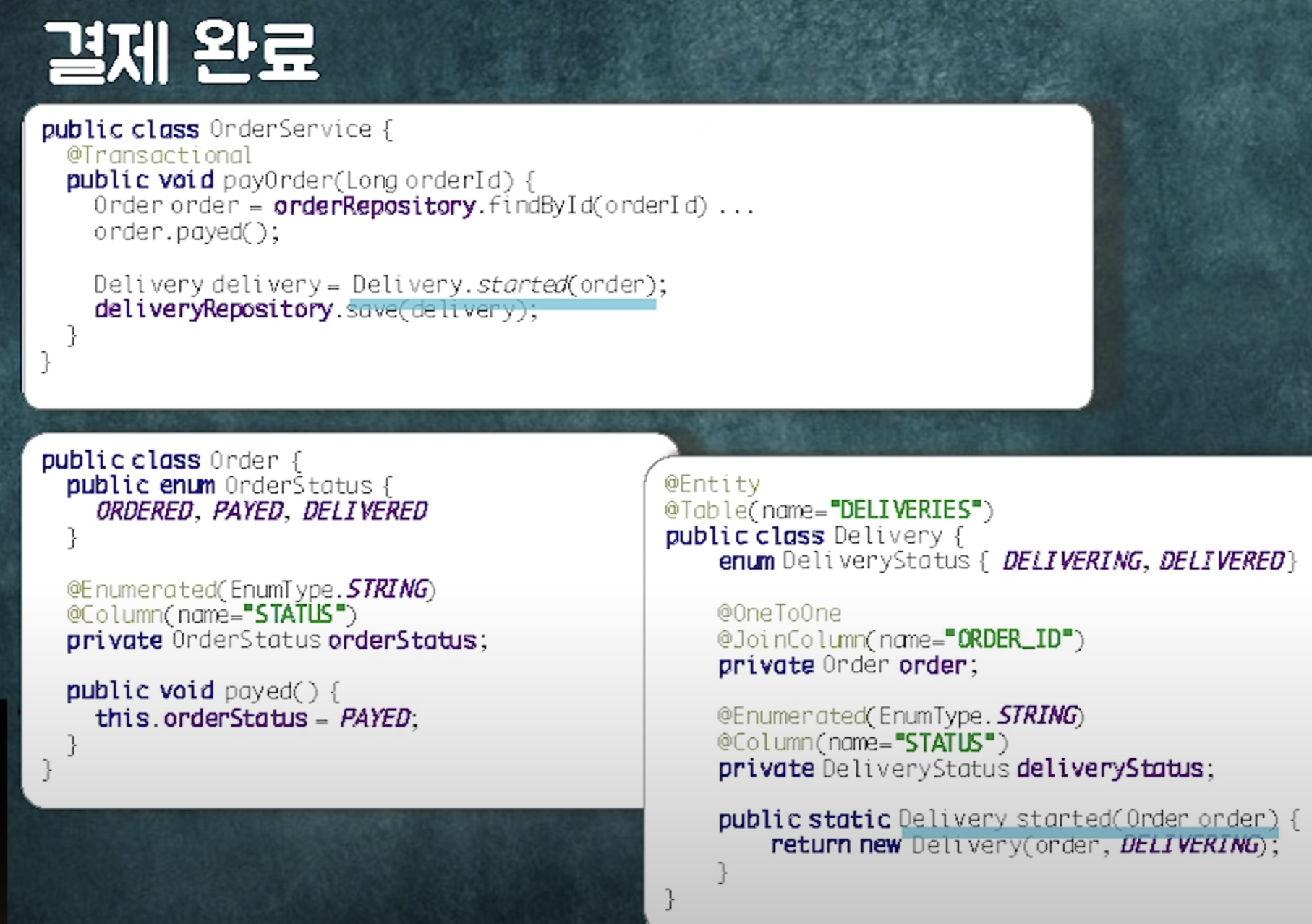

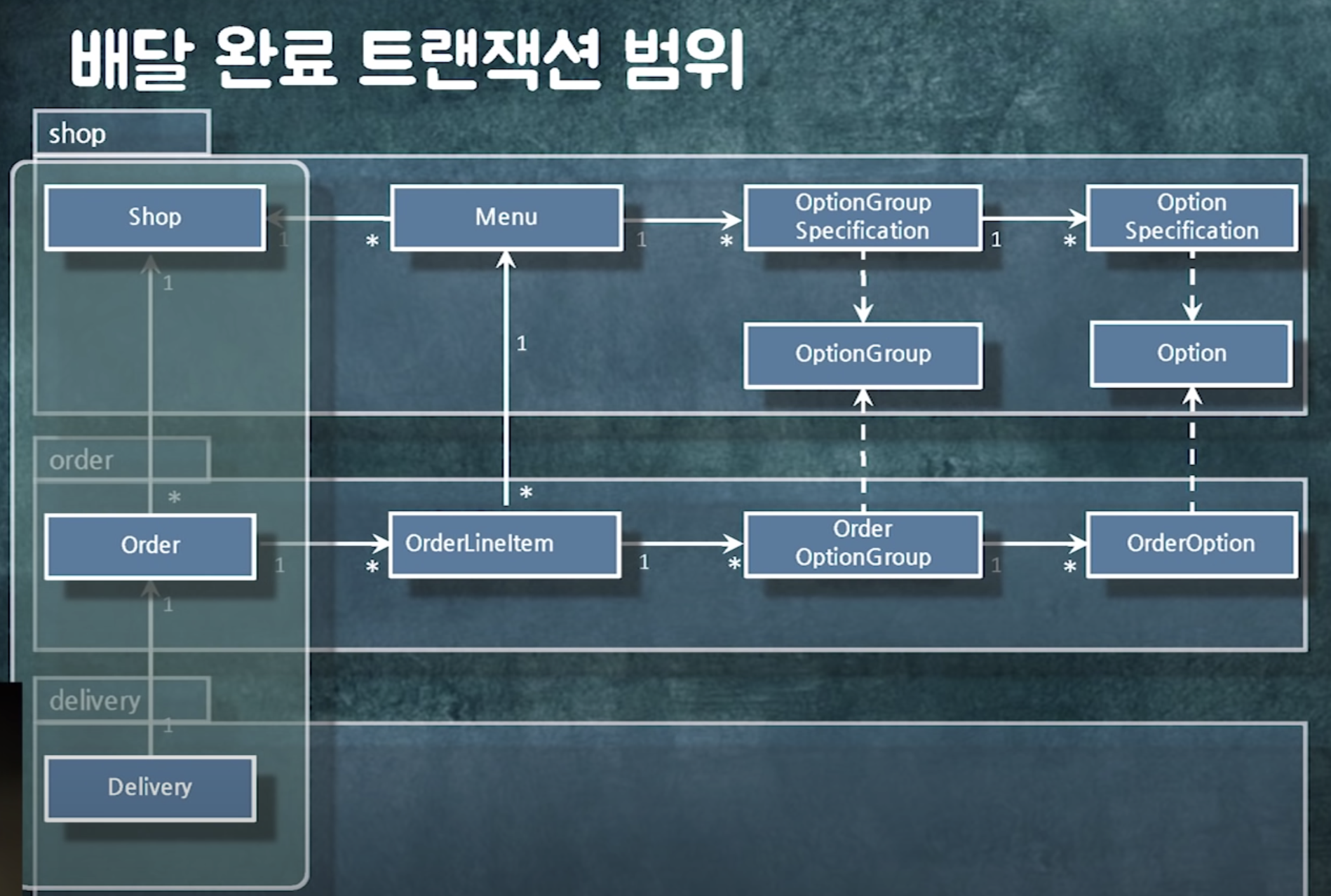
deliverOrder에 @transactional 붙어있음 -> 하나의 트랜잭션으로 묶여있음
-> 이 객체들이 하나의 트랜잭션 안에서 하나씩 하나씩 락을 잡으며 업데이트됨
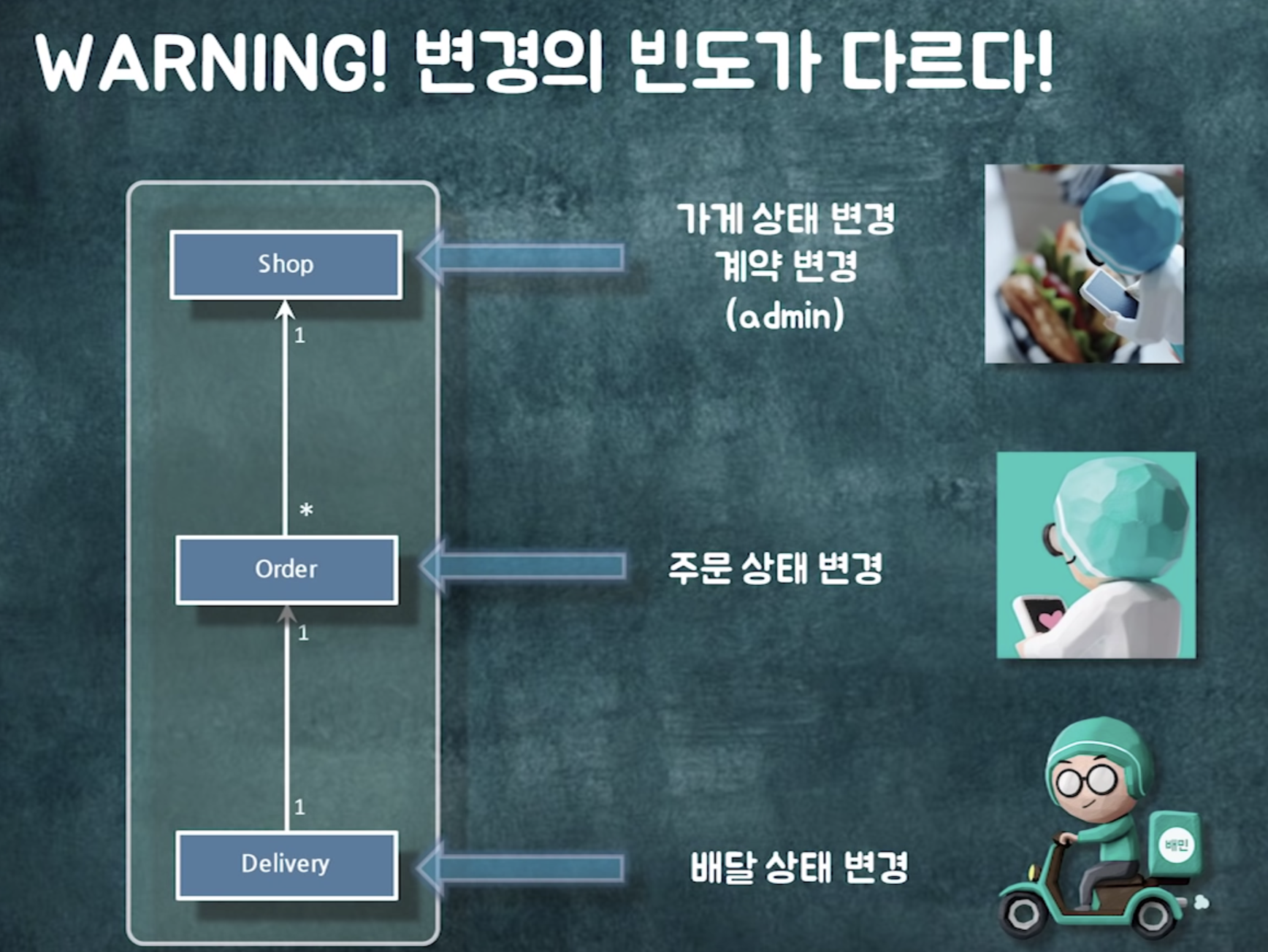
그런데 잘보면 각 객체의 변경주기가 다르다
가게 : 사장님이 가게를 영업중, 준비중으로 바꿔야지~
주문 : 사용자가 취소할래~
배달 : ~
롱트랜잭션으로 묶여있는 이 객체들이 새로운 요구사항이 추가될수록 트랜잭션이 물리는 주기가 달라짐
ex) 예전의 한 사고
어드민쪽에서 대용량 업데이트 처버림. 트랜잭션에 락이 쫙 걸리면서 다른 사용자의 요청(주문)이 다 튕겨져나감
=> 아무 생각없이 객체들을 쫓아가며 수정하다보면 트랜잭션 경합이 발생해서 성능이 저하되거나 응답성이 떨어지는 경우가 발생
객체 참조가 꼭 필요할까???????????????????
객체 참조의 문제점 : 모든 것을 연결시켜버림


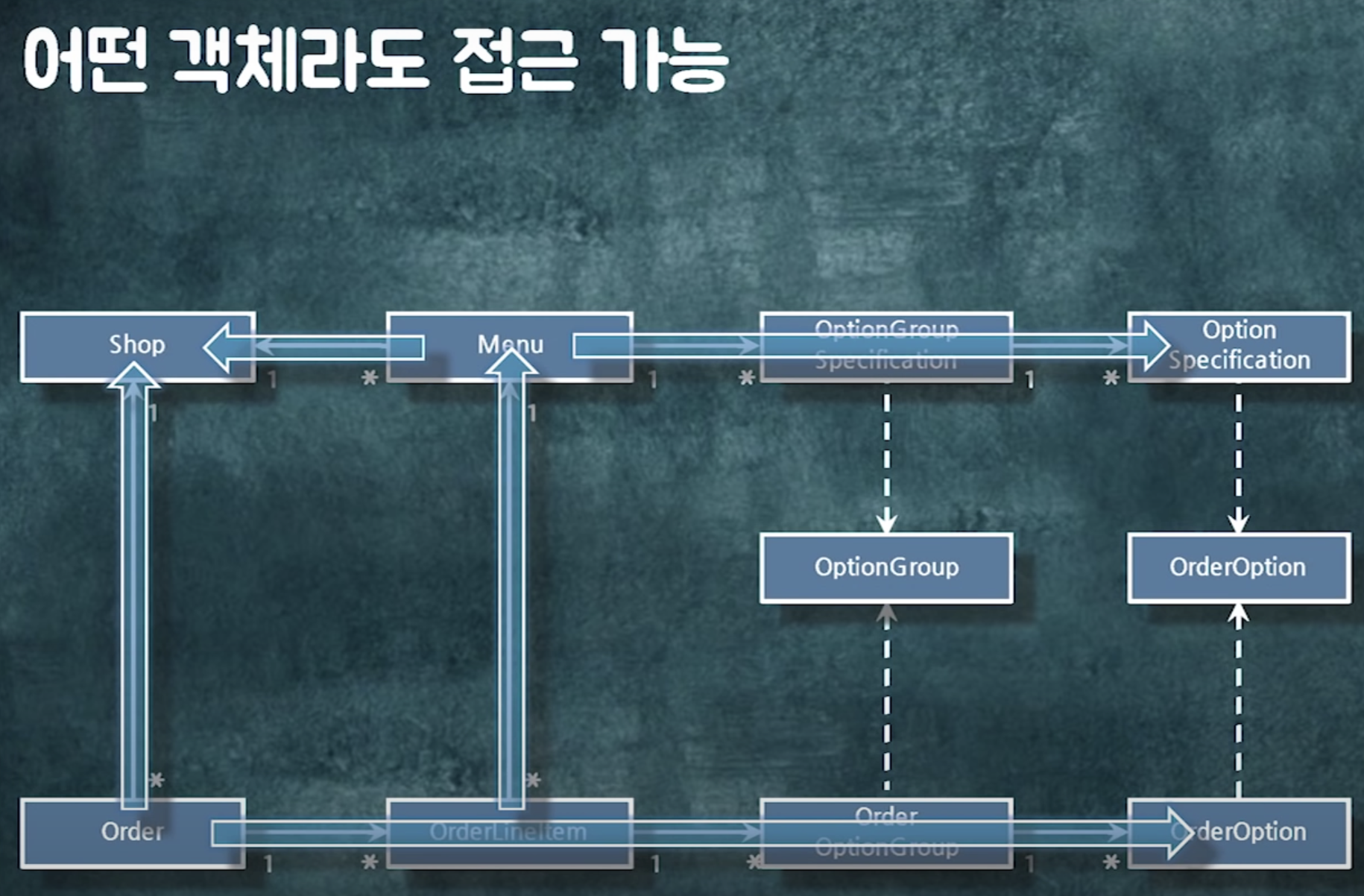


객체 참조는 가장 큰 결합도. 영구적인 결합도. 어떤일이 있어도 항상 같이 있어야해.
=> 필요한 경우 객체 참조 끊어야함
연관관계란. order를 알면 shop으로 갈 수 있는. 탐색가능성.
연관관계를 구현하는 다향한 방법.
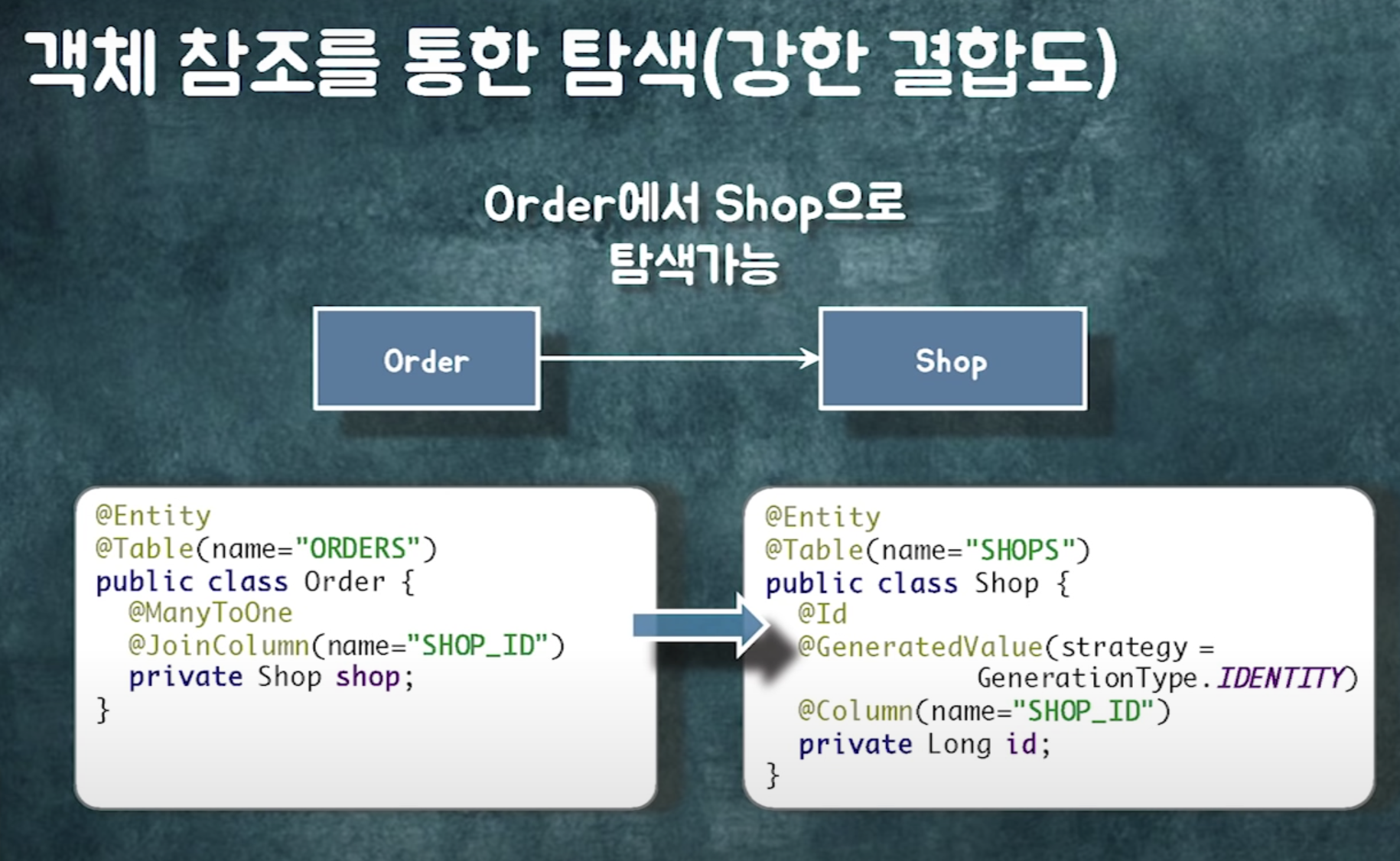
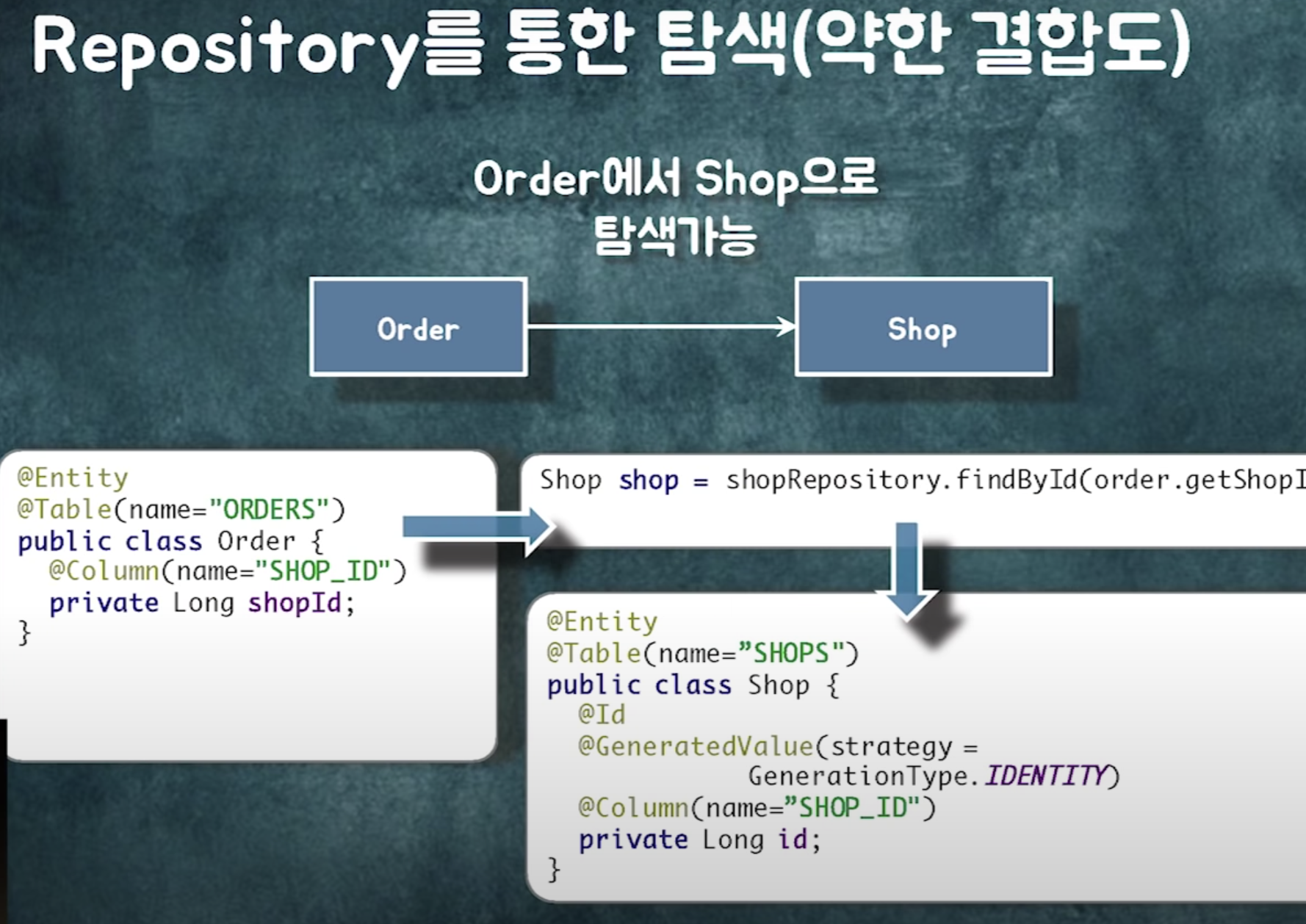
repository에는 연관관계를 구현할 수 있는 operation들이 들어가줘야한다.
근데 이렇게 보면 굉장히 깔끔함. 비즈니스 로직이라.
근데 실제로 구현하면서 '조회'가 들어가기 시작하면 연관관계가 덕지덕지 붙기 시작. 조회 로직을 처리하기 위해 양방향 연관관계가 마구마구 들어가기 시작.
비즈니스 로직은 단방향으로 깔끔하게 만들 수 있는데, 조회를 넣기 시작하면 양방향이 늘어남.
어찌됐든. 비즈니스 로직이라는 측면에서 Repository에 들어가는 메소드는 다 연관관계 관련된걸로 구현하는걸로 생각.
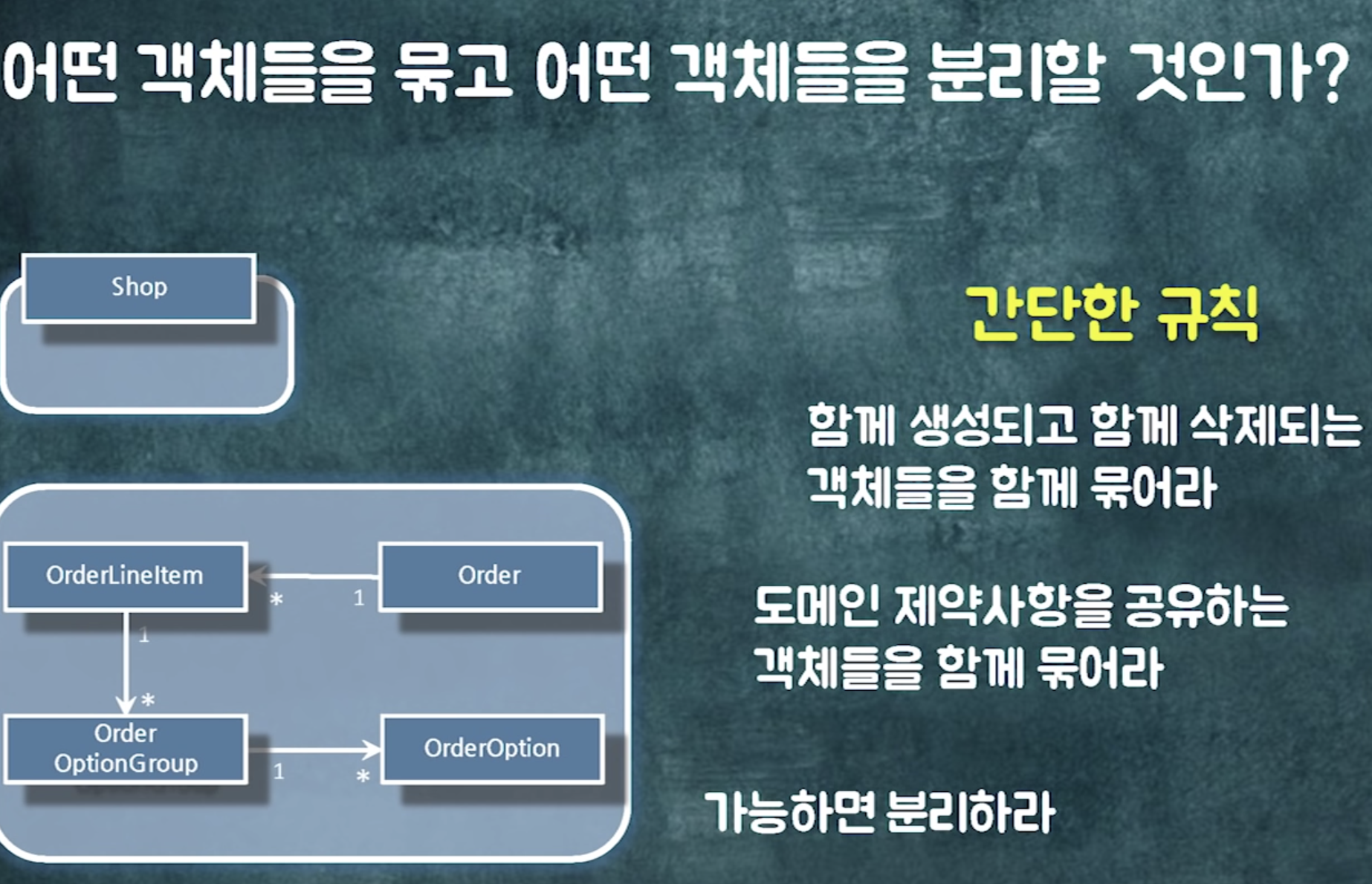
본질적으로 결합도가 높은 애들은 묶어야함. <-> 어떤애들은 굳이 연결안해도 repository등으로 탐색가능함.
구분 방법 : 도메인 룰
같이 처리해야 하는 애들 <-> 따로 처리해도 돼
트랜잭션안에 포함되어야 하는것들? 같이 변경되어야 하는 것(비즈니스 로직)
규칙1 (생성 및 삭제 시점)
함께 생성되고 함께 삭제되는 개체들을 함께 묶어라(같이 움직이는 애들) -> 객체 참조
그렇지 않은 경우 -> 끊어버림
규칙2 (constraint)
도메인 제약사항 공유하는 애들(얘가 바뀔 때 얘도 바뀌어야해)
ex. 장바구니-장바구니항목
묶어야할까? 말아야할까?
장바구니가 생성되는 시점과 장바구니에 상품을 넣는 시점은 다르다 (라이프 사이클 다름)
일반적인 이커머스는 장바구니와 장바구니항목 사이에 공유되는 제약사항 없음 -> 찢으면 됨
배민은 있다 (장바구니에 동일한 업소거만 둘 수 있다) -> 하나의 객체그룹으로 묶음
=> 비즈니스 룰에 따라 결정
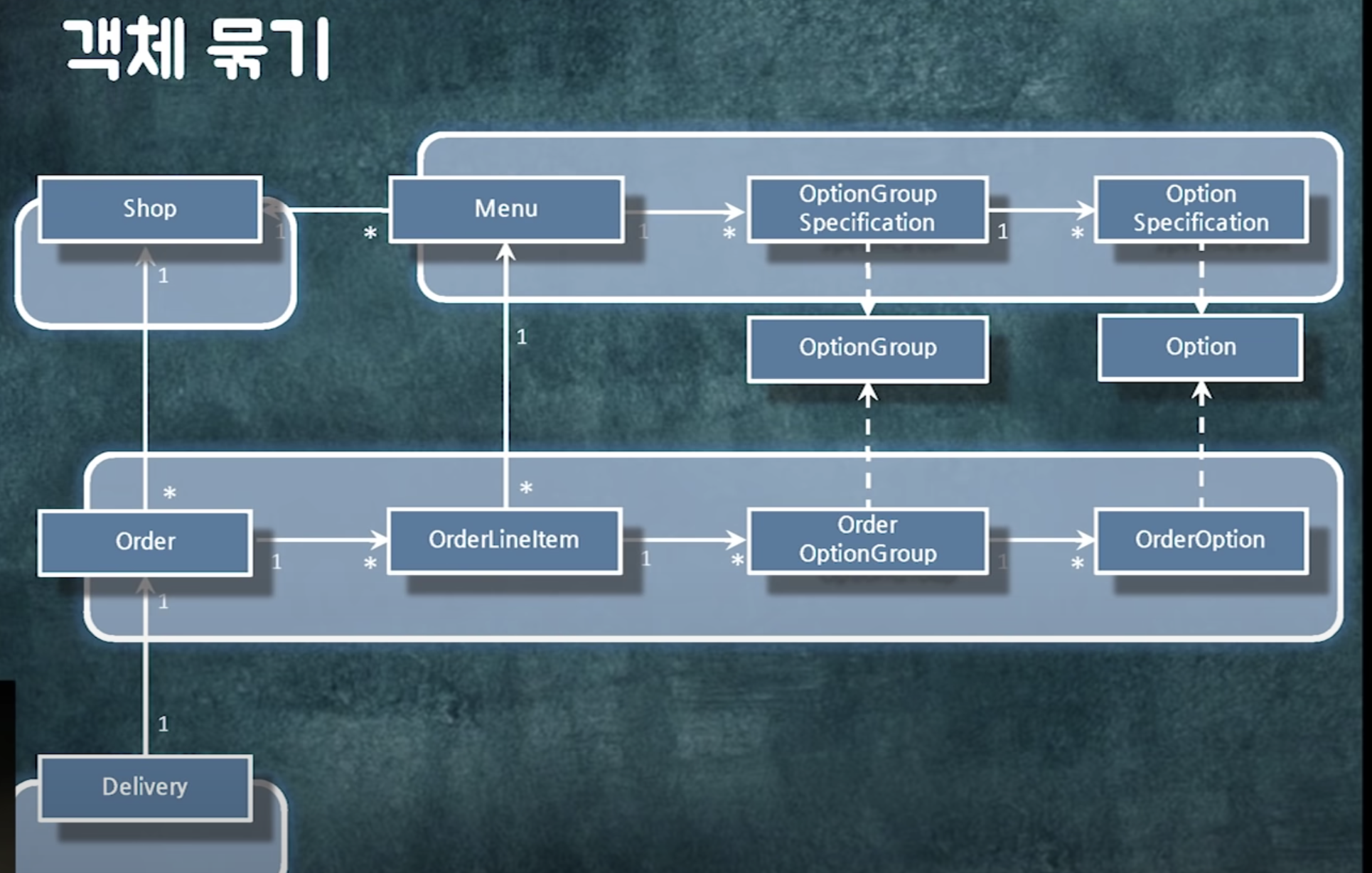
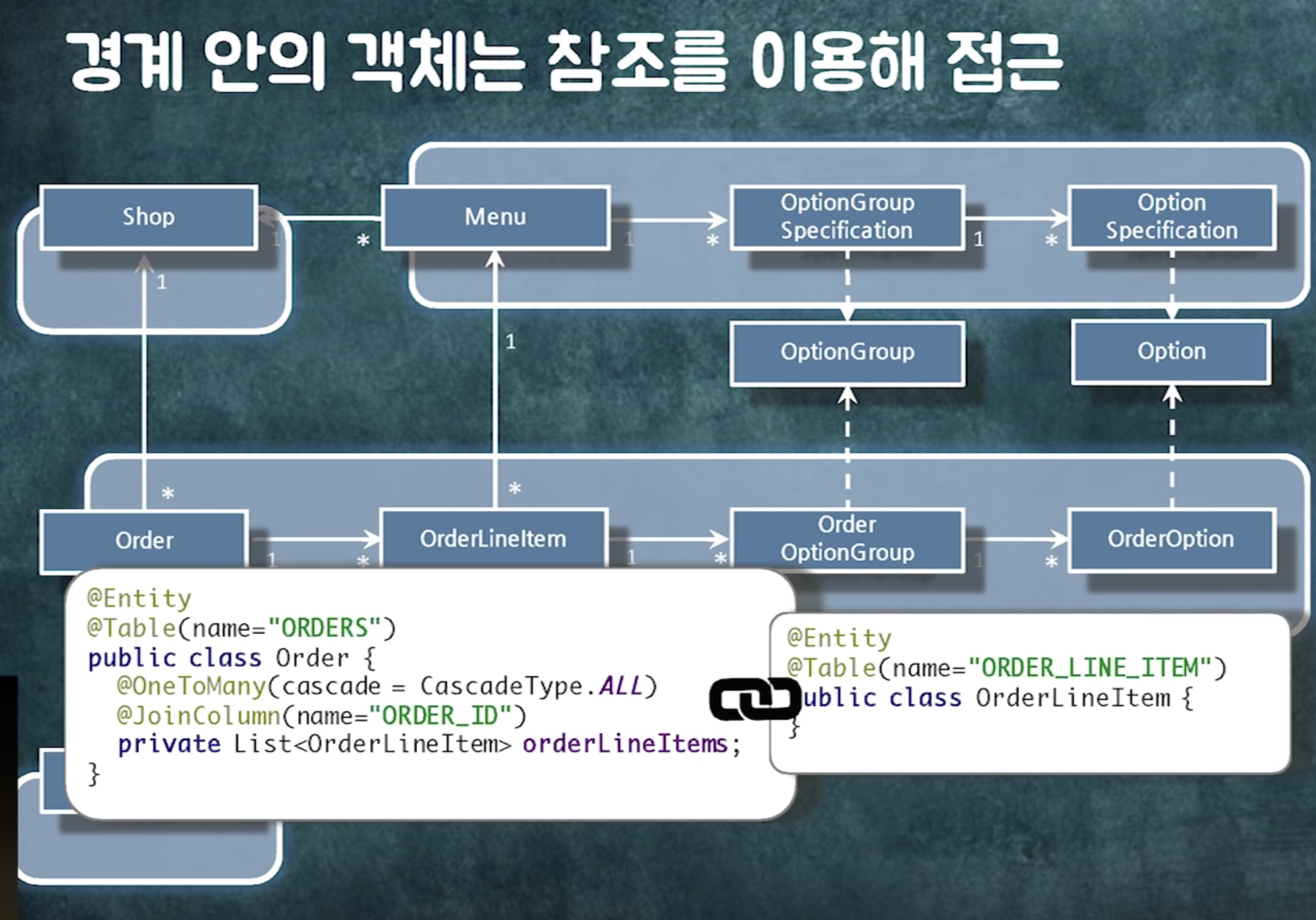
경계 안의 객체는 연관관계로 묶어라.
- 레이지로딩해야하고(같이 읽어야하니까)
- 같이 생성되거나 같이 삭제되거나 같이 수정되어야함 -> cascade를 줄 수 있음
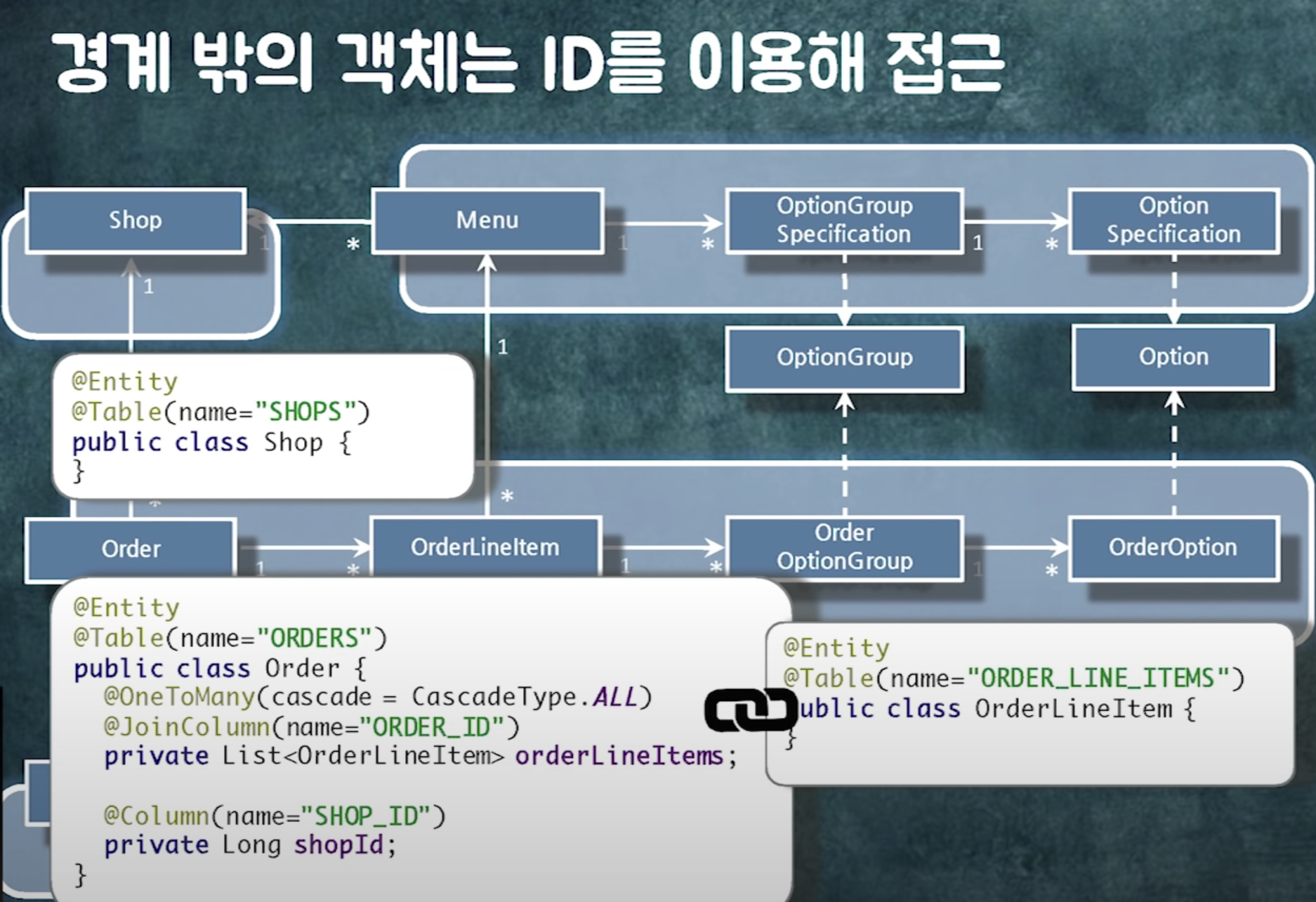
==> 결론 : 비즈니스에 따라 객체 그룹을 잘 나눠야함
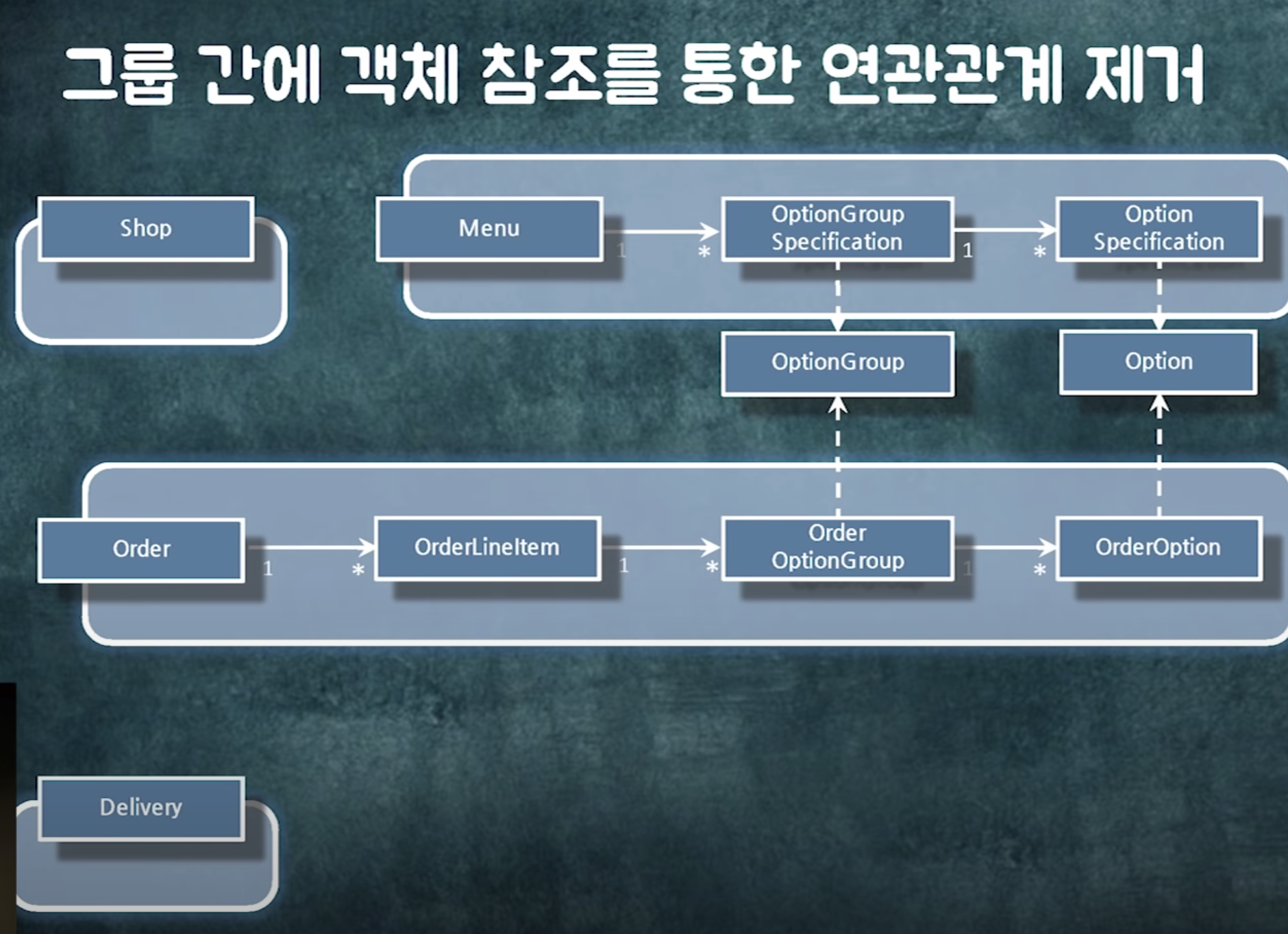
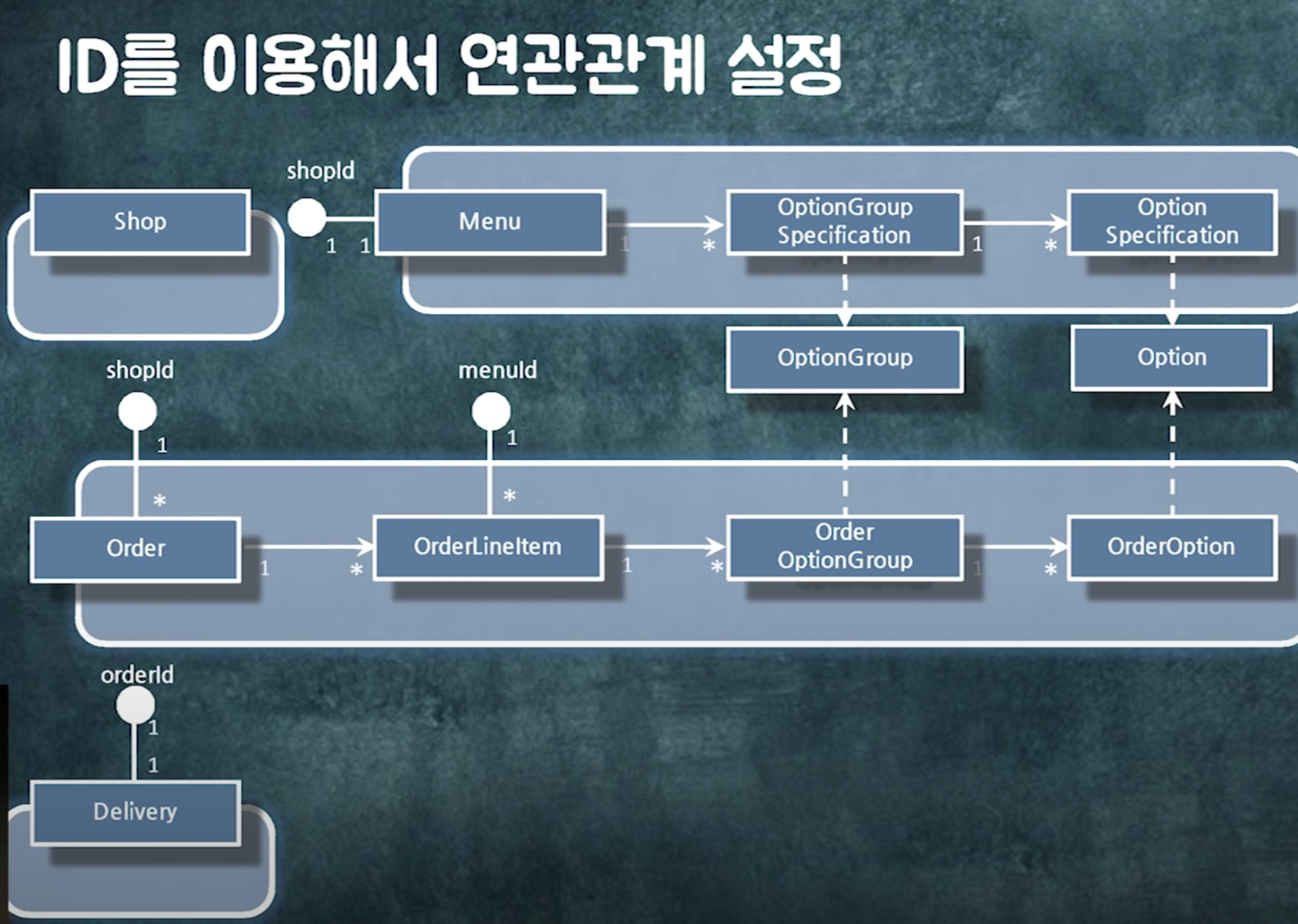
+) 이제 이 객체들 단위로 트랜잭션을 관리하면 됨
+) 조회도 이 단위로 하면 됨 (한번에 같이 조회 or 레이지 로딩) -> 어디서부터 어디까지 가져와야하는지 경계가 확실히 세워짐 (어디부터 어디까지는 한번에 읽어도 돼. 어디부터 어디까지는 한번에 읽으면 안돼)
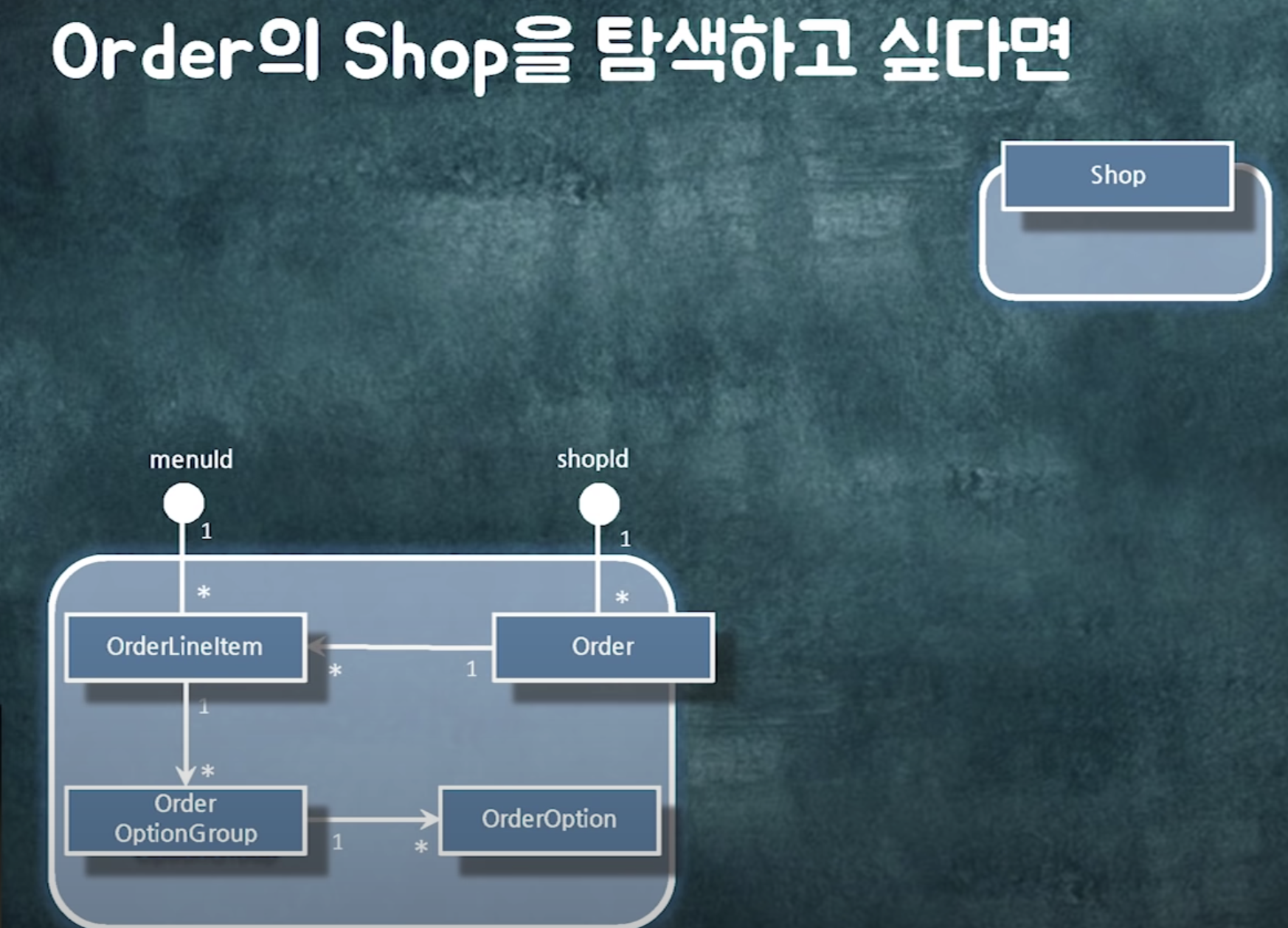
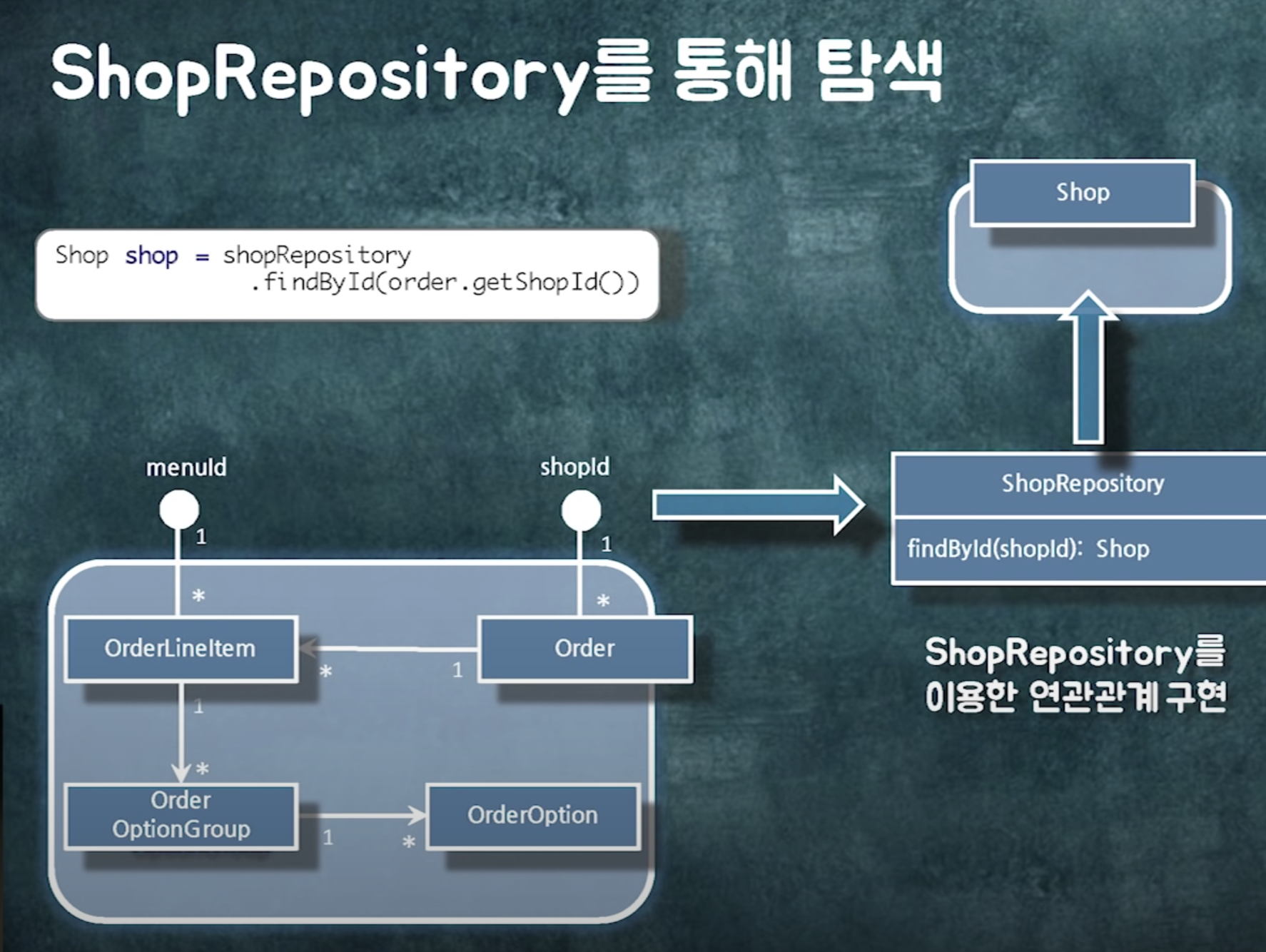
객체 참조 참 편하다.
하지만 실무에 들어가보면 객체를 어디서 묶어야하고 어디서 끊어야하는지가 굉장히 중요함.
연관관계를 구현하는 2가지 방법. 객체참조와 id
일단 참조 없는 객체 그룹으로 나누고 나면
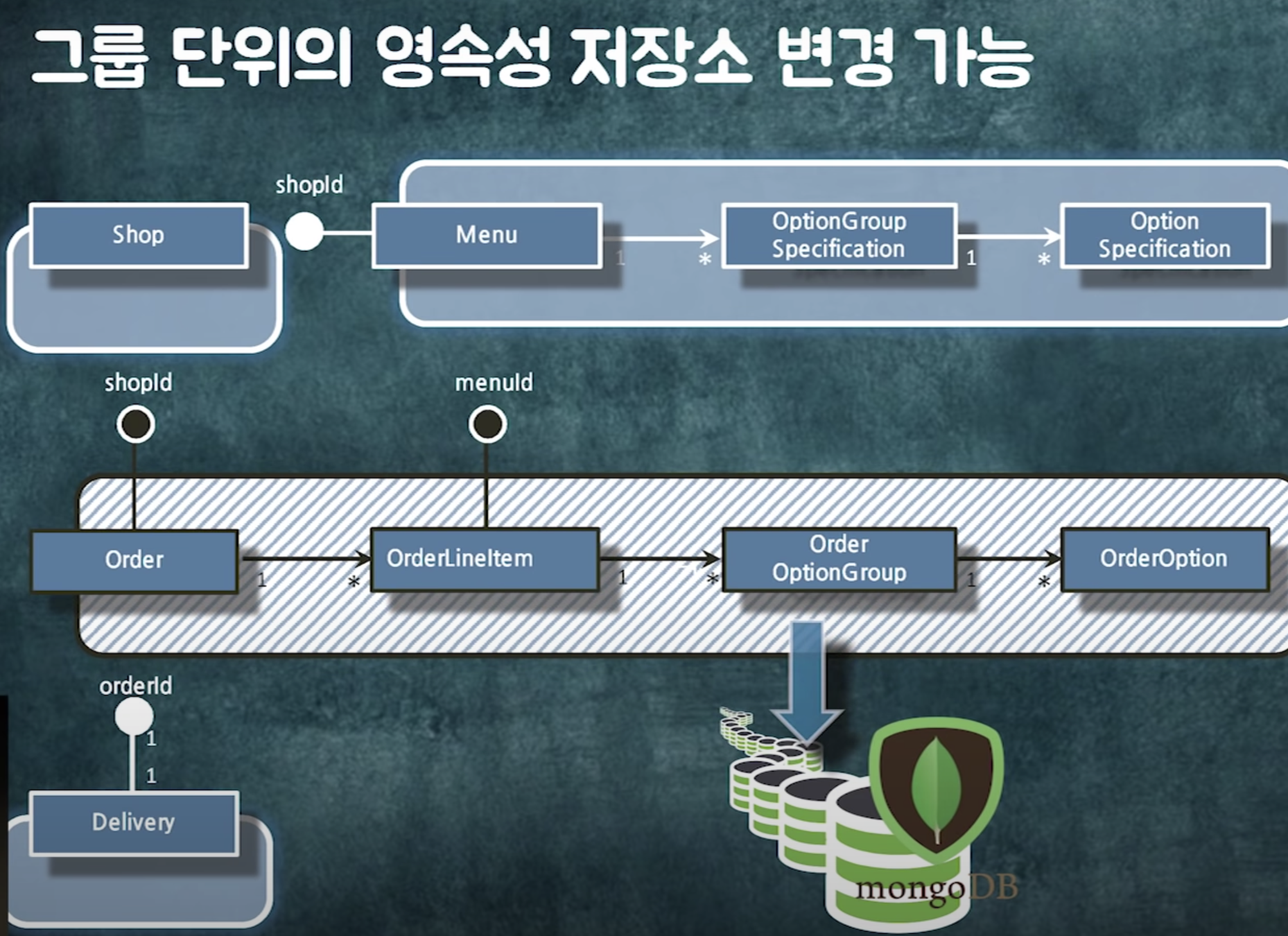
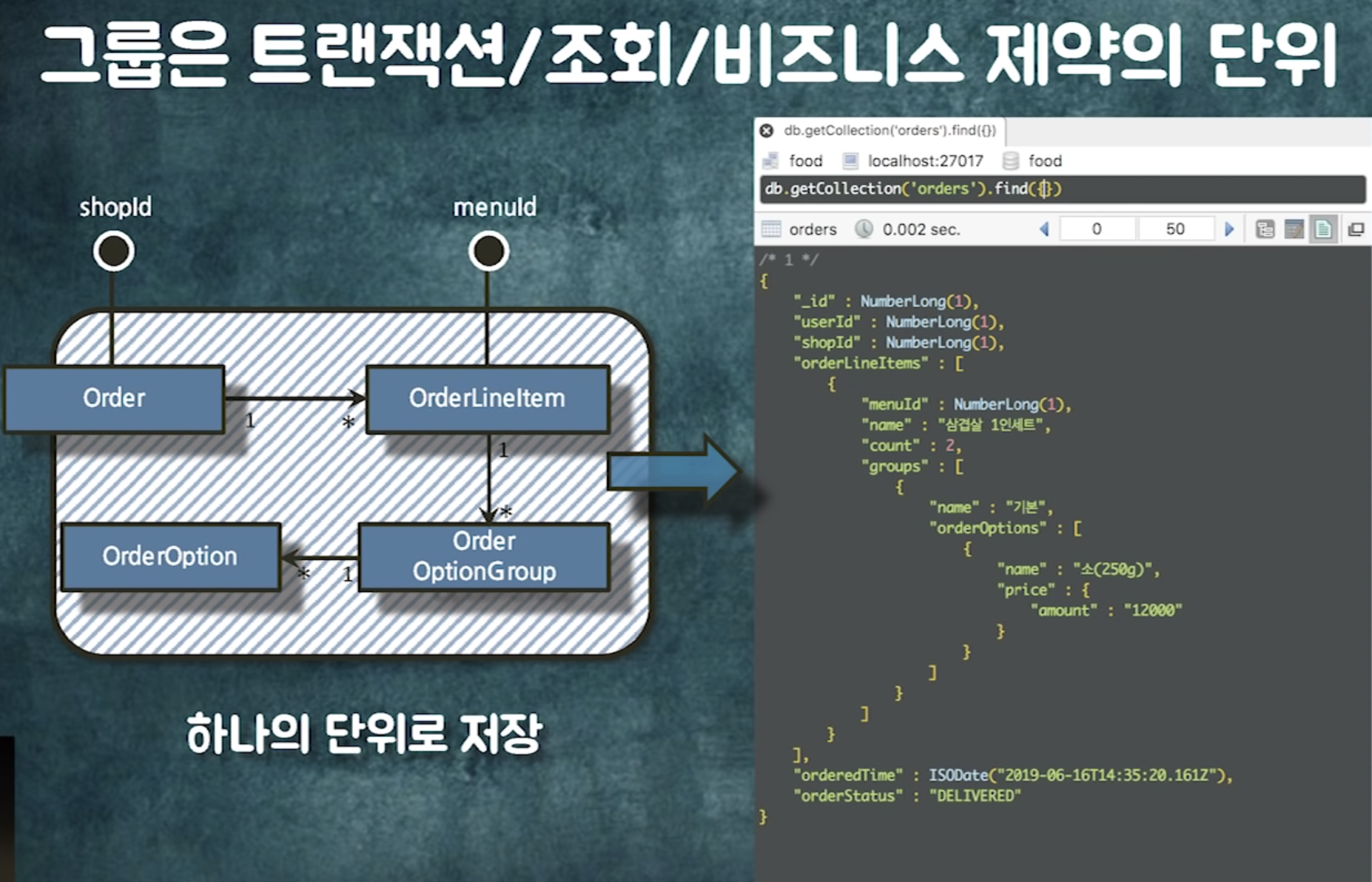
조인을 하던 개별 쿼리로 가져오던 하나의 단위로 읽을 수 있음
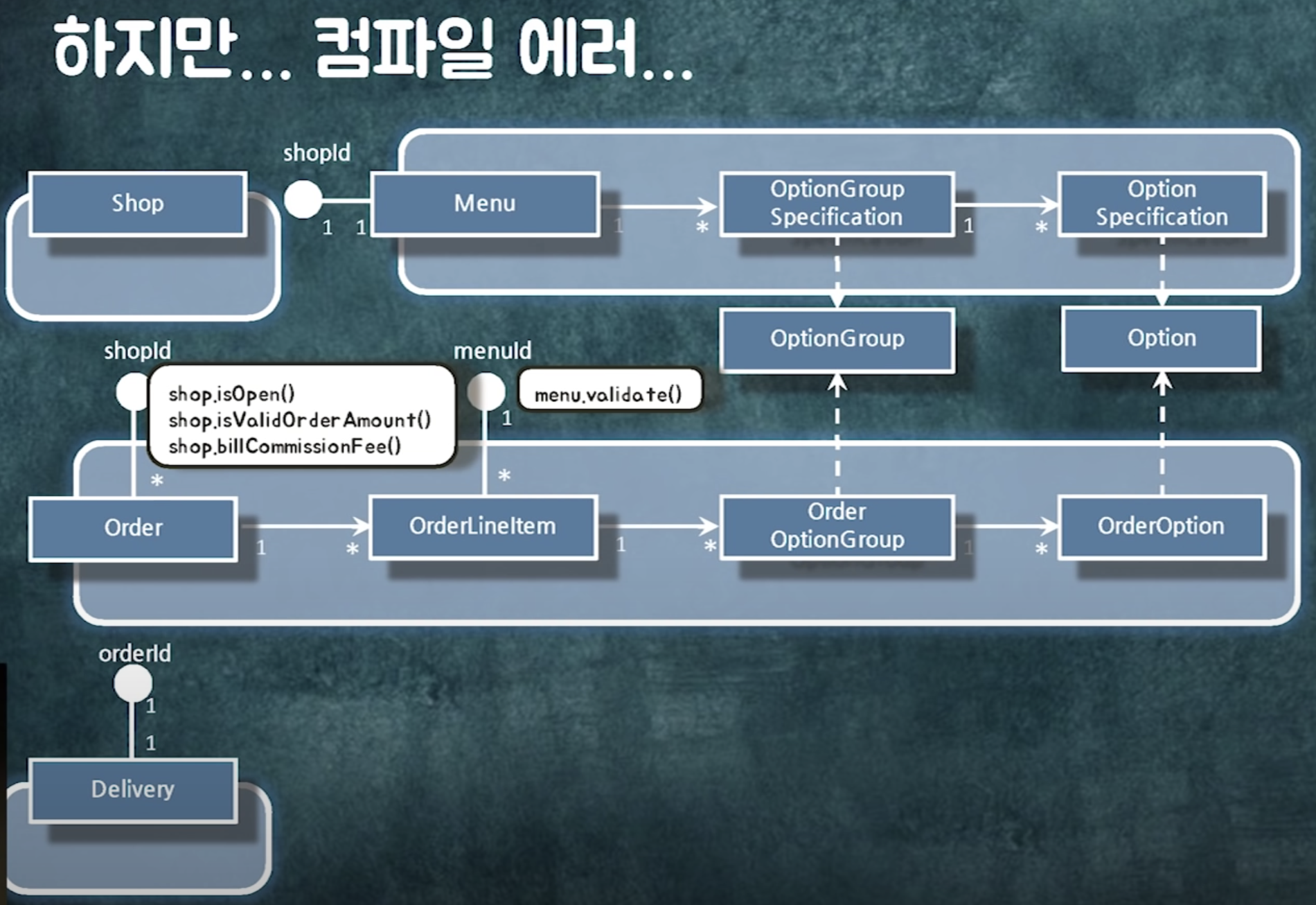
지금까지 객체참조가 있다고 생각하고 로직짜놔서 컴파일에러 발생!
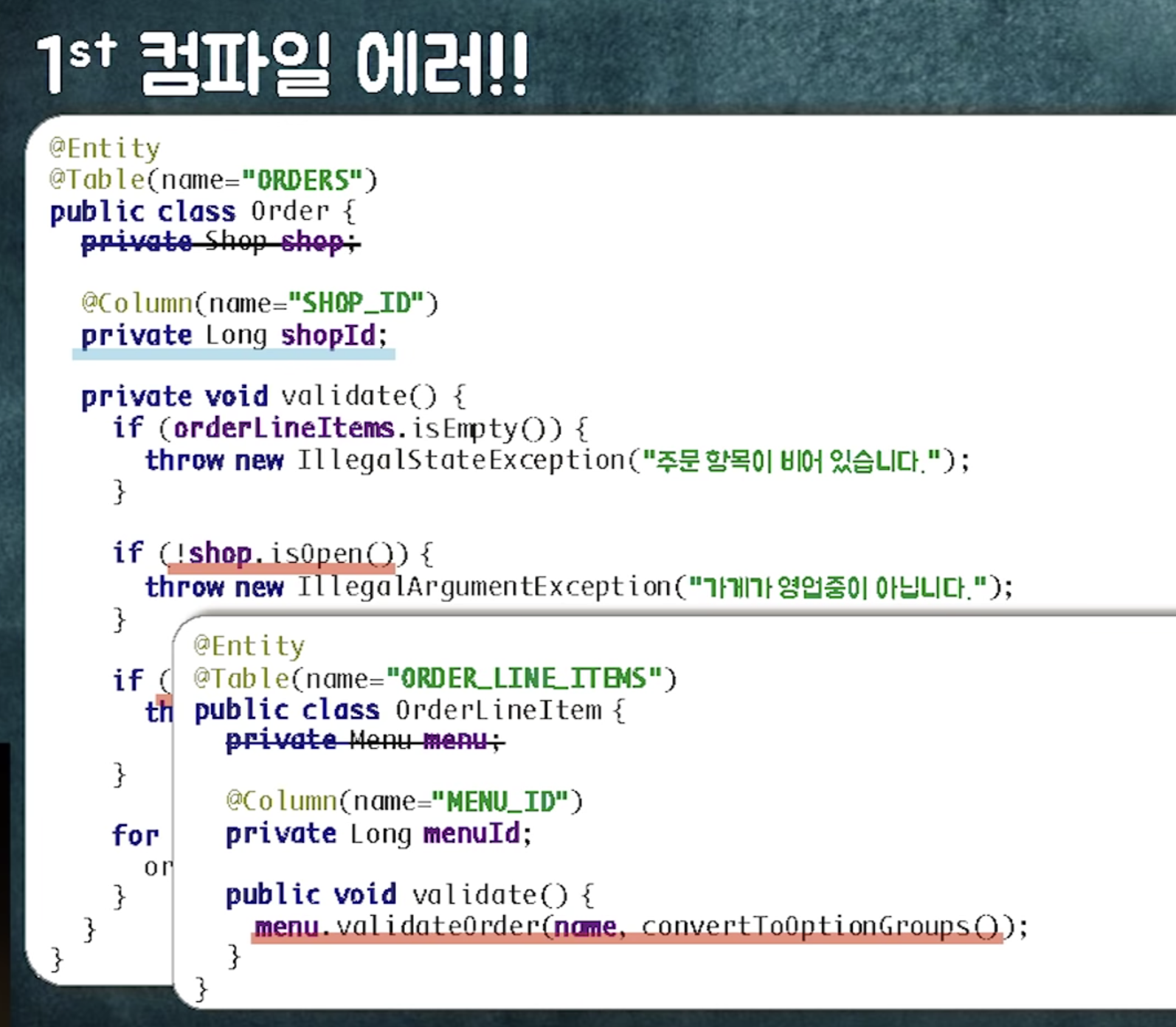
해결방법1: 객체를 직접 참조하는 로직을 다른 객체로 옮기자



컴파일 에러가 발생하는 주문 관련 검증 로직들을 OrderValidator로 한 곳에 모음
이게 나쁜 설계일까? 조영호님은 좋다고 생각한다.


이유1 : validation 로직을 확인하기 위해 여러 객체를 왔다갔다 해야함 -> 한 군데로 모아서 검증관련 로직을 한눈에 볼 수 있음


이유2: order에 validation로직이 있을 때에는 order의 응집도가 낮음.
응집도 = 관련된 책임의 집합
같이 변경되는 애들이 같이 있으면 응집도가 높은 것
해당 객체 안에 있는 로직이 한번에 다같이 바뀜 = 응집도가 높은 것
다같이 바뀌지 않는데 한 곳에 있음 = 응집도가 낮은 것
코드변경 주기가 다른 코드가 한 곳에 있음

떄로는 한눈에 볼 수 있는게 더 좋을 수도.
객체에 대한 검증이 여러 군데에 있을 경우 응집도가 확 떨어짐.
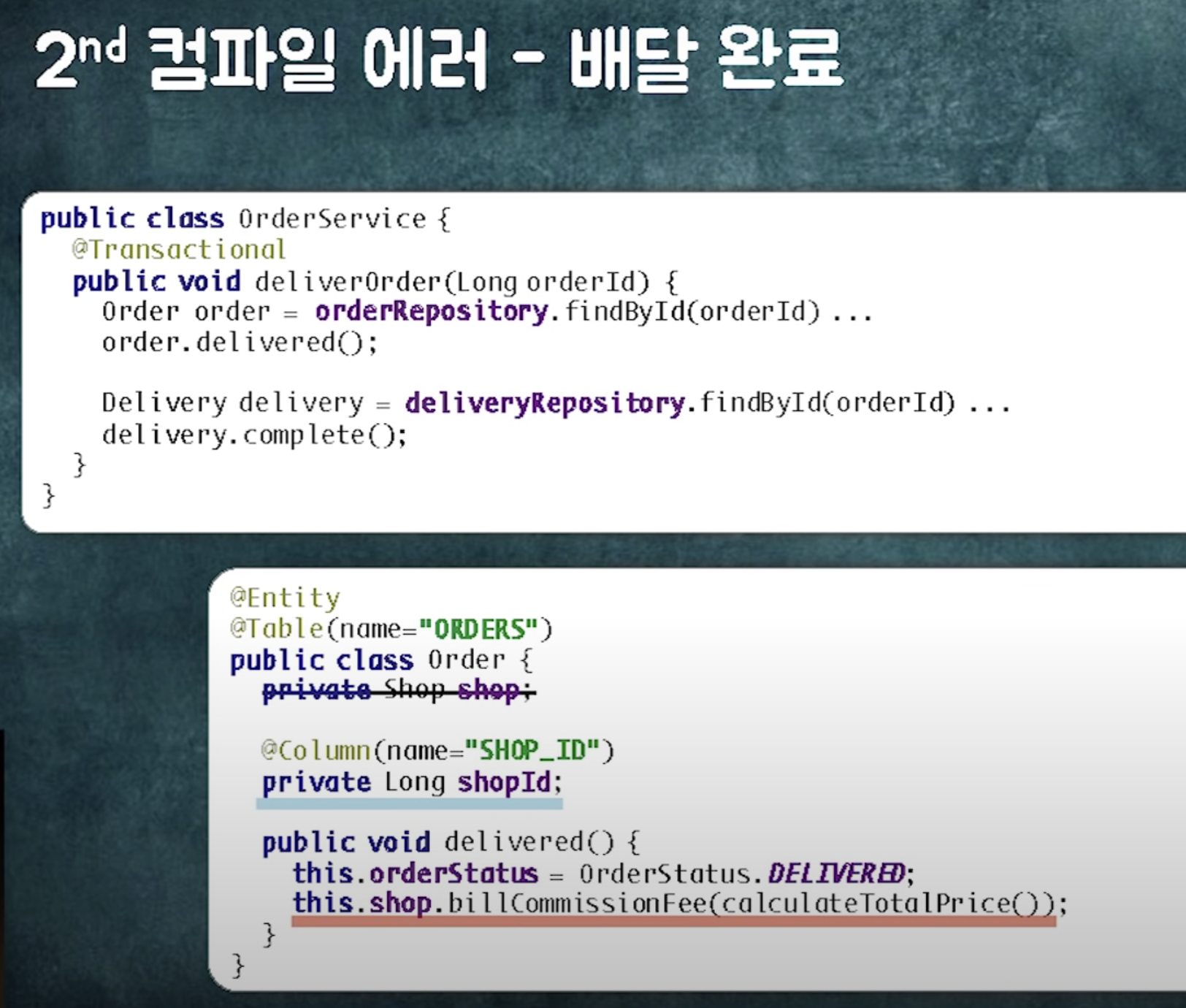
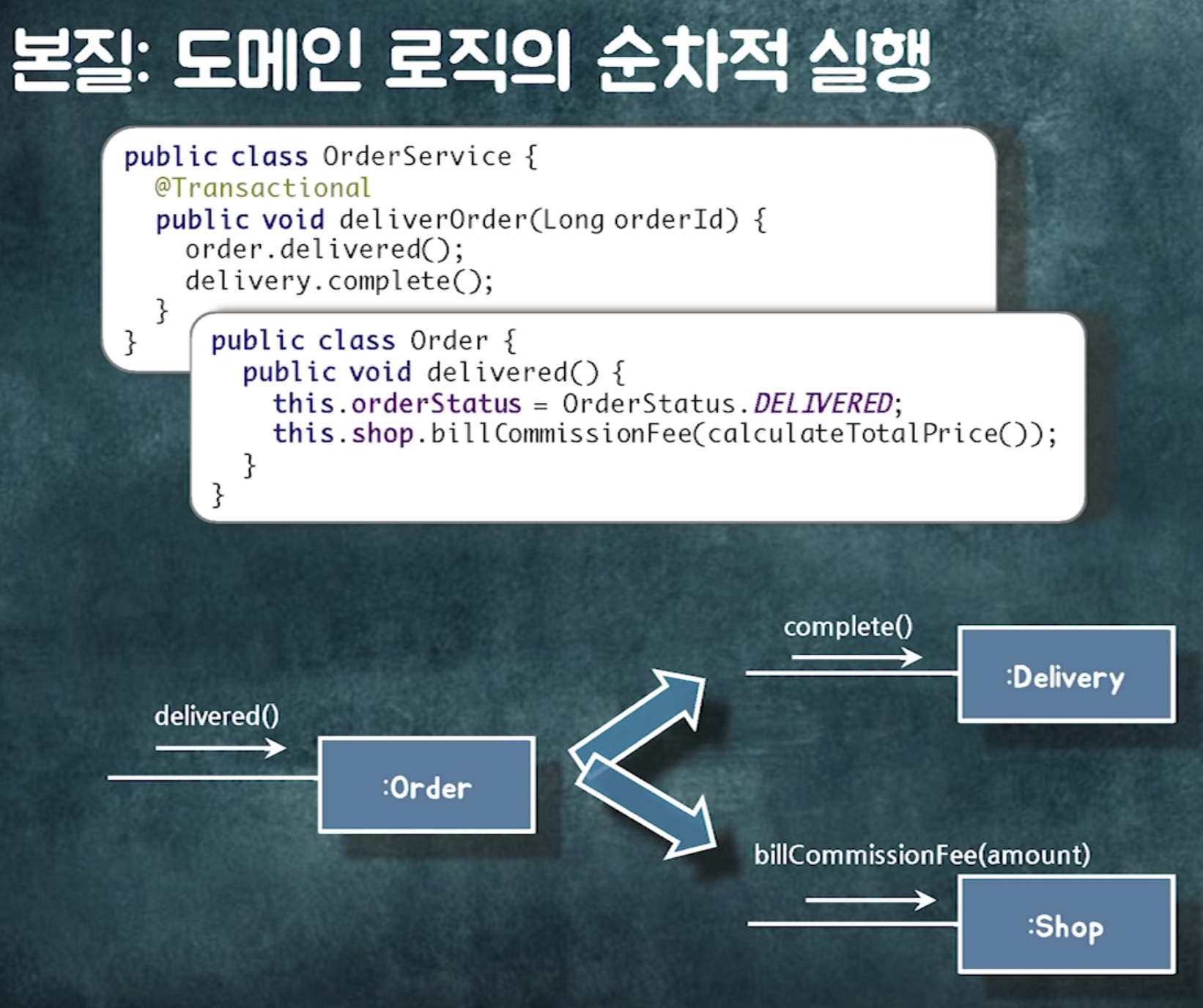
도메인 로직의 순차적 실행 (a를 실행했을 때 b,c도 실행되어야 해요)로 인한 문제
(order가 바꼈을 때 delivery와 shop도 바뀌어야해서 생기는 문제)
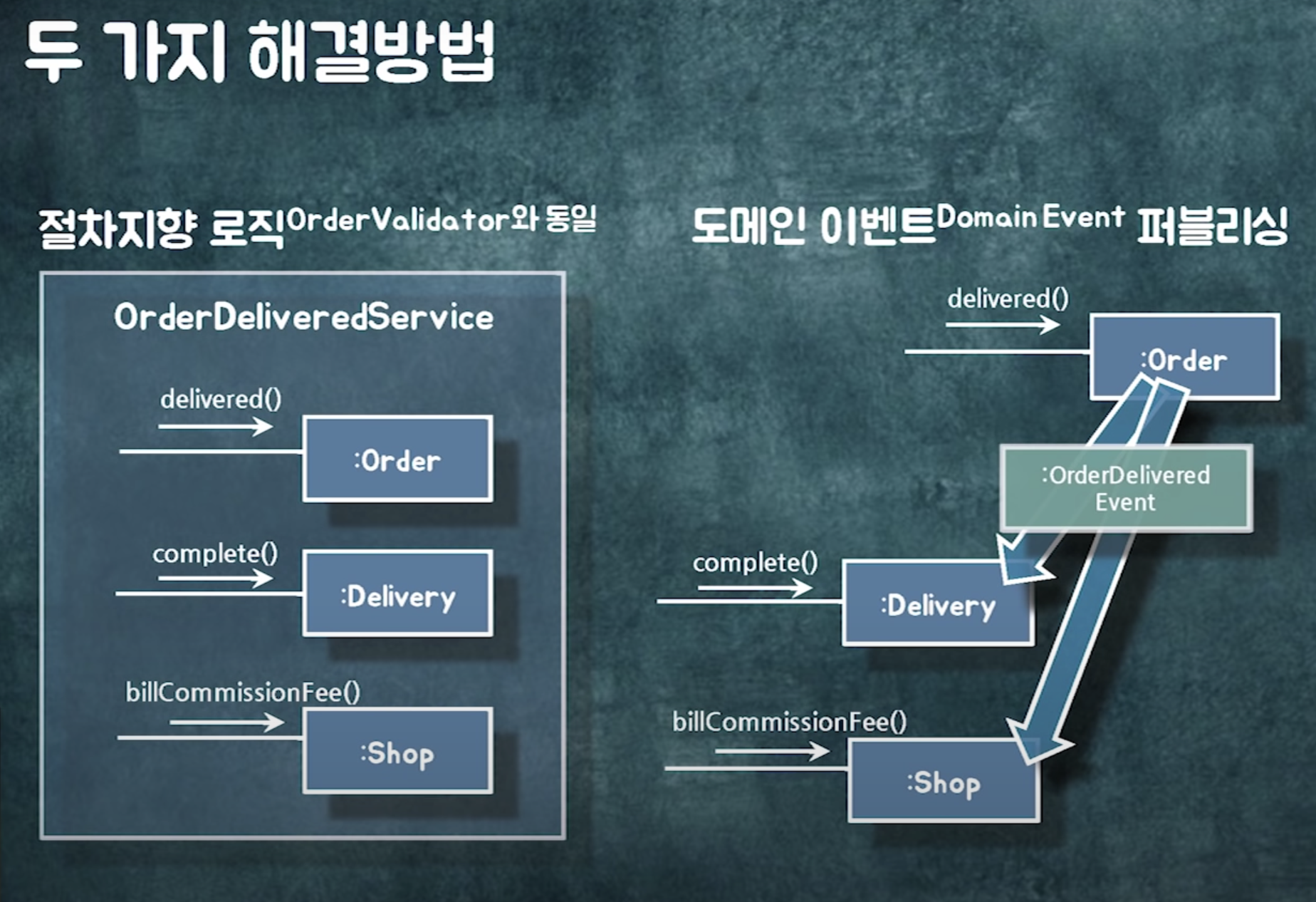
방법1) 앞에처럼 절차지향적으로 로직을 모음



비즈니스 플로우가 한눈에 보임!!
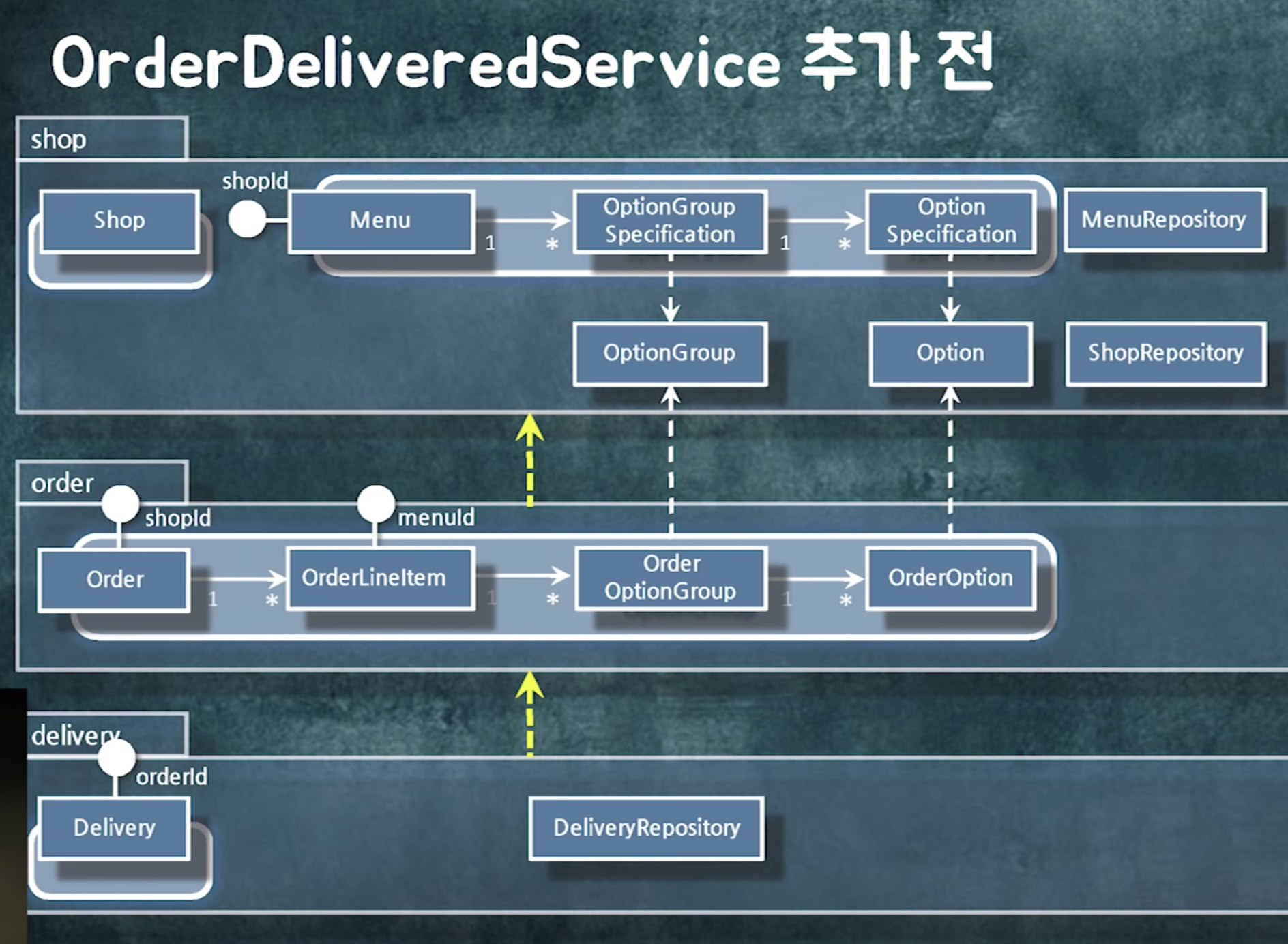
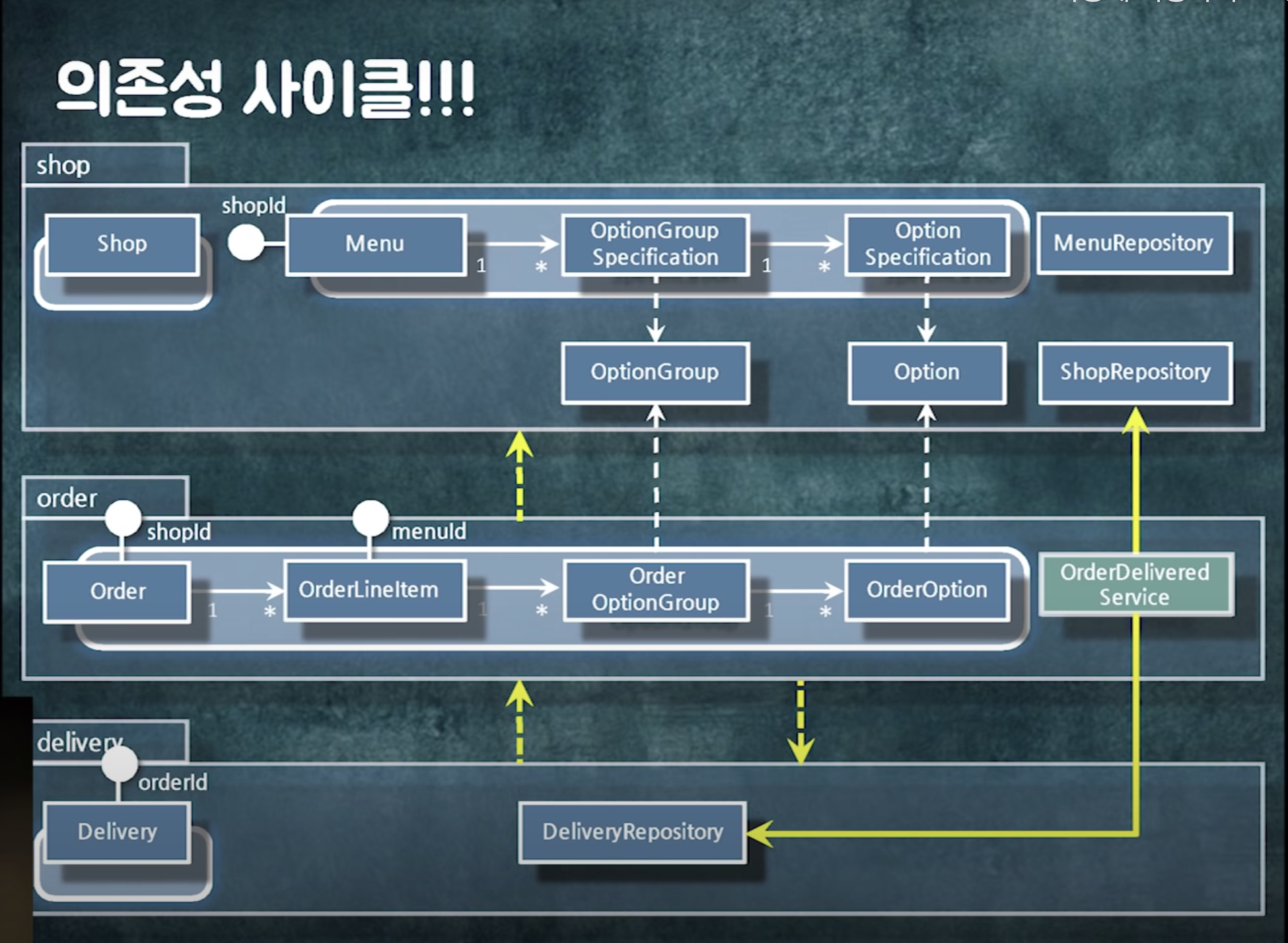
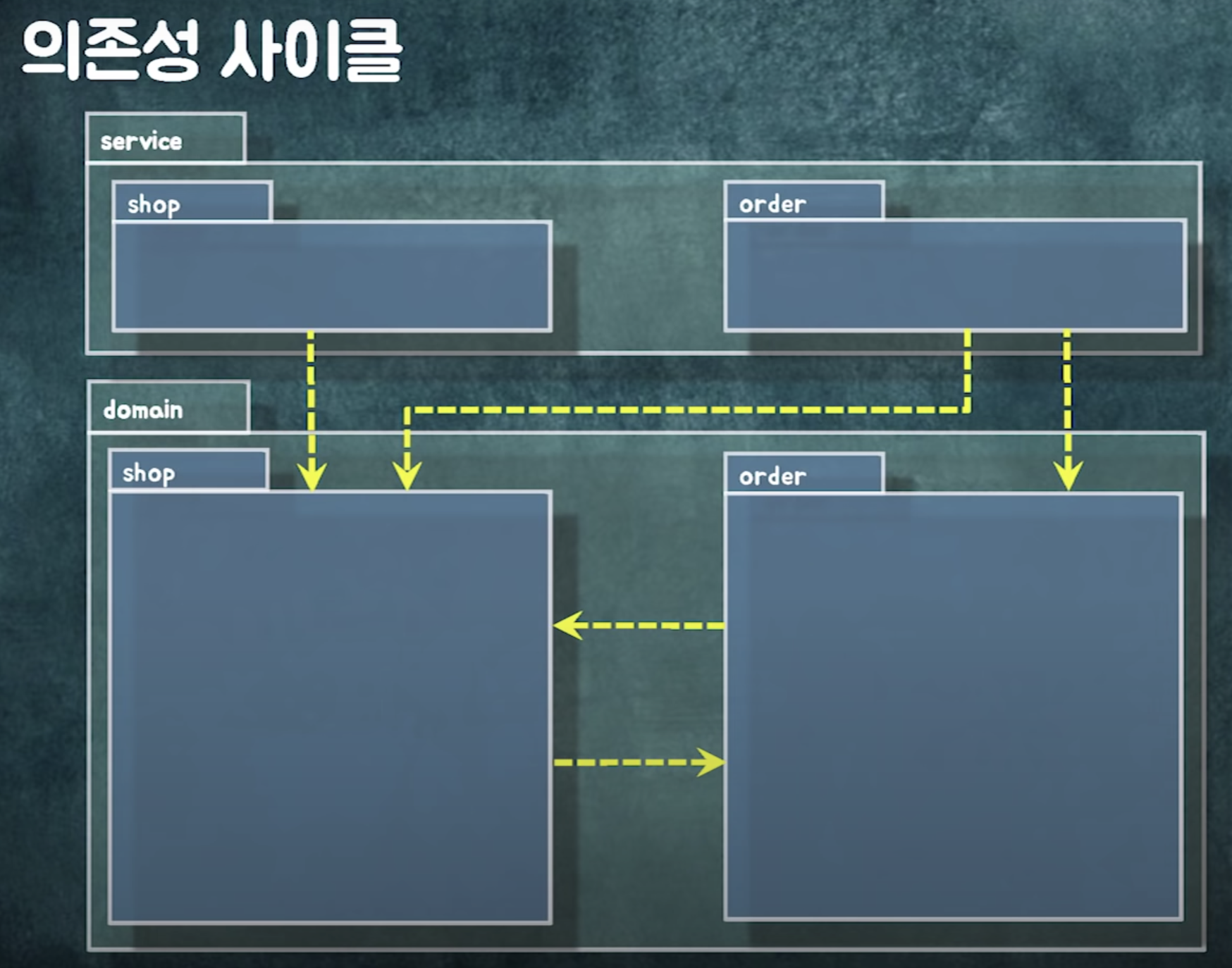
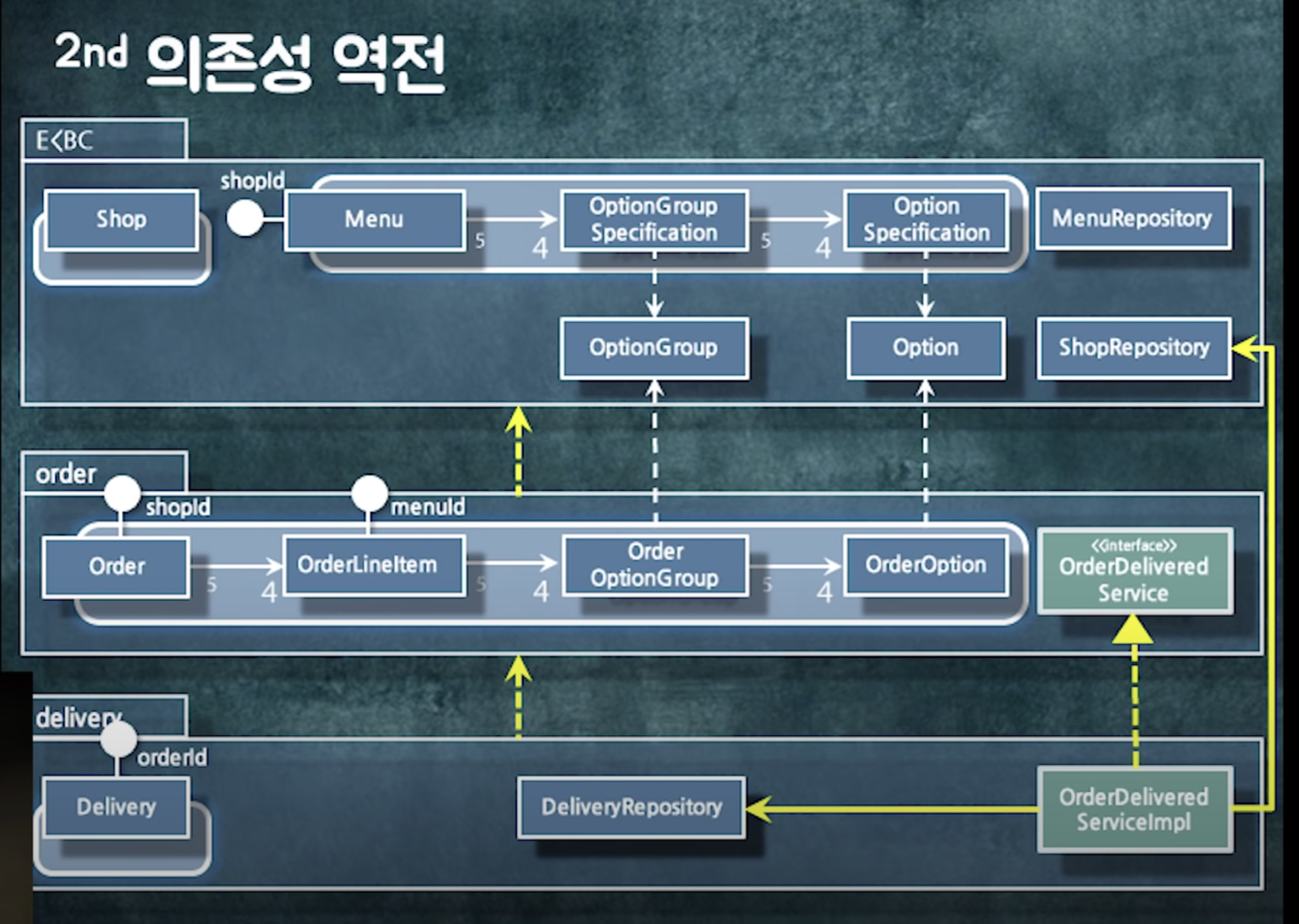
추가 후 의존성 사이클이 생겼다.
=> 인터페이스를 사용해 인터페이스를 역전시키자
패키지 간 사이클이 돌때 방법
- 중간 객체를 둬서 변환
- 인터페이스나 추상 클래스로 추상화를 넣어 의존성 역전
- 이벤트
- 패키지 분리
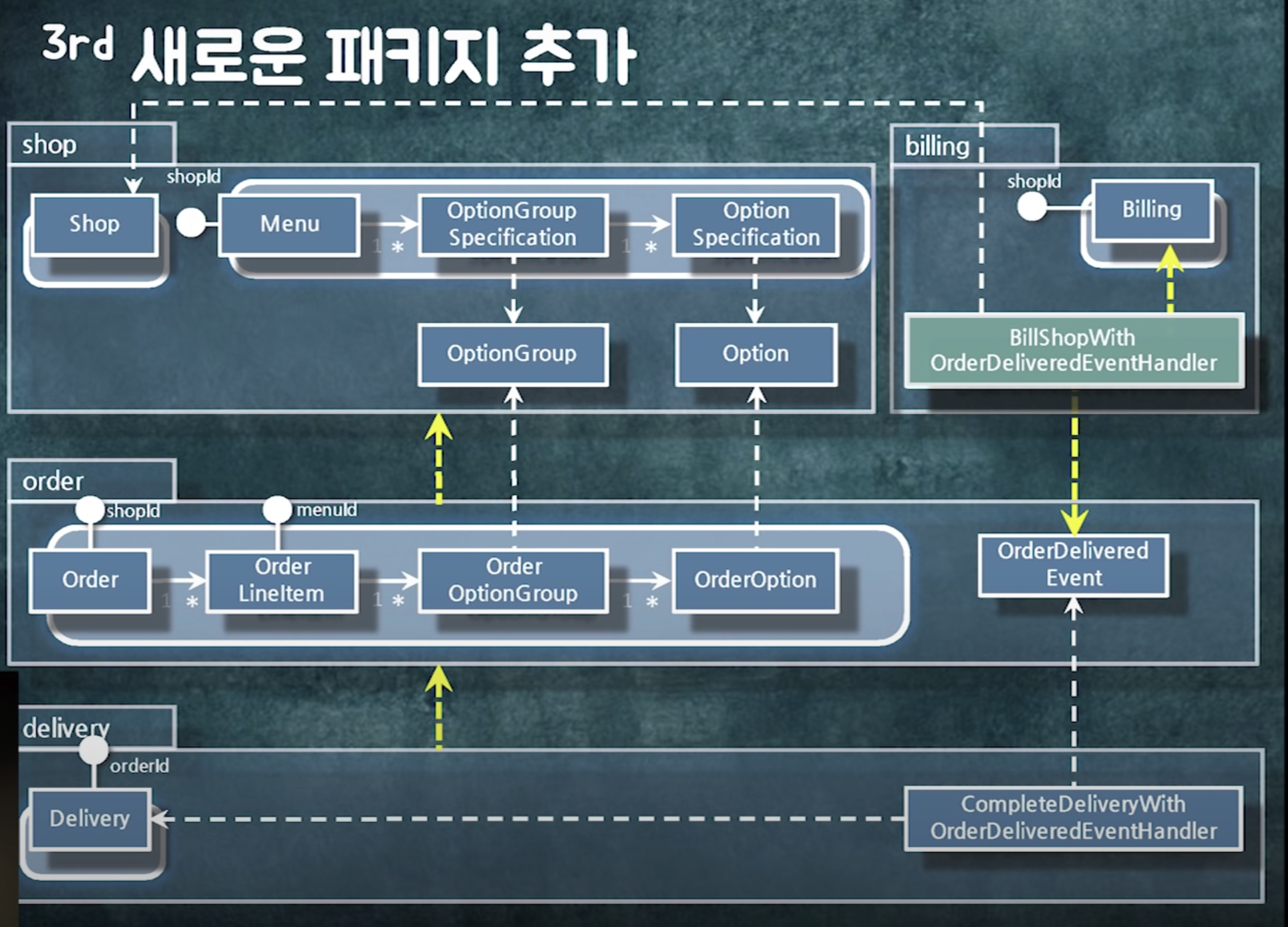
방법2) 도메인 이벤트 발행
서비스 : 객체간 결합도를 낮추고 로직간 결합도를 높이고 싶을 때
이벤트 : 로직간 결합도를 느슨하게 하고 싶을때!!
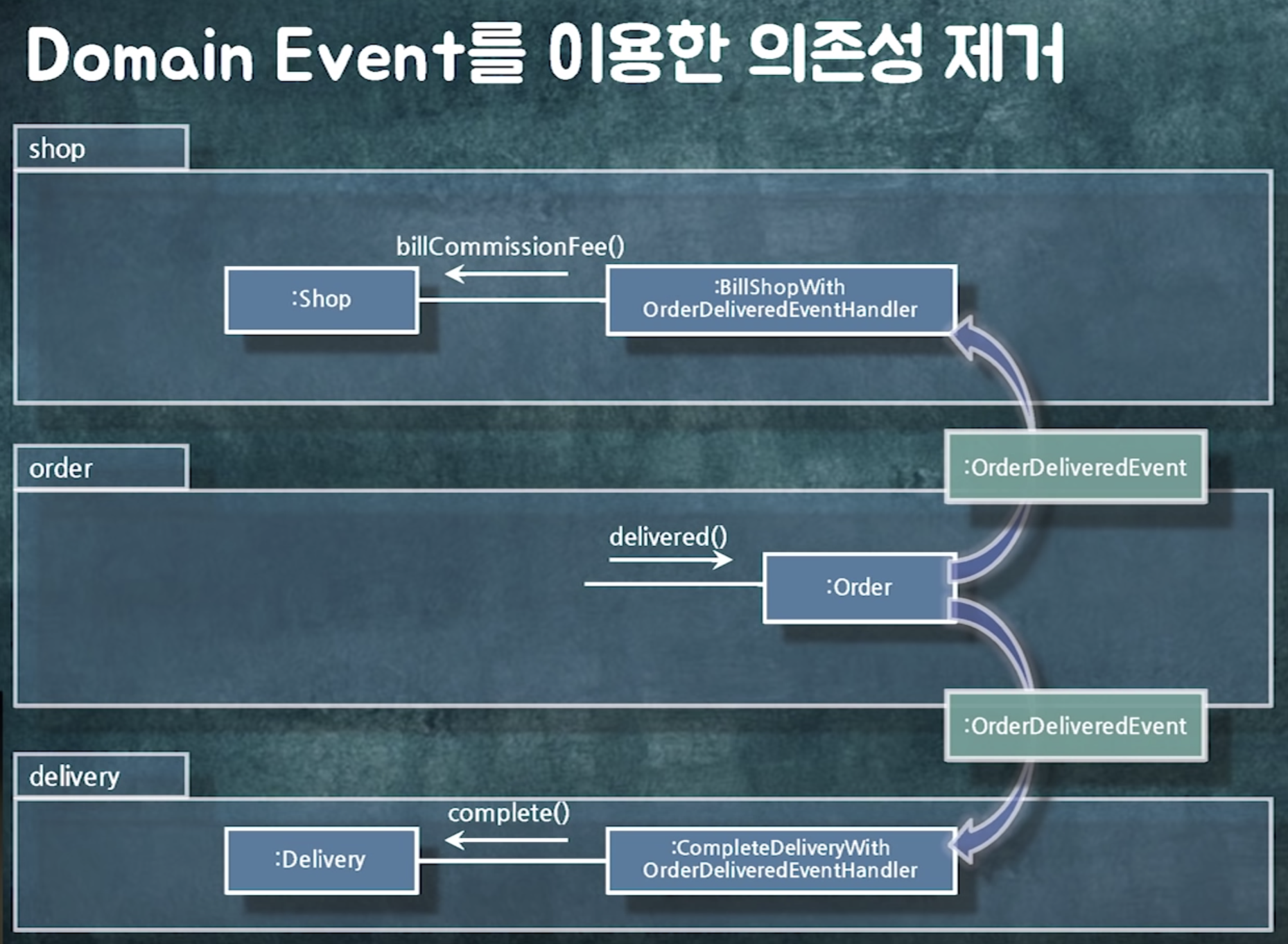


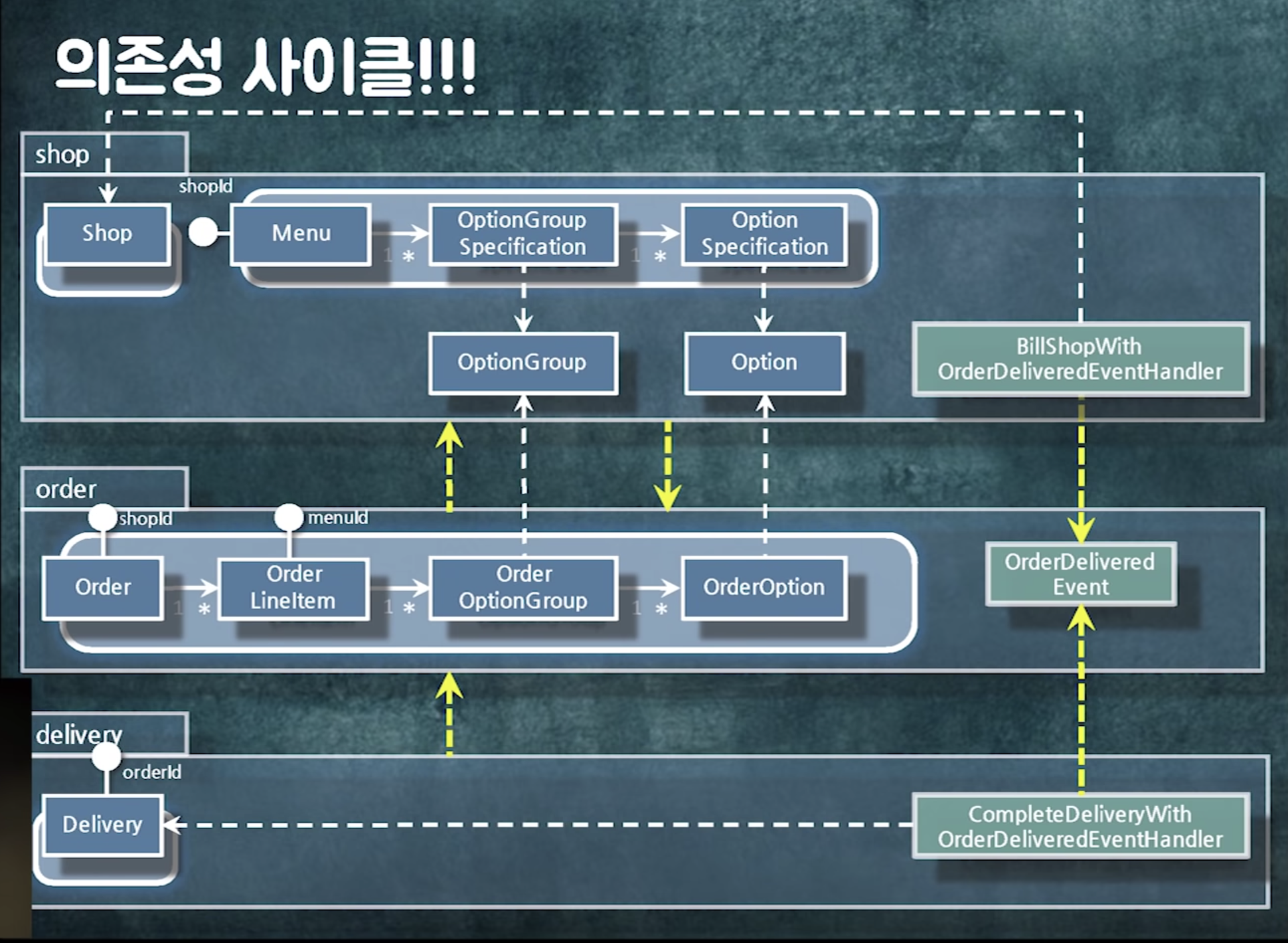
의존성 사이클이 생겼다.
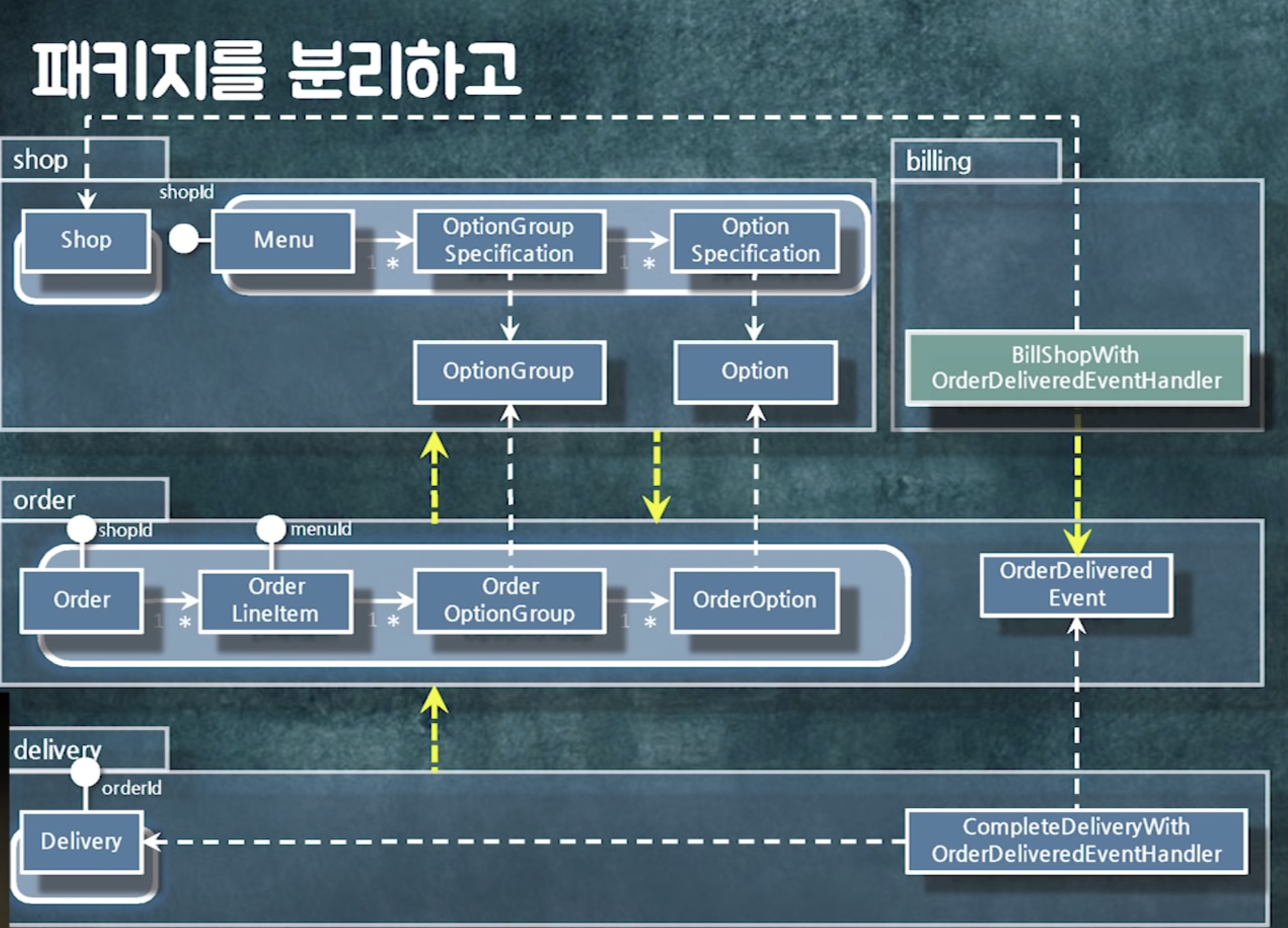

패키지를 분리하고
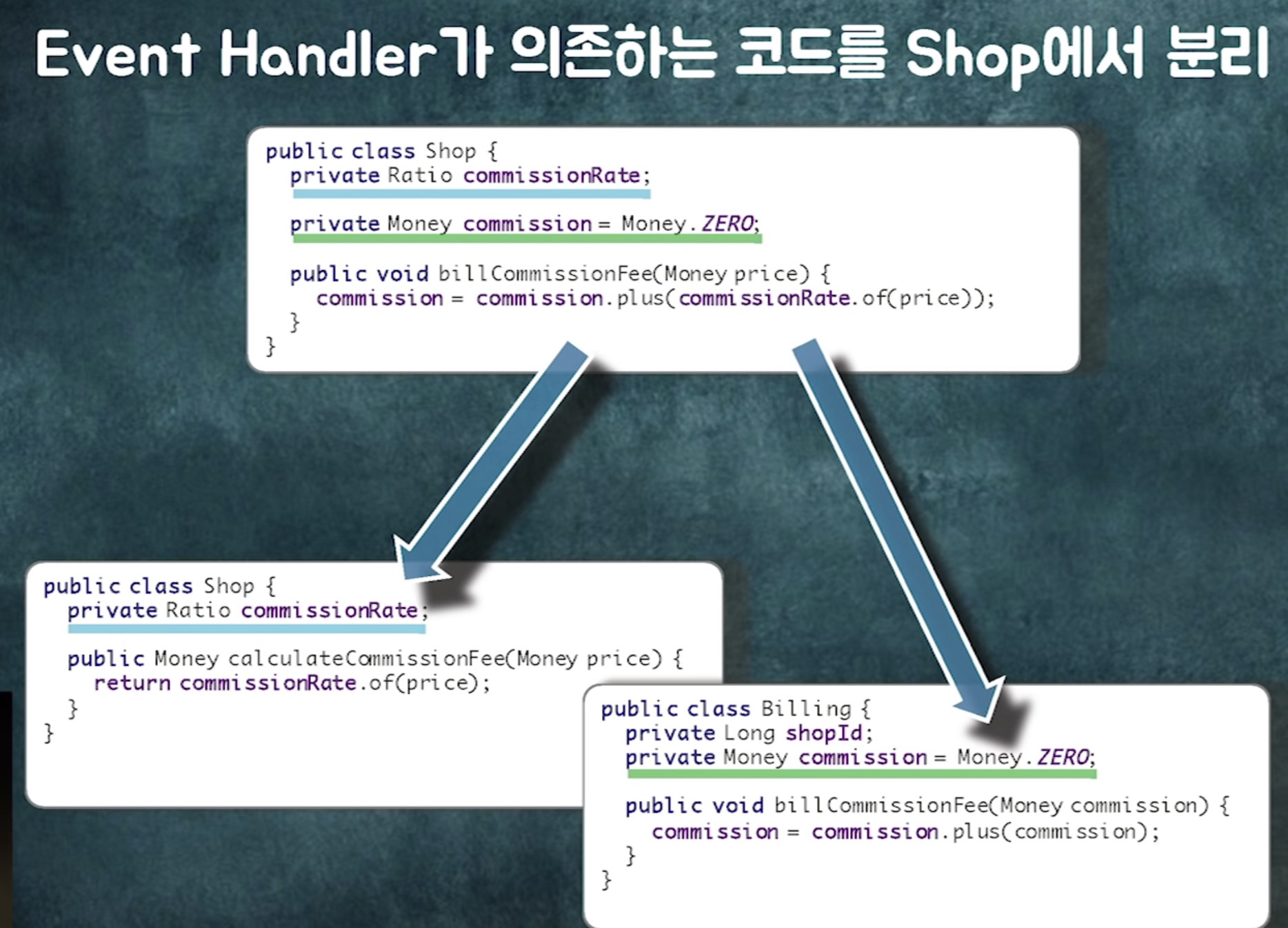
shop에 있던 로직 둘로 분리 ( billing 로직을 띄어냄)
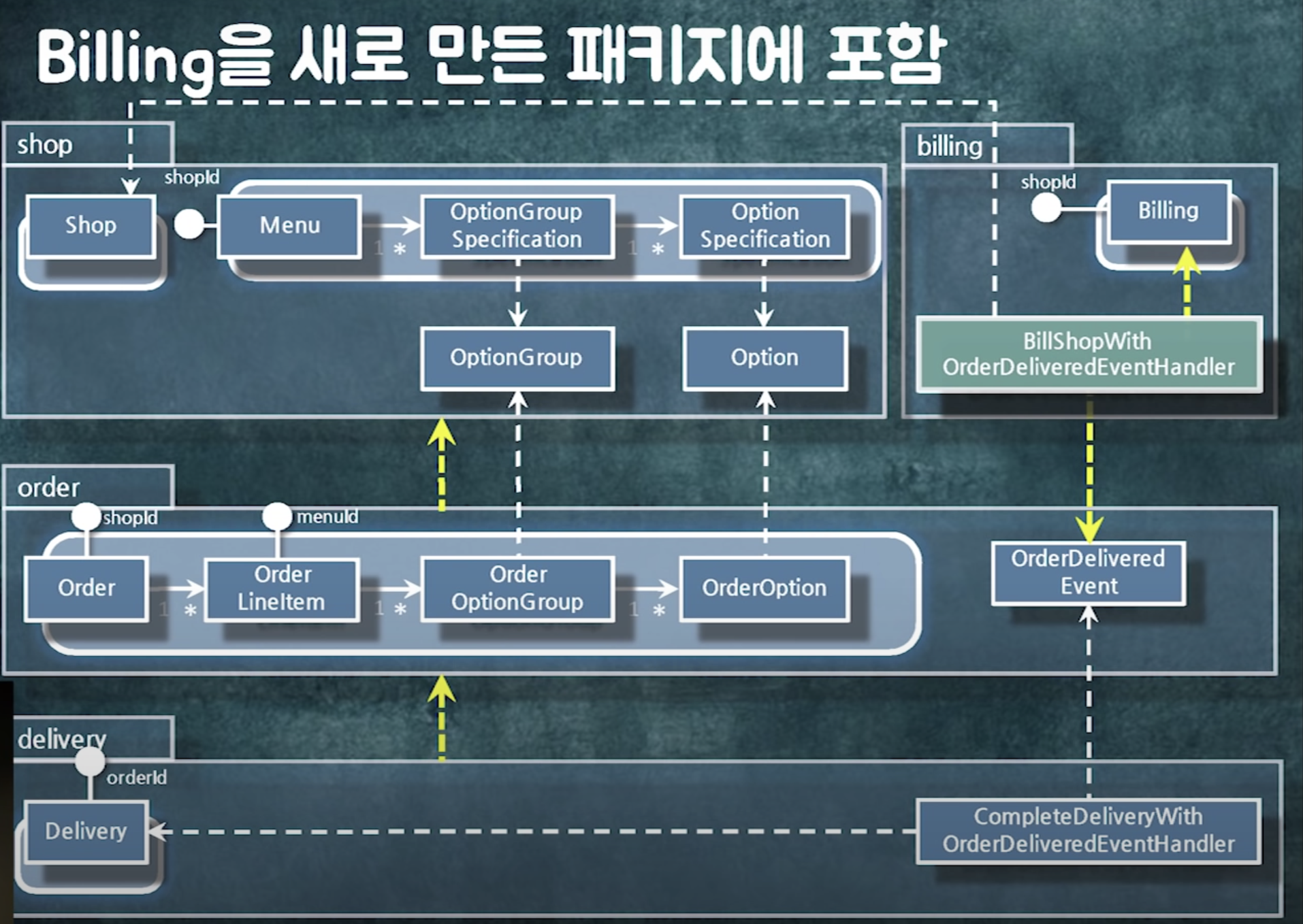
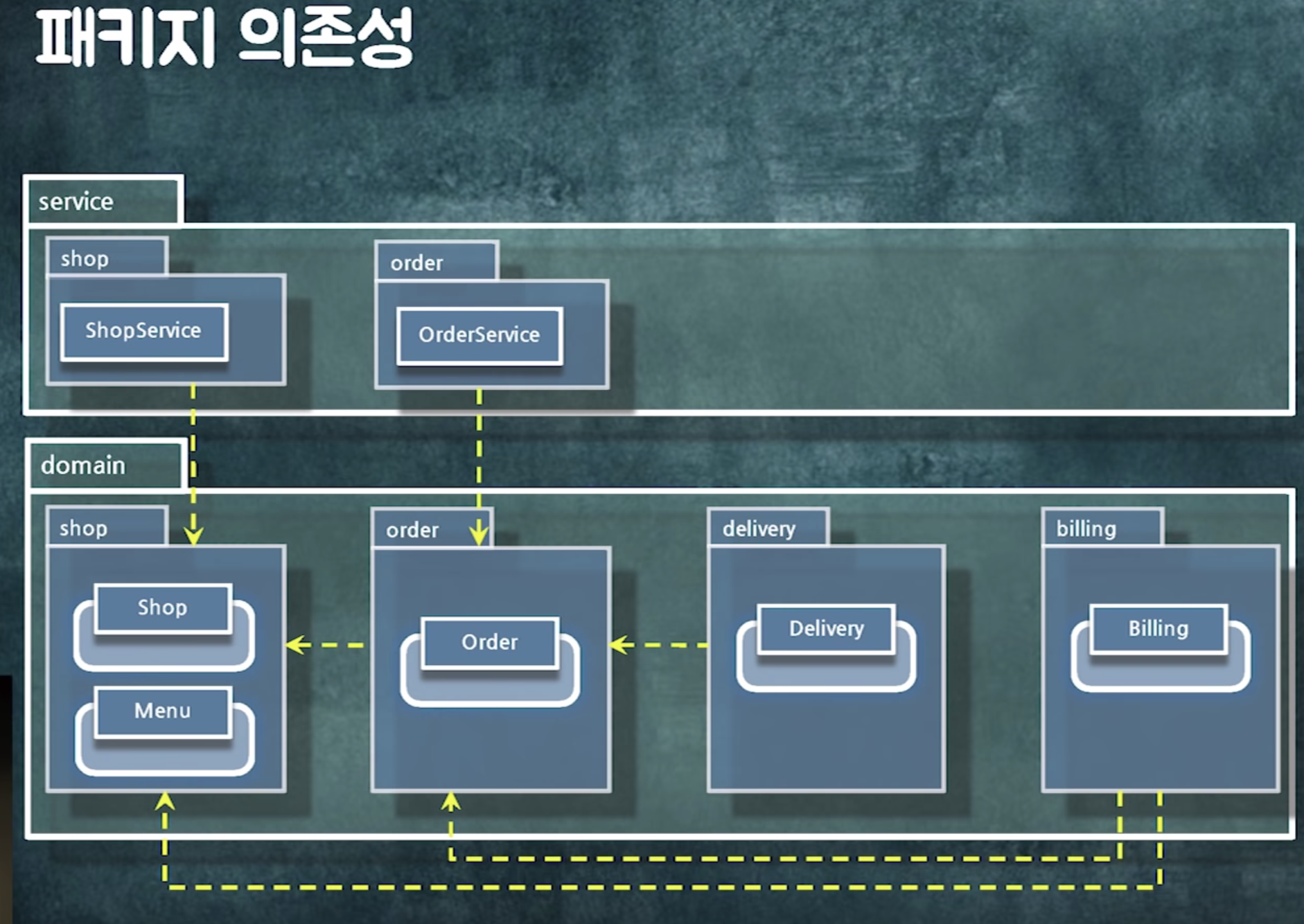
패키지를 찢을 때에는 도메인적으로 뭔가 명확한 새로운 개념이 필요할 떄 찢어야함.
dependency를 쫓아가다보면 도메인을 보는 관점이 바뀔때가 많음
< 패키지 의존성을 끊는 3가지 방법>
1) 중간객체를 만들기
2) 인터페이스나 추상클래스를 이용한 의존성 역전
3) 새로운 패키지
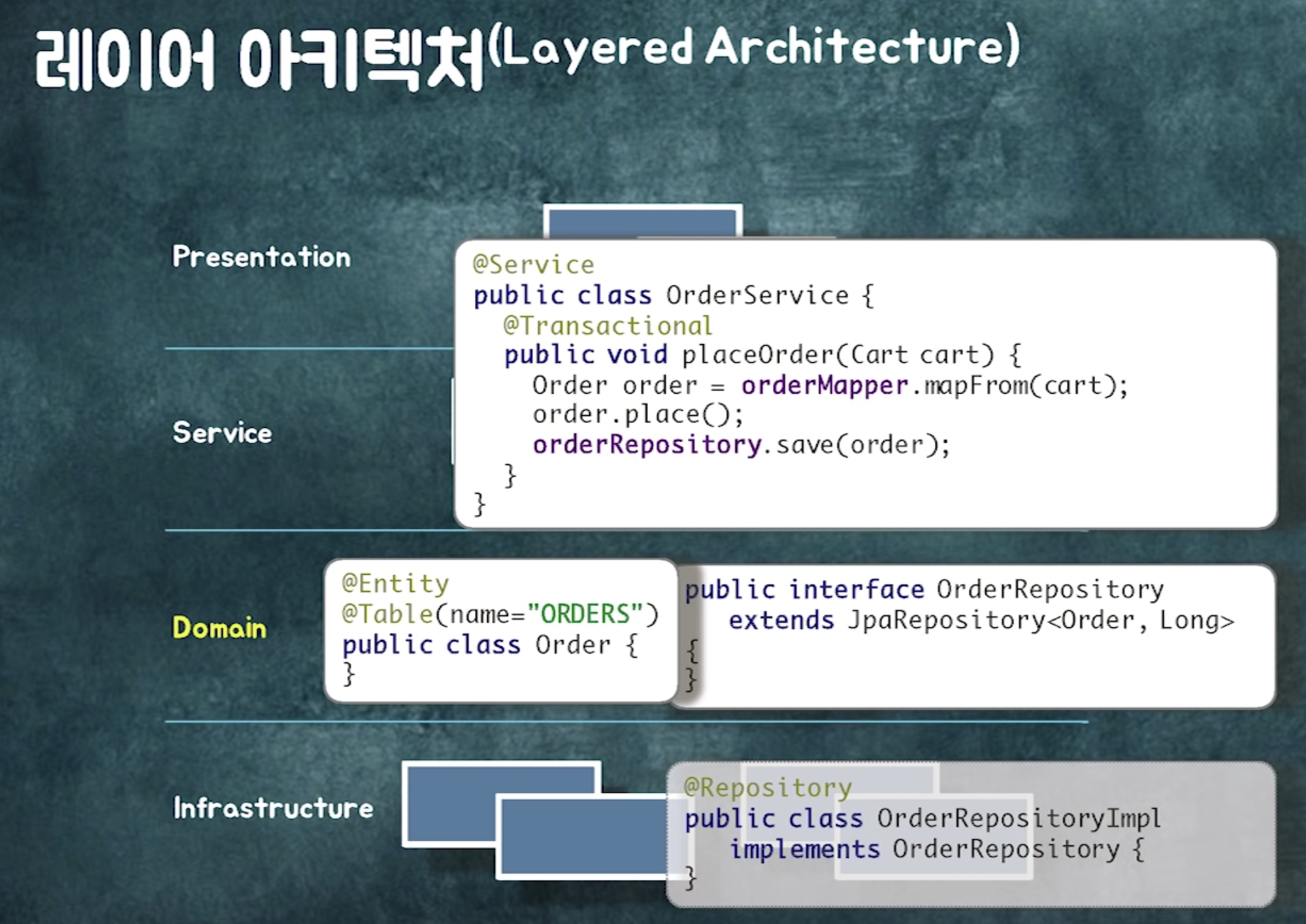
📍 의존성과 시스템 분리
의존성을 관리하다보면 시스템을 쉽게 분리할 수 있다
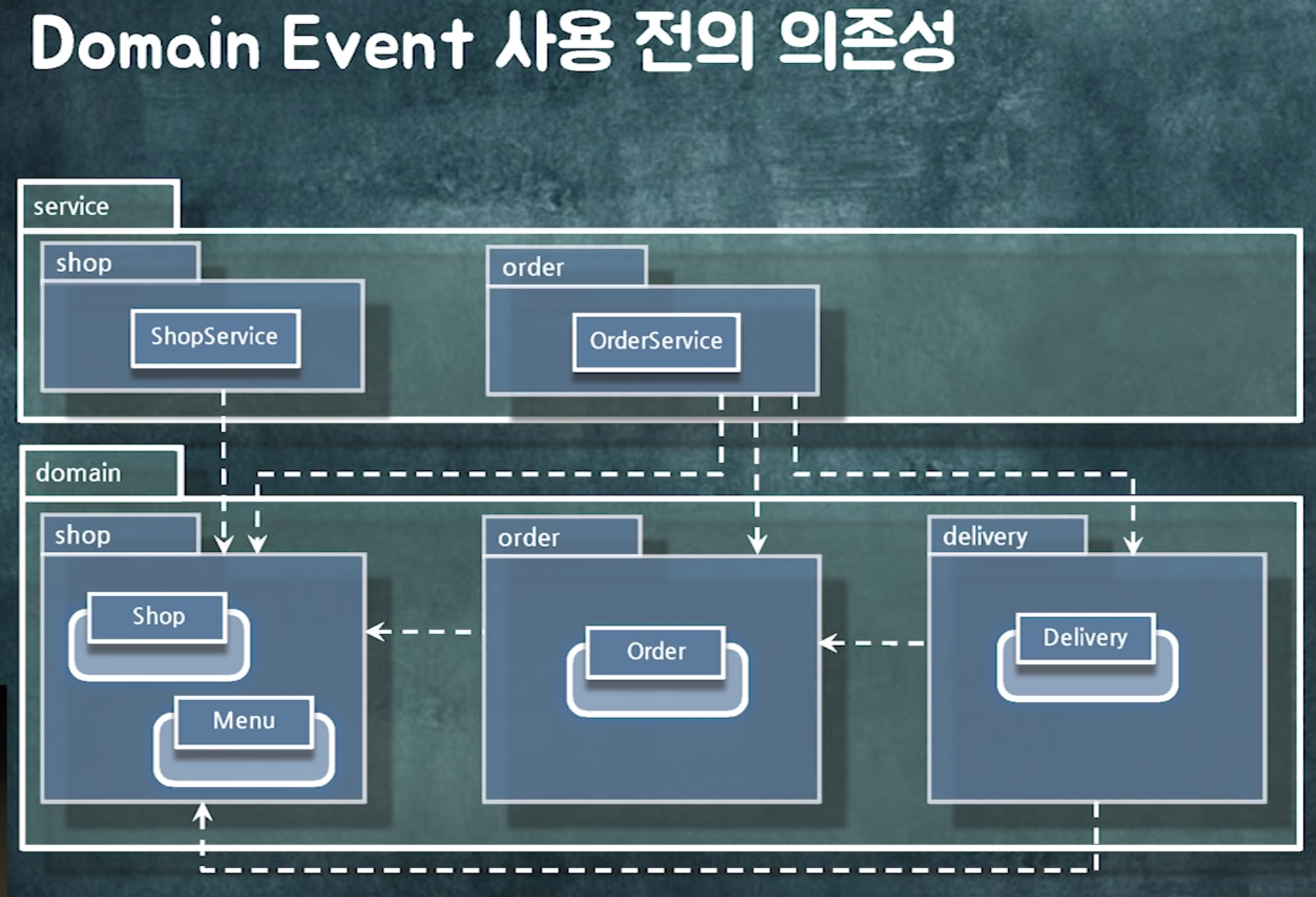
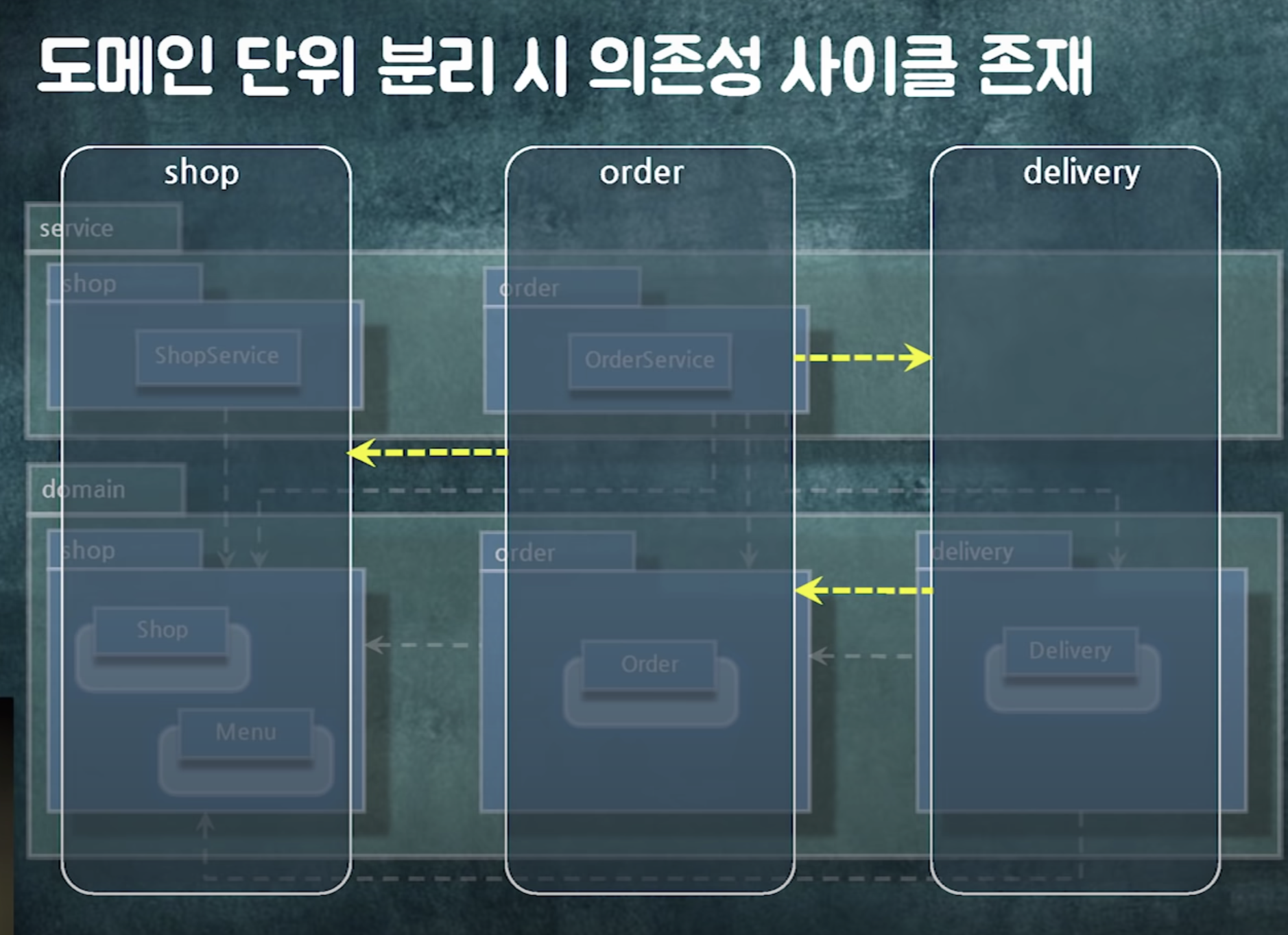
레이어로 단위로 찢음
왜? 도메인단위로 분리하면 사이클 생겨서
(dependcy관리가 안되어있을 때는 도메인 단위로 패키지 나누면 장난없다)
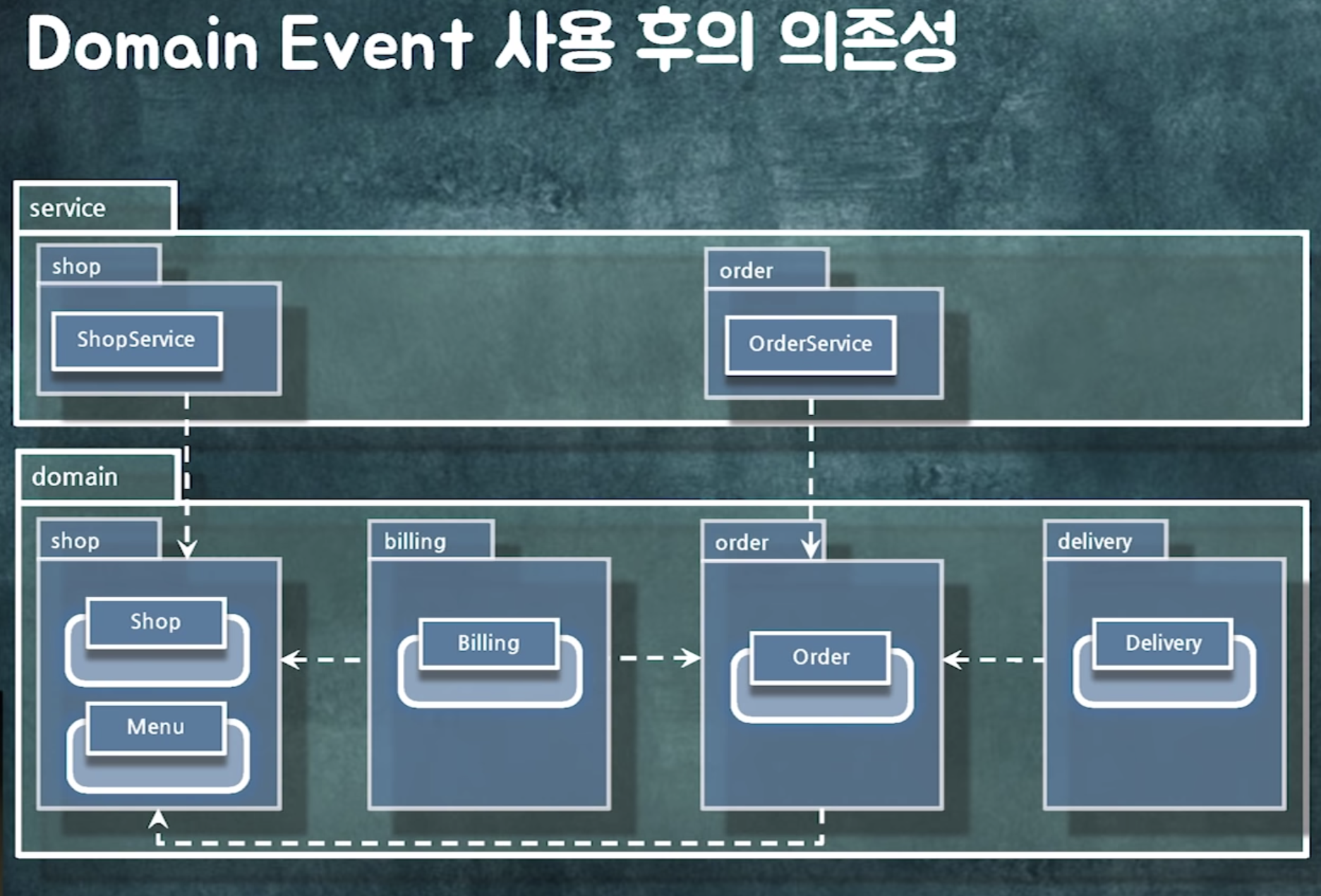
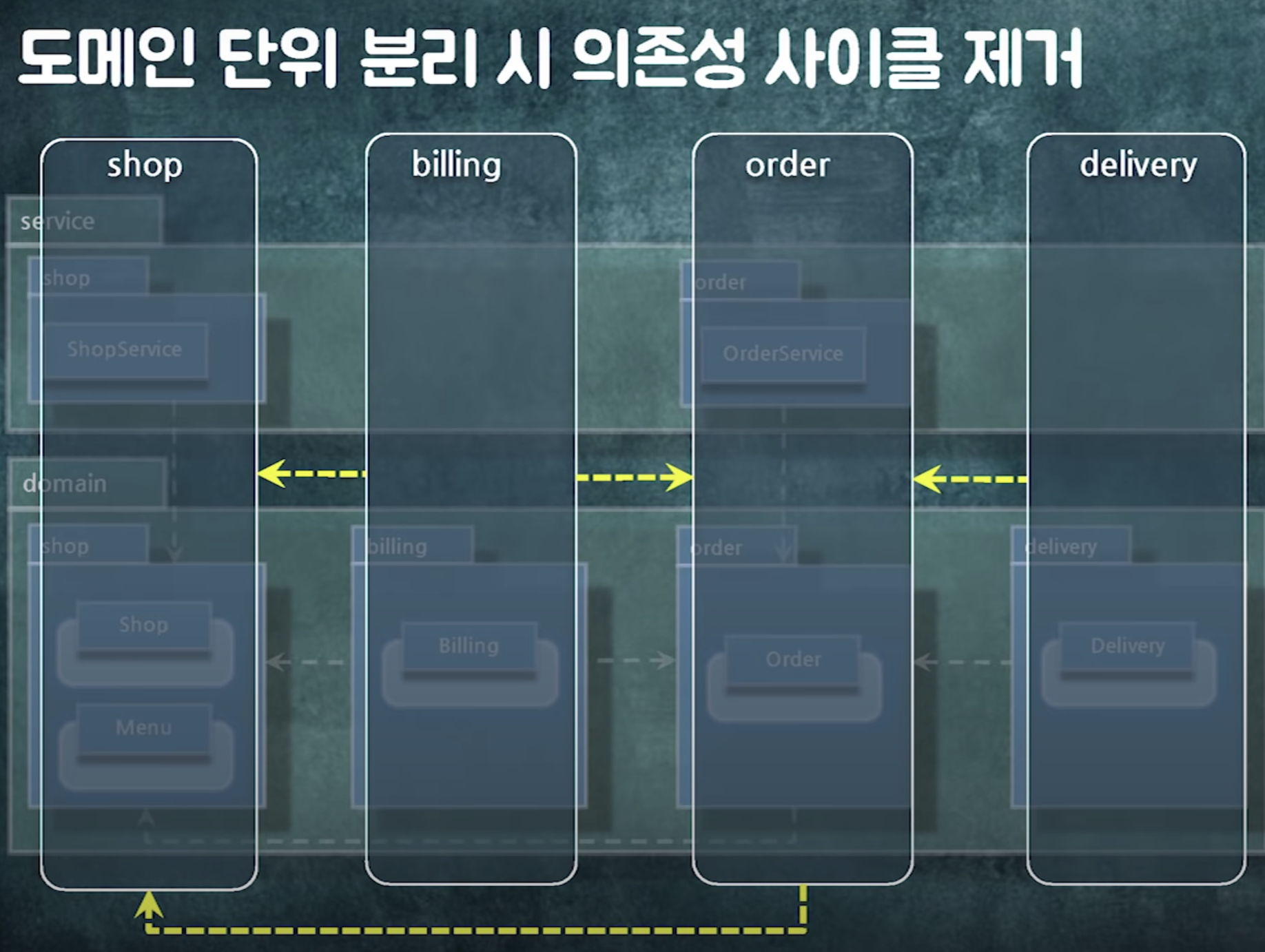
의존성을 관리하고 나면
도메인 단위로 분리해도 사이클 없음
-> 도메인 단위로 모듈화 가능
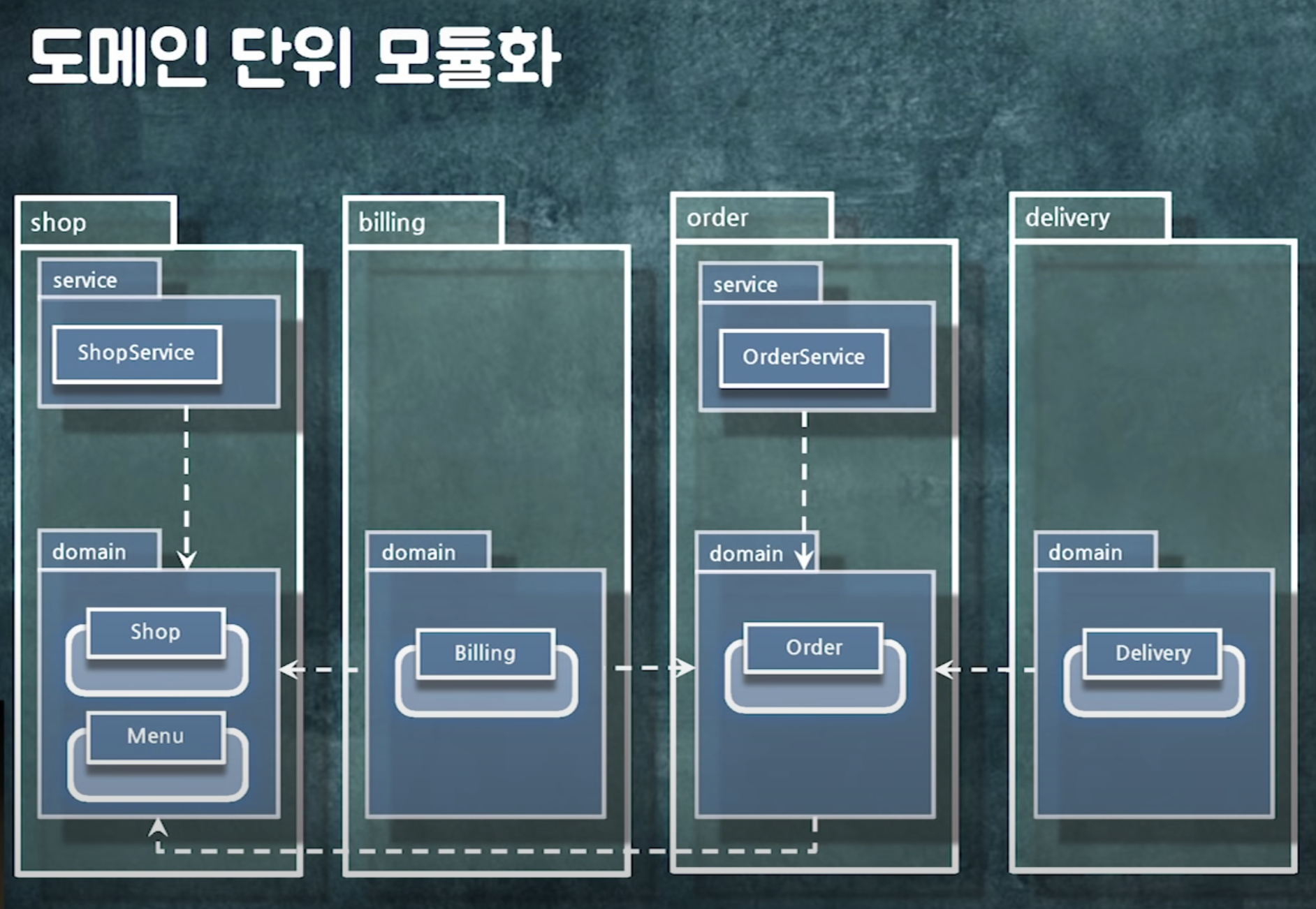
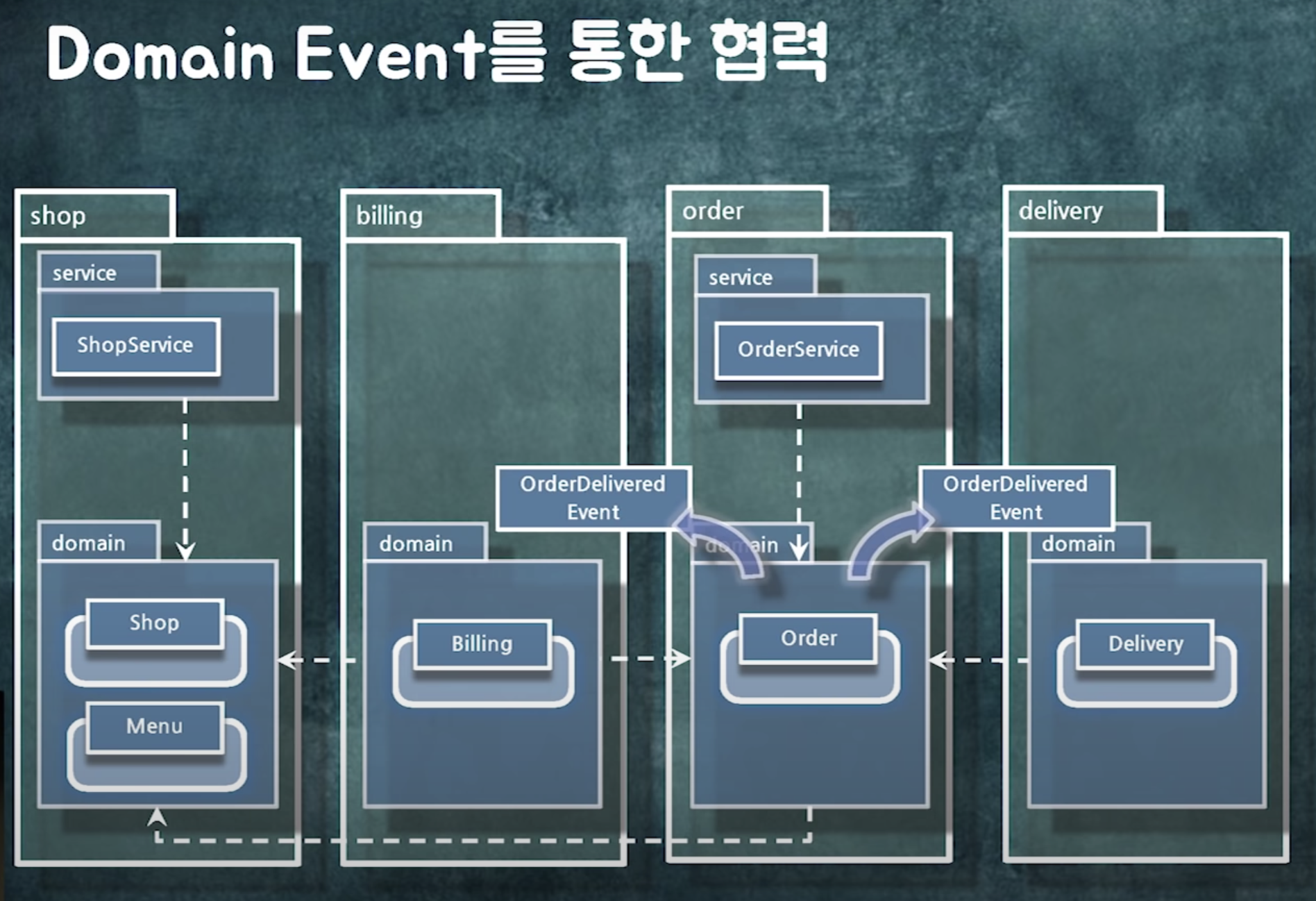
도메인 단위로 모듈화 해두면 시스템 분리가 편하다!
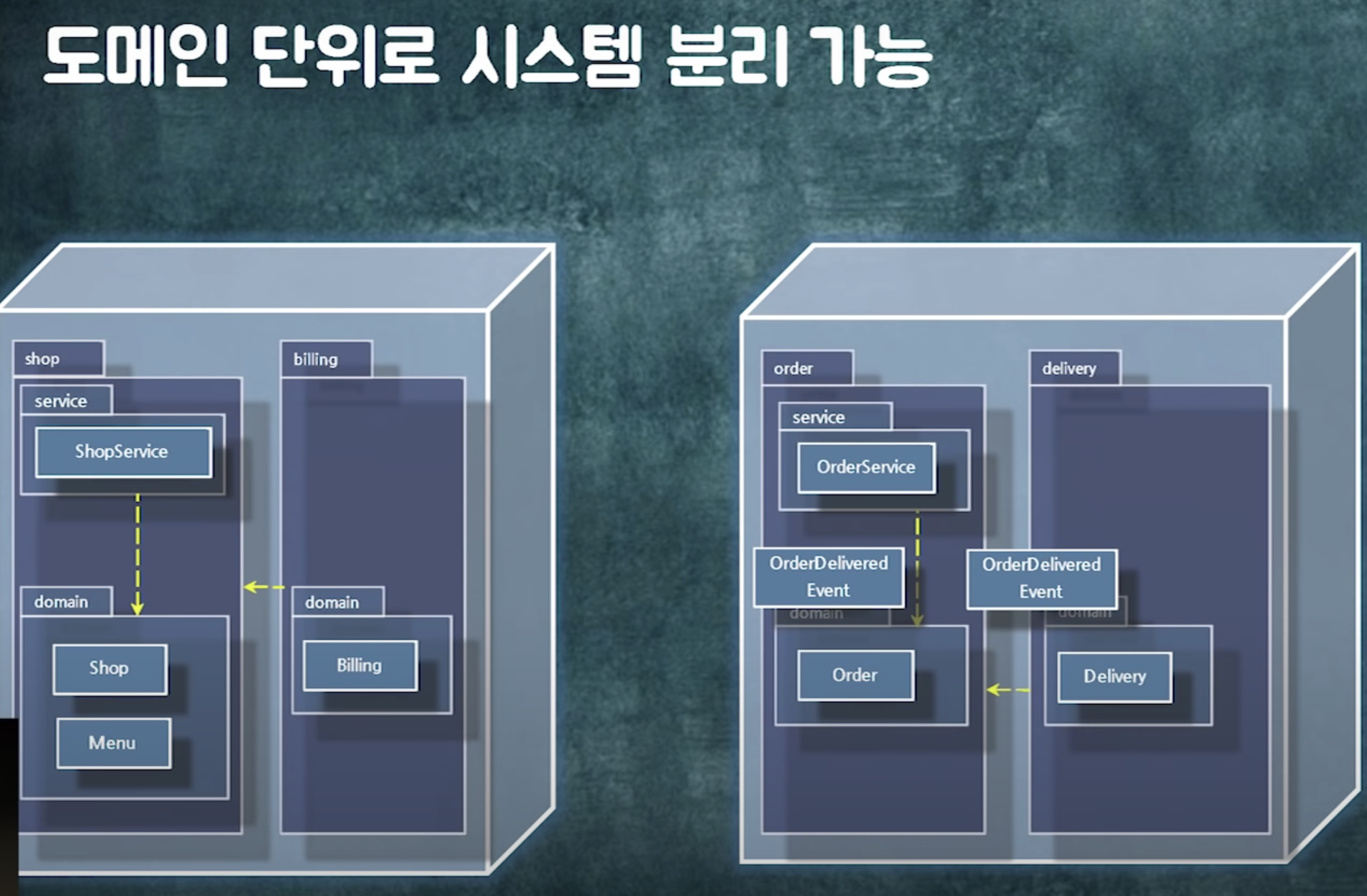
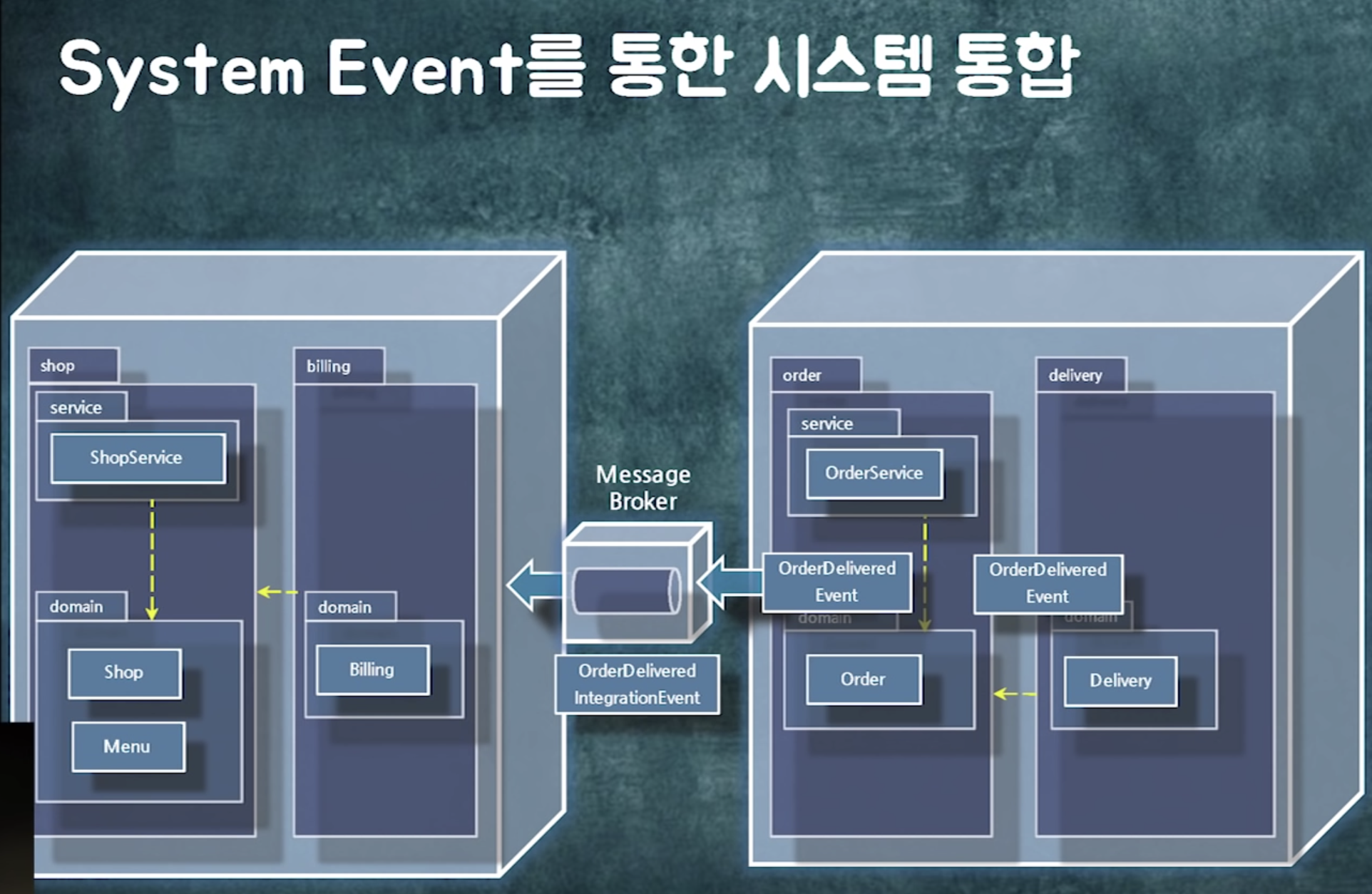
시스템 내부에서 쓰이는건 internal event(domain event)
메시지 등을 이용해 외부로 나가는건 external event(system event)
시스템 내부에서 도는 event는 객체참조해도 됨 (물론 lazy loading 이슈가 있겠지만)
외부는 serialization을 해야함
여튼 internal event를 external event로 바꿔서 메시지큐에 넣어둠으로서 시스템간 통신 가능!
2. 제이슨의 [도메인 원정대] 강의를 들었다.
https://www.youtube.com/watch?v=kmUneexSxk0
어려워 ㅎ 뭔말인지 잘 모르겠다.
개발 경험이 쌓이면 이해가 될까?
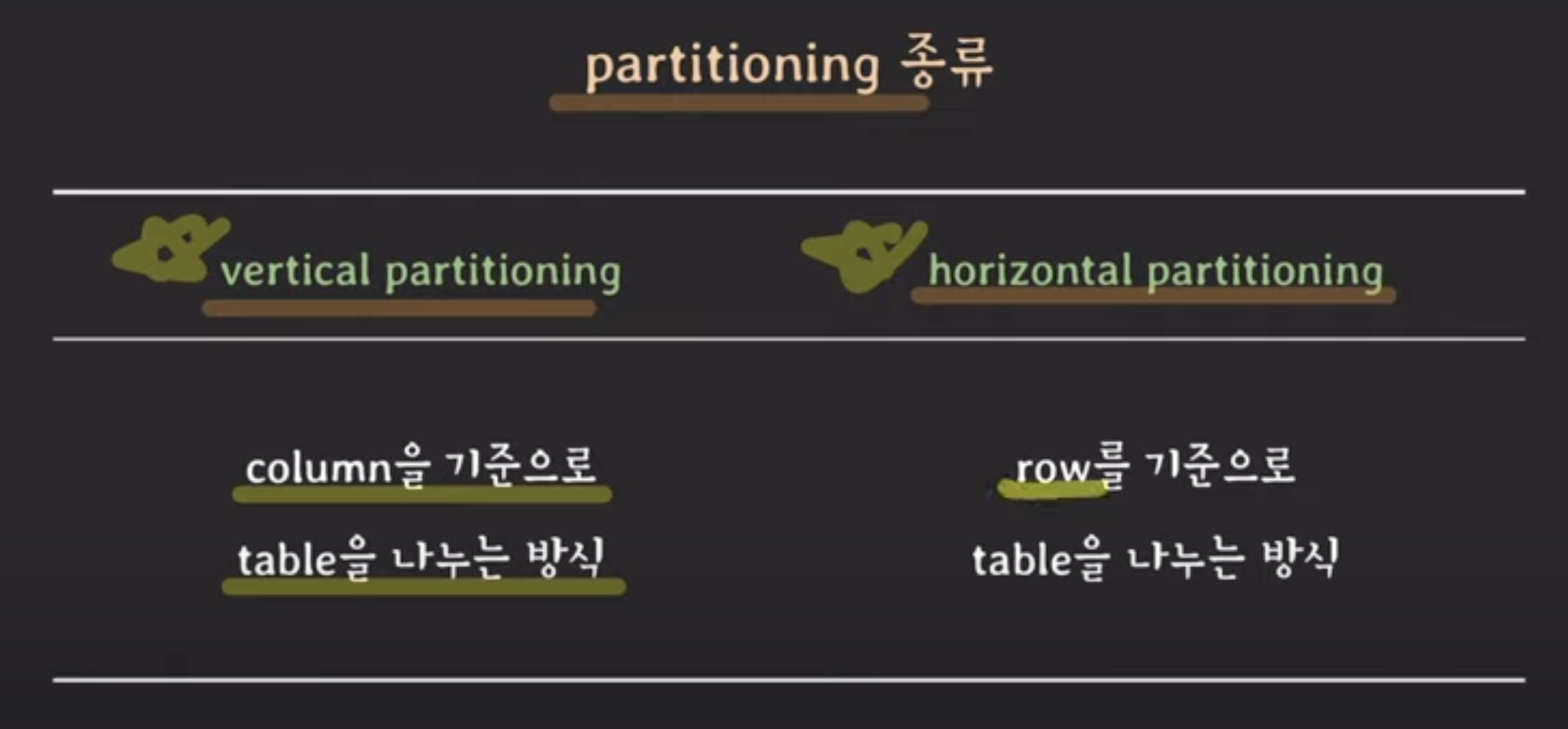
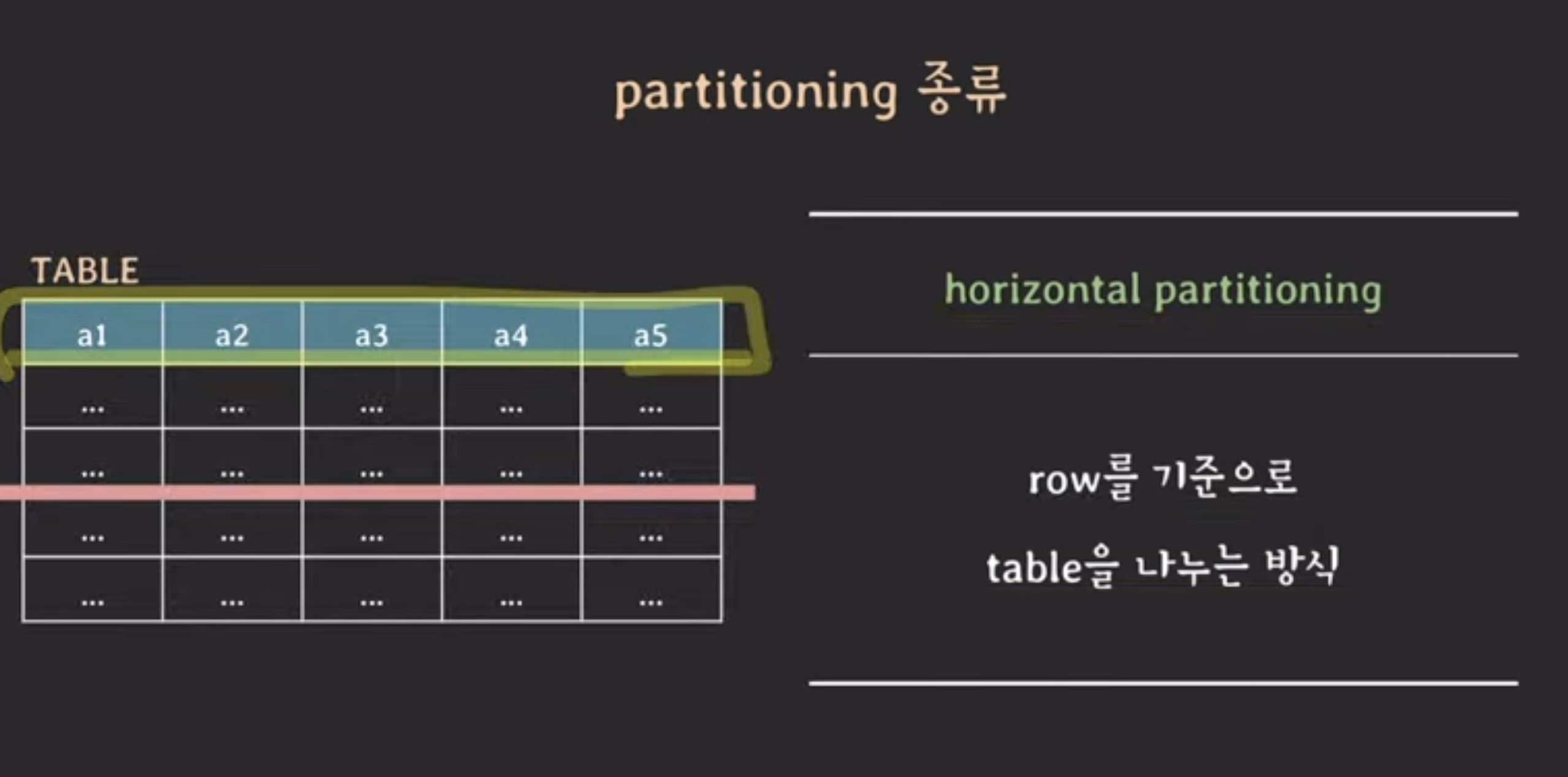
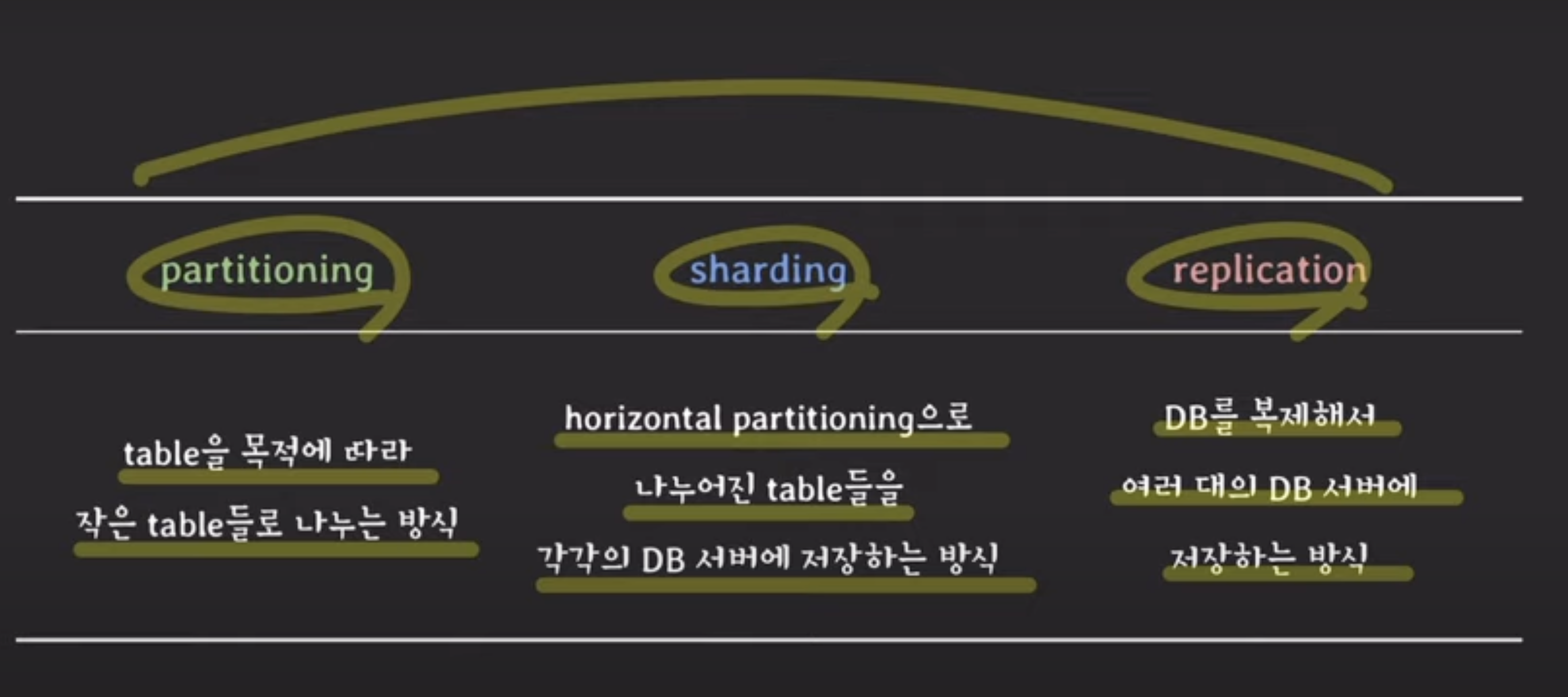
3. 파티셔닝 vs 샤딩 vs 레플리케이션
📍 파티셔닝 : DB table을 더 작은 table로 나누는 것
(정규화도 vertical partitioning)
1) vertical partitioning
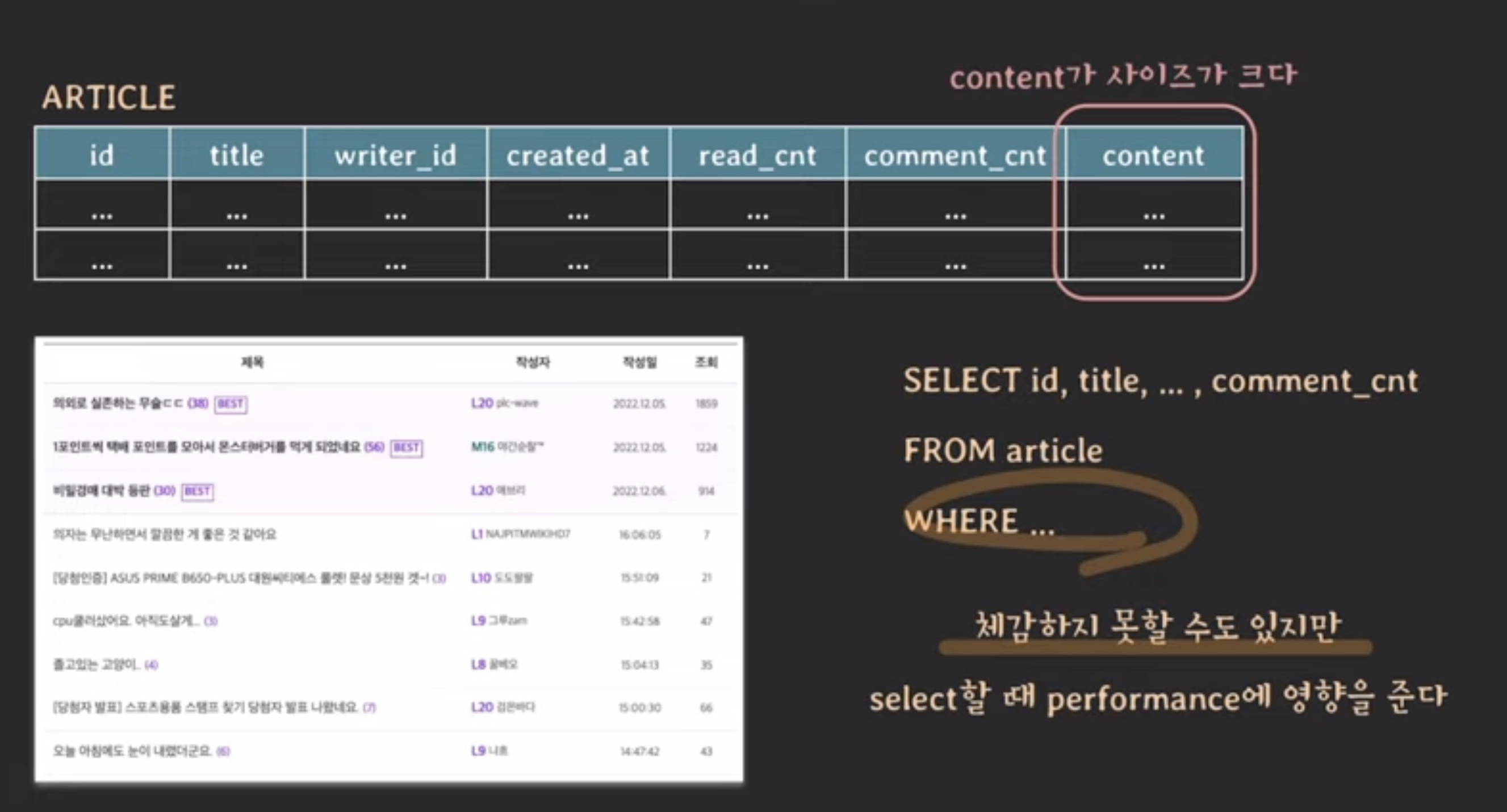
select id, title, ...comment_cnt만 하더라도
일단 content까지 포함한 row 전체를 읽어오기 때문에 성능에 영향을 준다
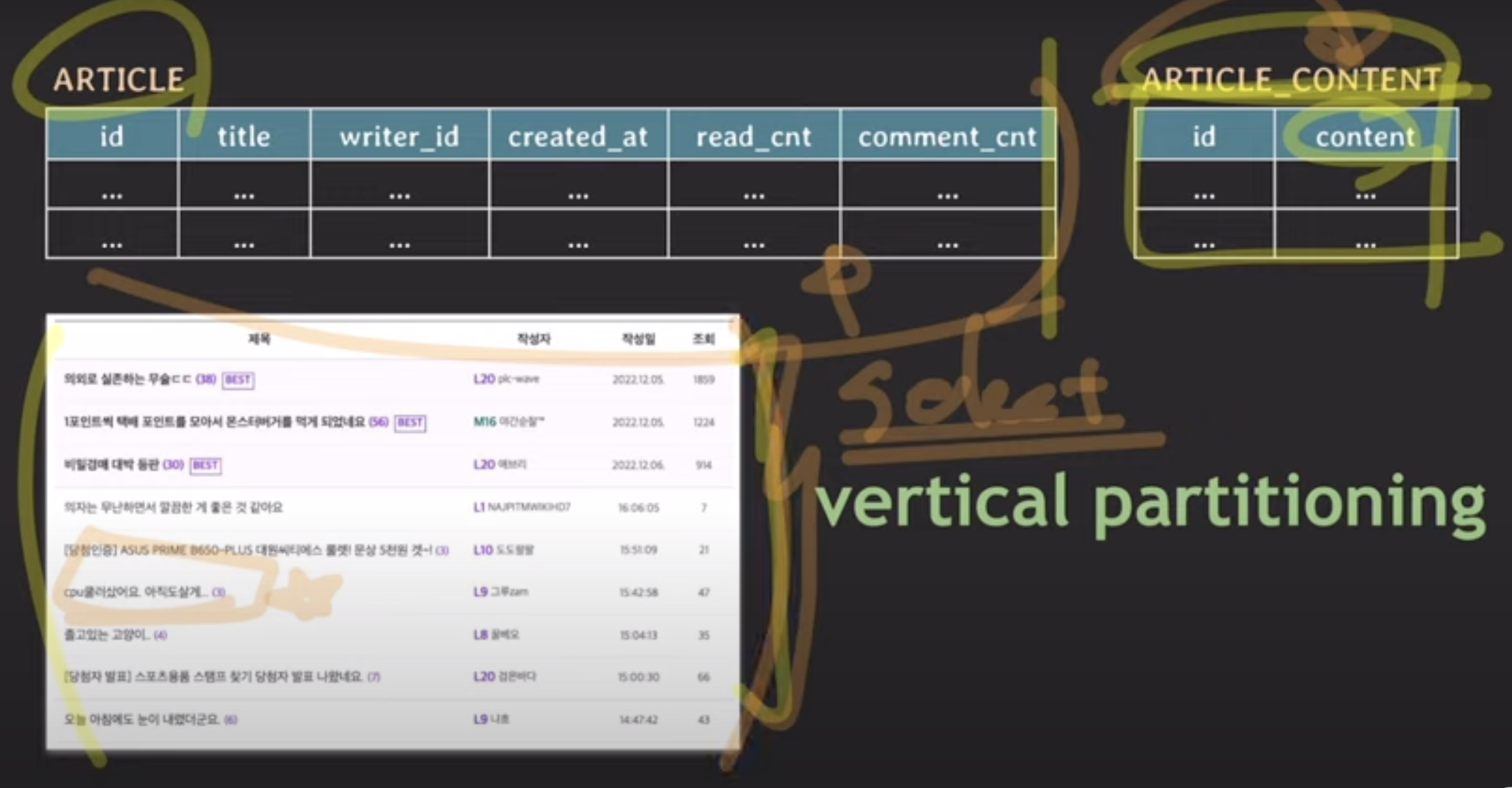
-> content만 따로 테이블 분리
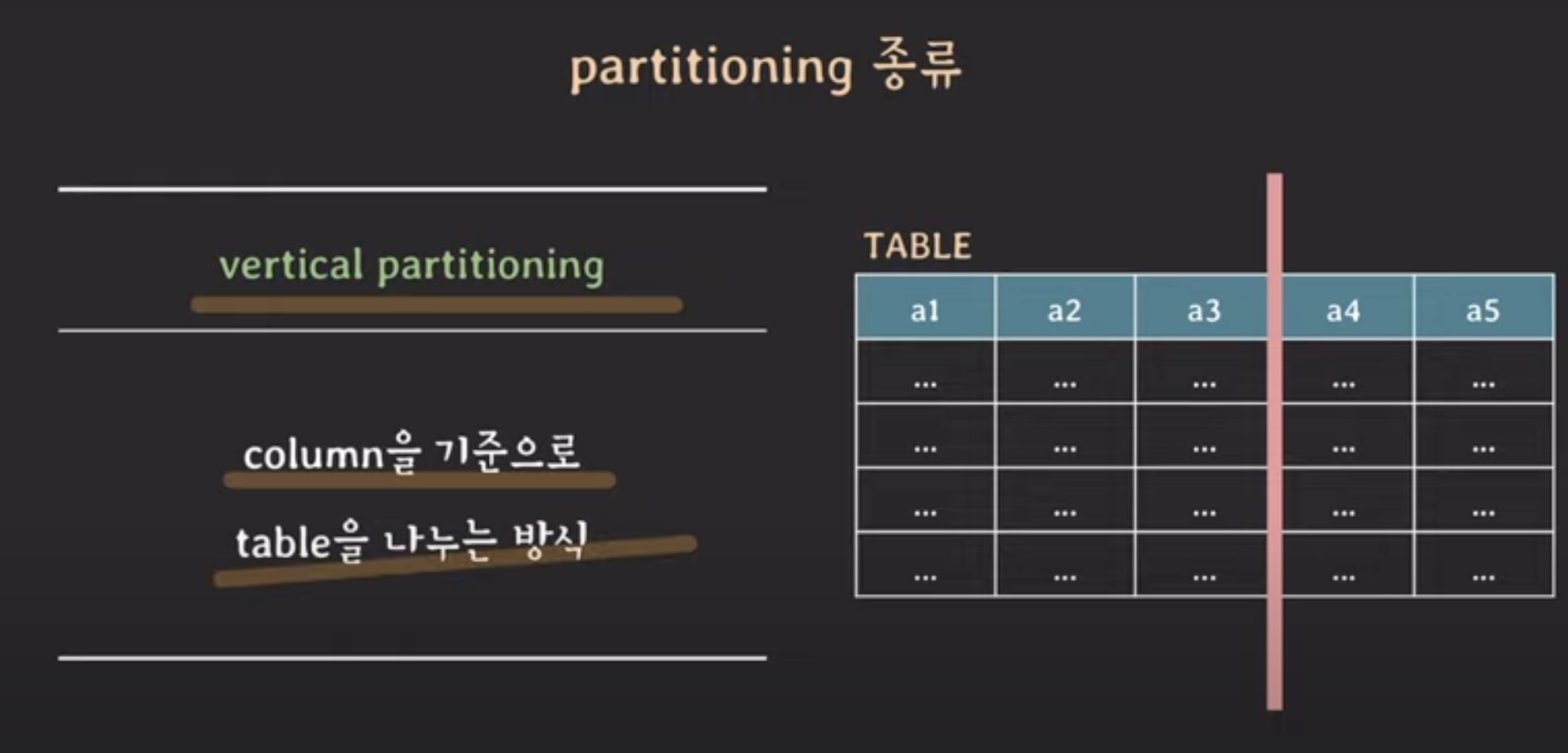
vertical partitioning : schema 바뀜
horizontal partitioning : schema 유지
2) horizontal partitioning

-> 데이터 나눠 넣기
horizontal partitioning에는 hase-based, range-based 등 많은 방식이 존재!
hased-based horizontal partitioning
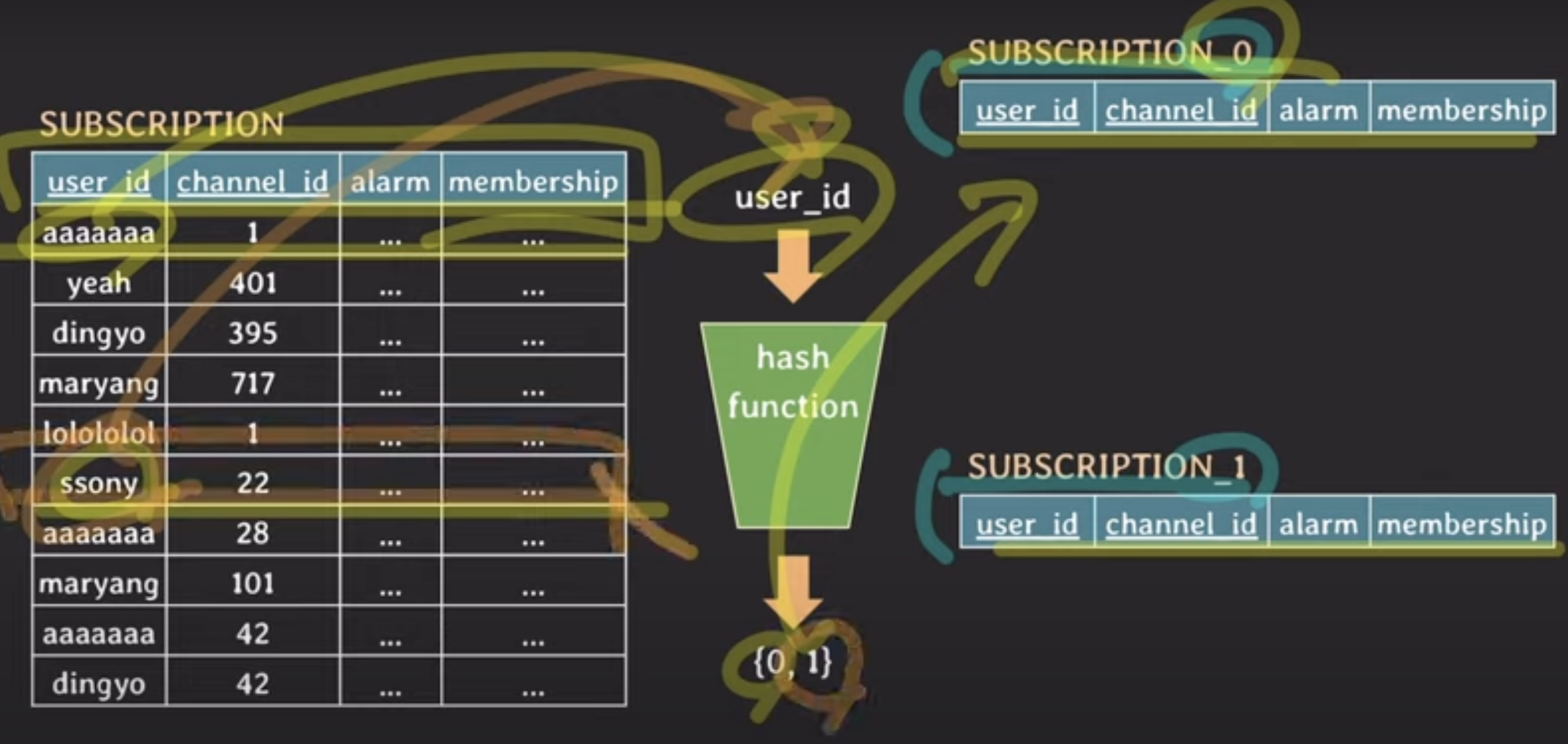
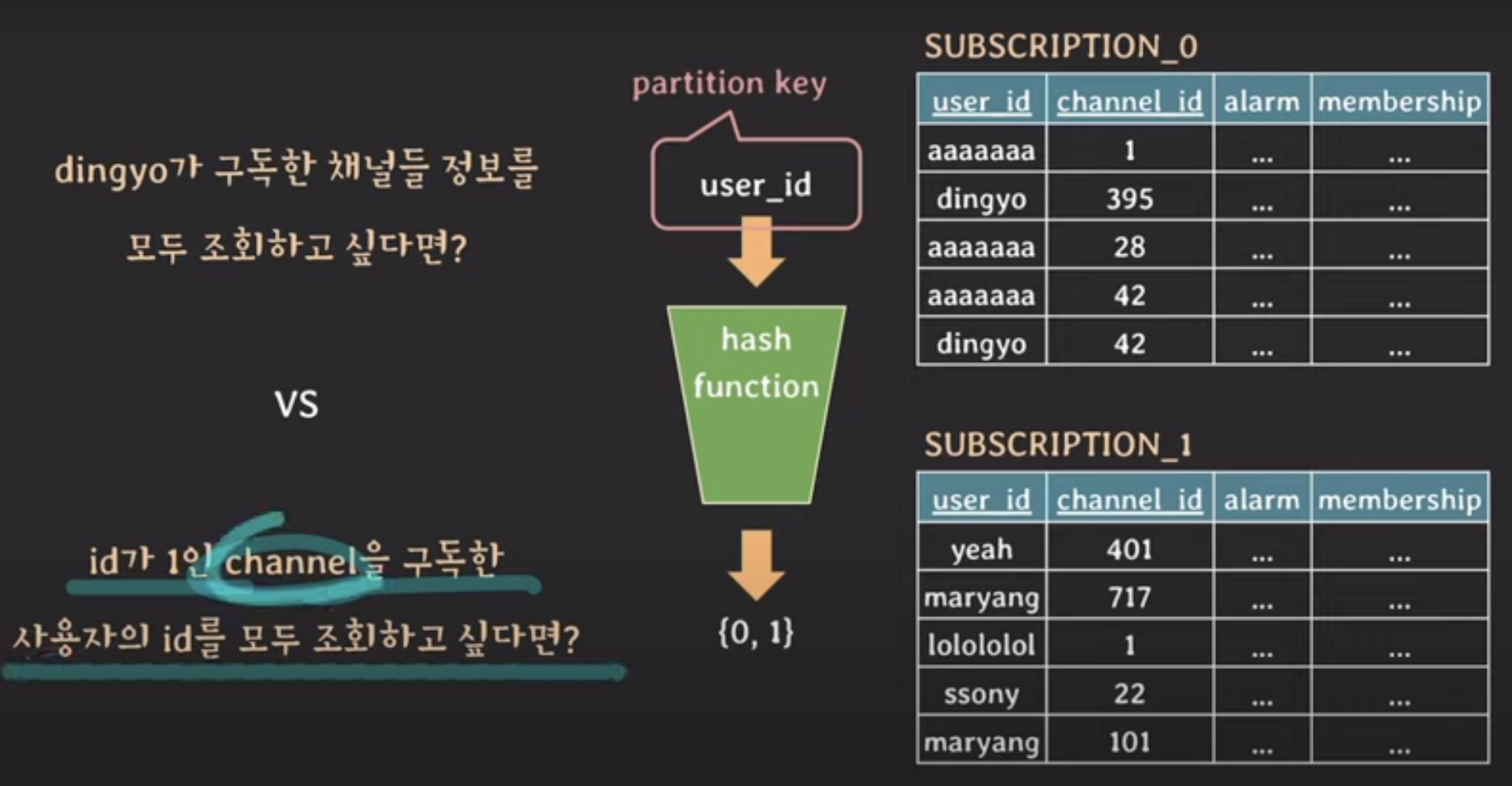
가장 많이 사용될 패턴에 따라 partition key를 정하는 것이 중요!!!!!!!!!!!!
데이터가 균등하게 분배될 수 있도록 hash function을 잘 정의하는 것도 중요!!!!!!!!!
+) hased-based horizontal partitioning은 한번 partition이 나눠져서 사용되면 이후에 partition을 추가하기 까다롭다
📍 샤딩 : horizontal partitioning처럼 동작 + 각 partition이 독립된 DB서버에 저장


- partition key를 shard key라고 부름
- 각 partition을 shard라고 부름
📍 레플리케이션
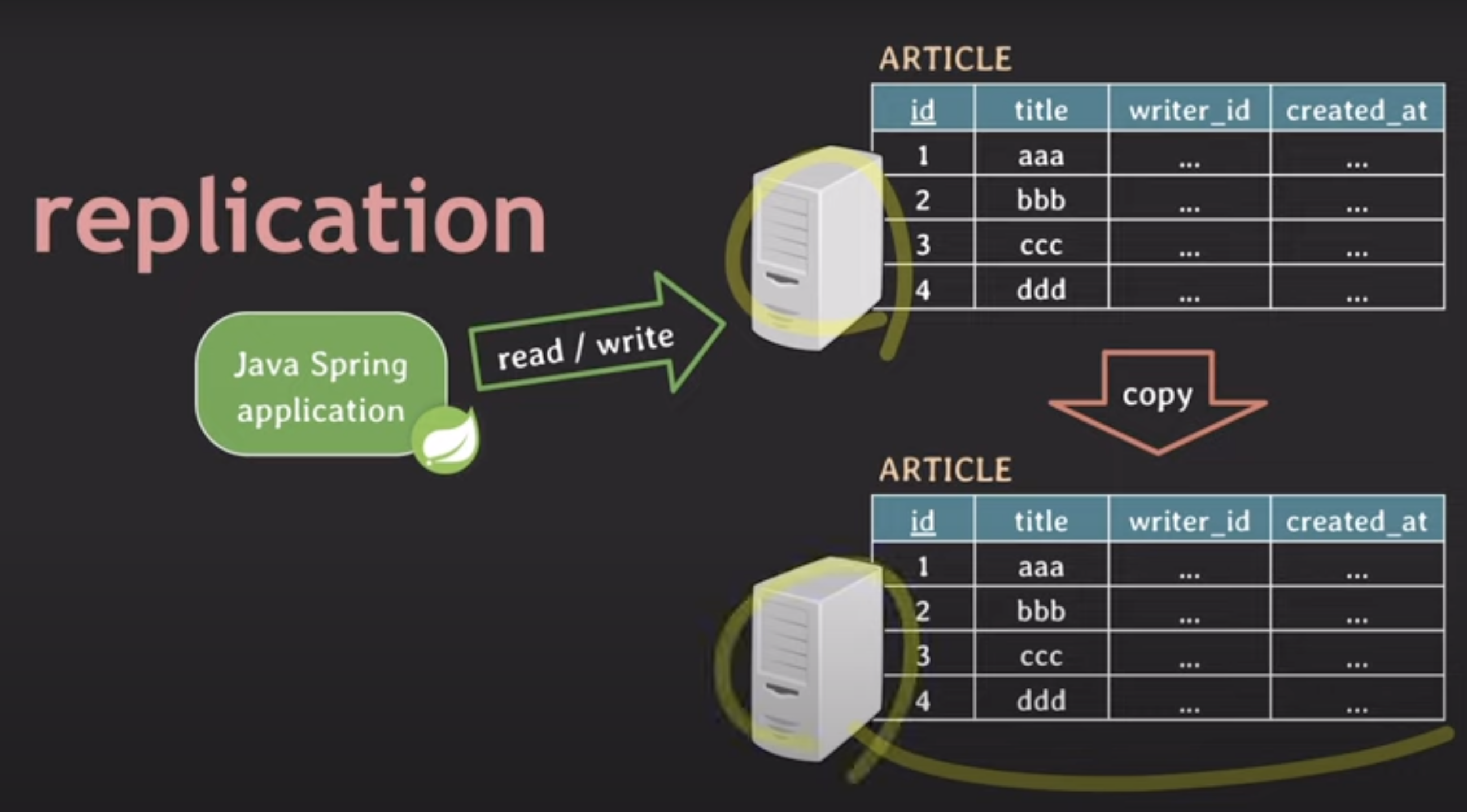
- master에 문제 생기면 slave가 처리 -> HA(High Availability)
- 서버 부하(load)를 낮춘다
~정리~
참고로 얘네 모두 NoSQL에도 적용가능한 개념!
4. DBCP(DB Connection Pool)
https://www.youtube.com/watch?v=zowzVqx3MQ4&list=PLcXyemr8ZeoT-_8yBc_p_lVwRRqUaN8ET&index=62
이 영상 레전드.
성능 테스트? 부하 테스트?할 때 좀 막막했는데 뭔가 갈피가 잡히는 것 같다. 최고..!!
📍 Connection
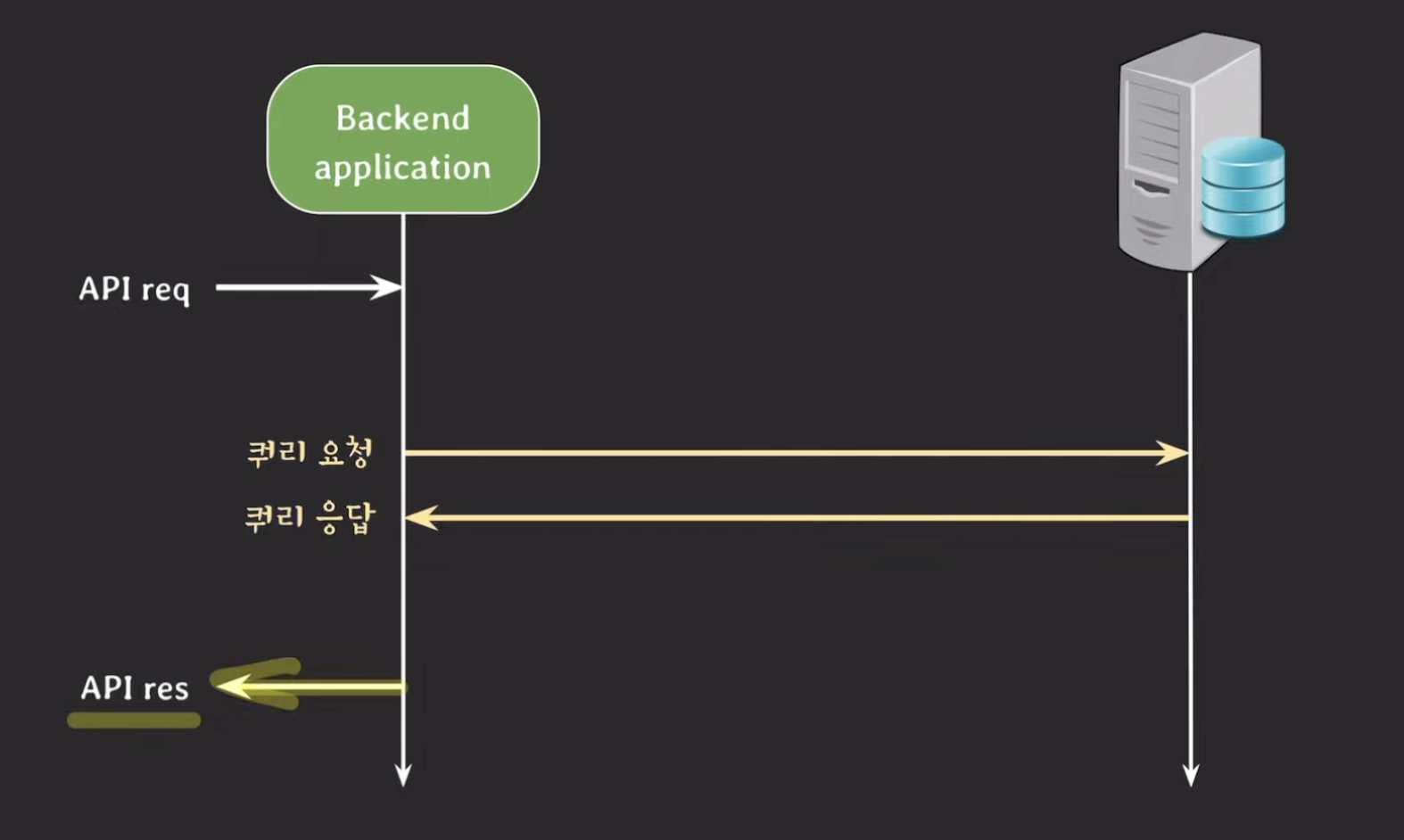
백엔드 서버와 db서버는 각각 서로 다른 컴퓨터에서 동작 -> 네트워크 통신
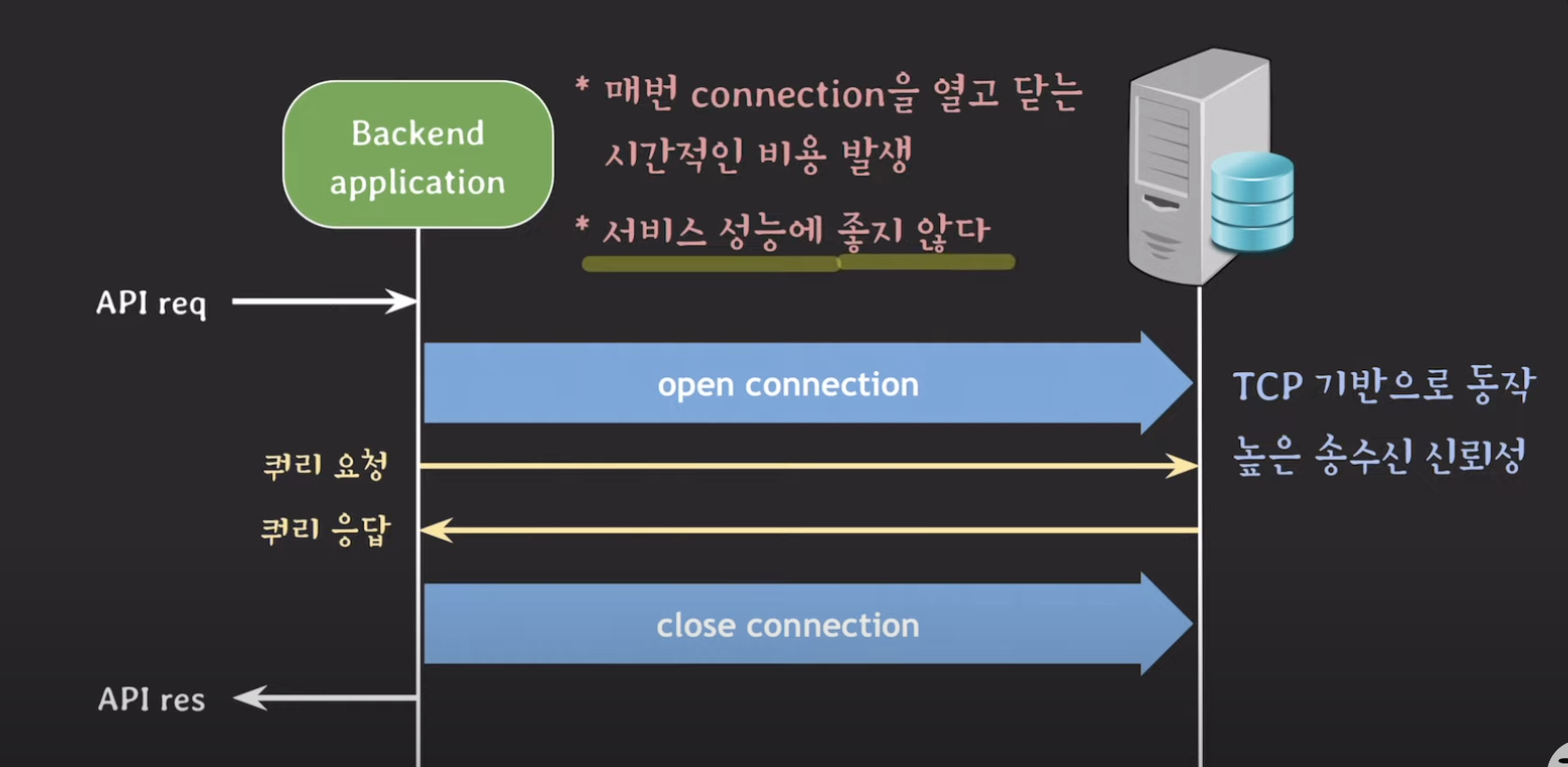
TCP기반으로 통신. TCP는 연결지향적 -> 본격적 통신 전에 연결을 맺고, 데이터 송수신 끝난 다음 연결을 끊어주는 과정 필요
커넥션 열고 닫는 과정이 복잡 (열때는 3way handshake, 닫을 때는 4way handshake) -> 시간 잡아먹음
=> DBCP 등장
📍 DBCP
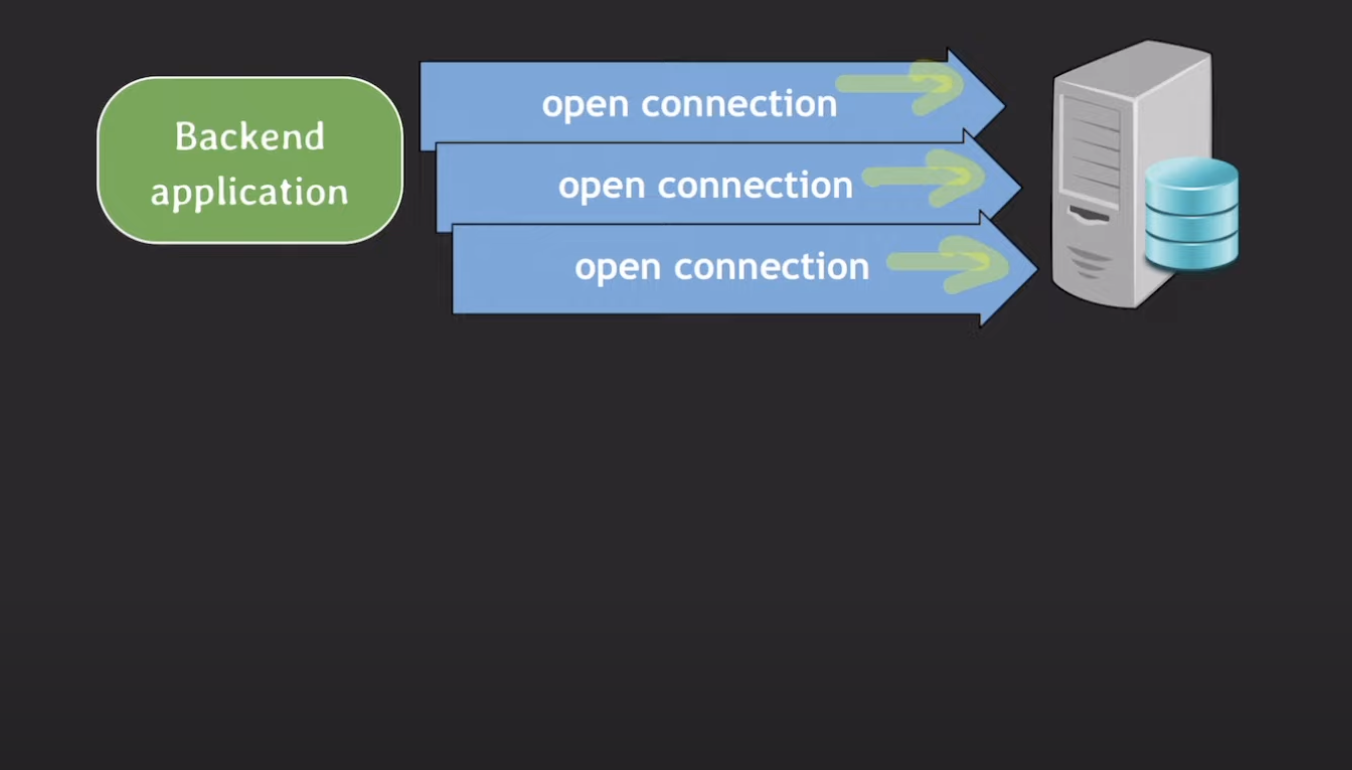
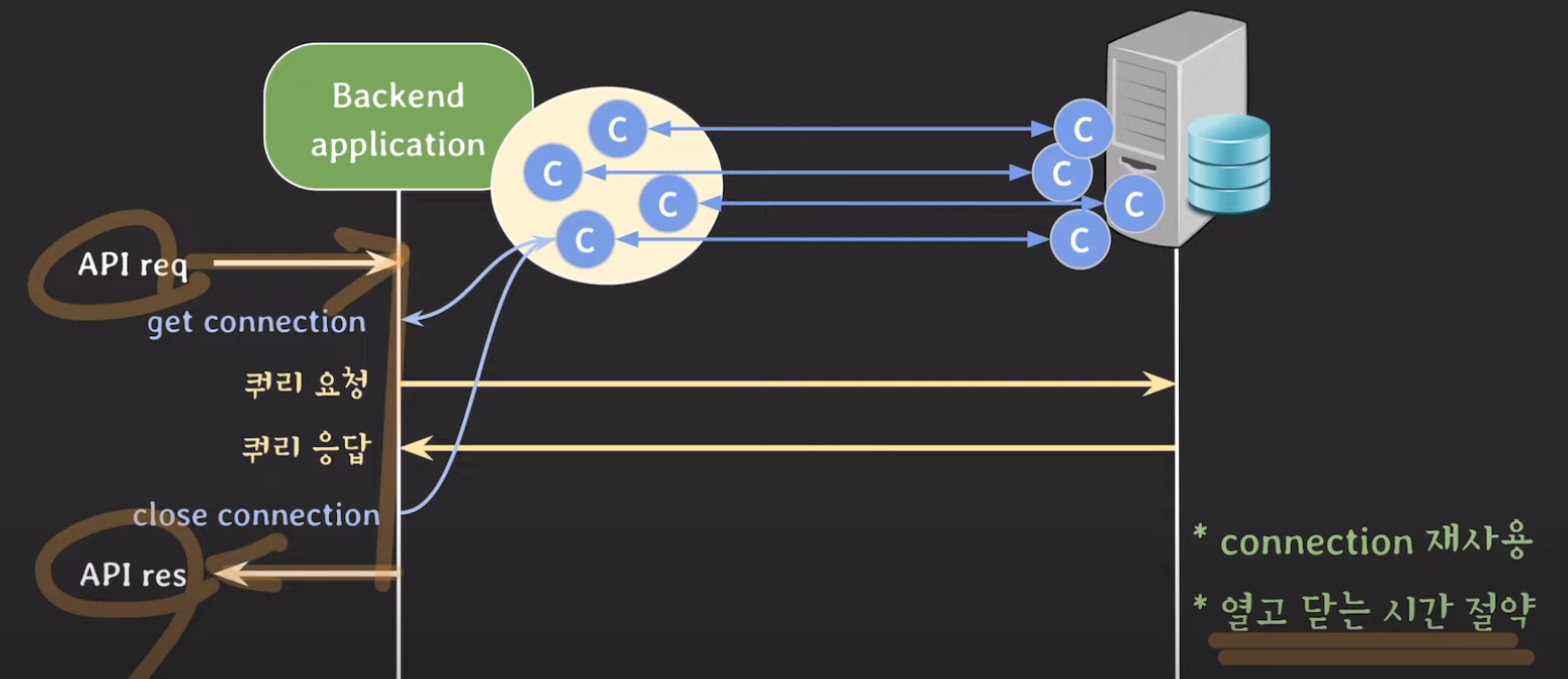
백엔드 어플리케이션이 뜰때, db connection을 미리 만들어서 풀처럼 세팅
-> db 조회가 필요할 때마다 connection을 새로 만드는 것이 아닌, 풀에서 connection 가져와서 씀
+) connection을 여러 개 만들어서 pool에 저장하고 재사용하는 이 방식은 DB와 연결할 때뿐만 아니라 자주 네트워크 통신할 일이 있는 그 어떤 존재와도 사용할 수 있는 방식이다
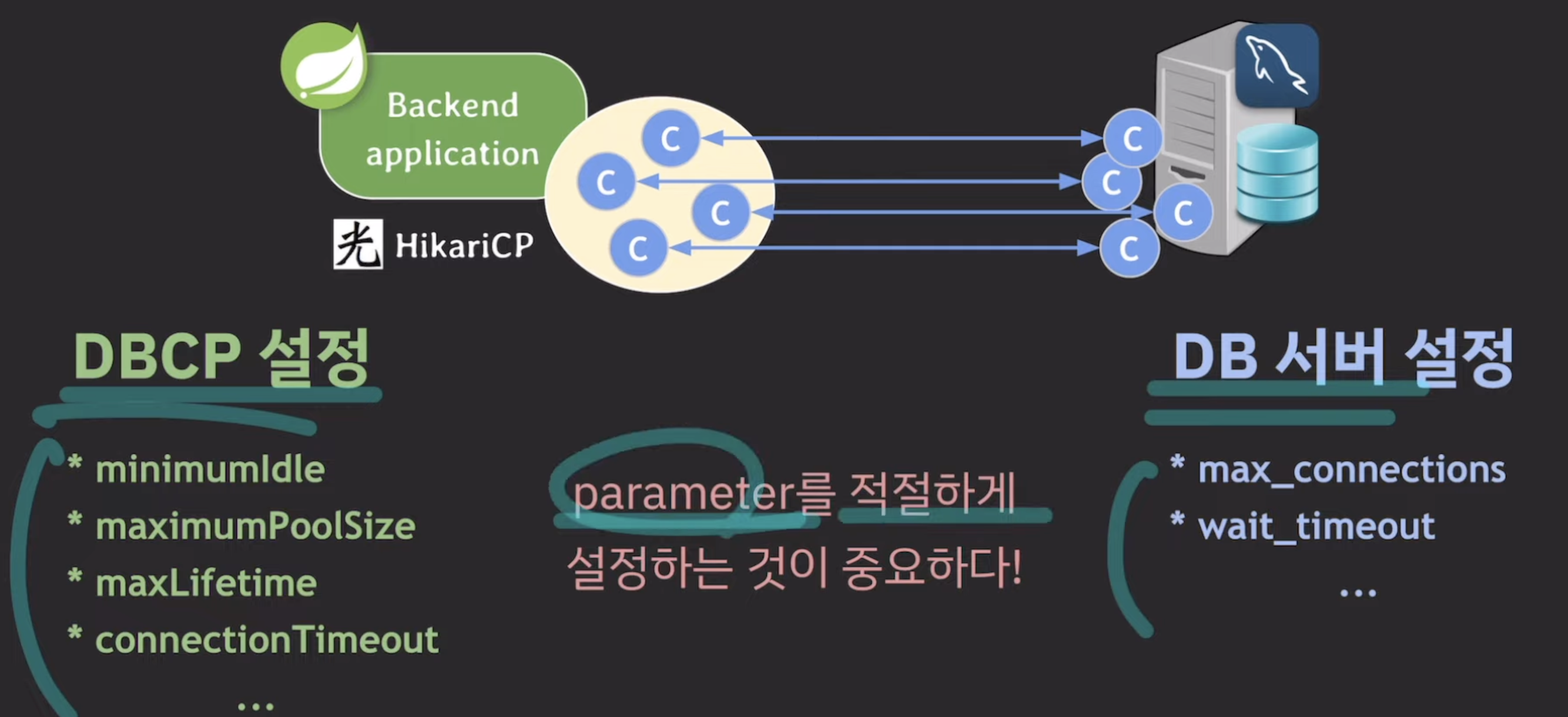
📍 DBCP 설정 방법
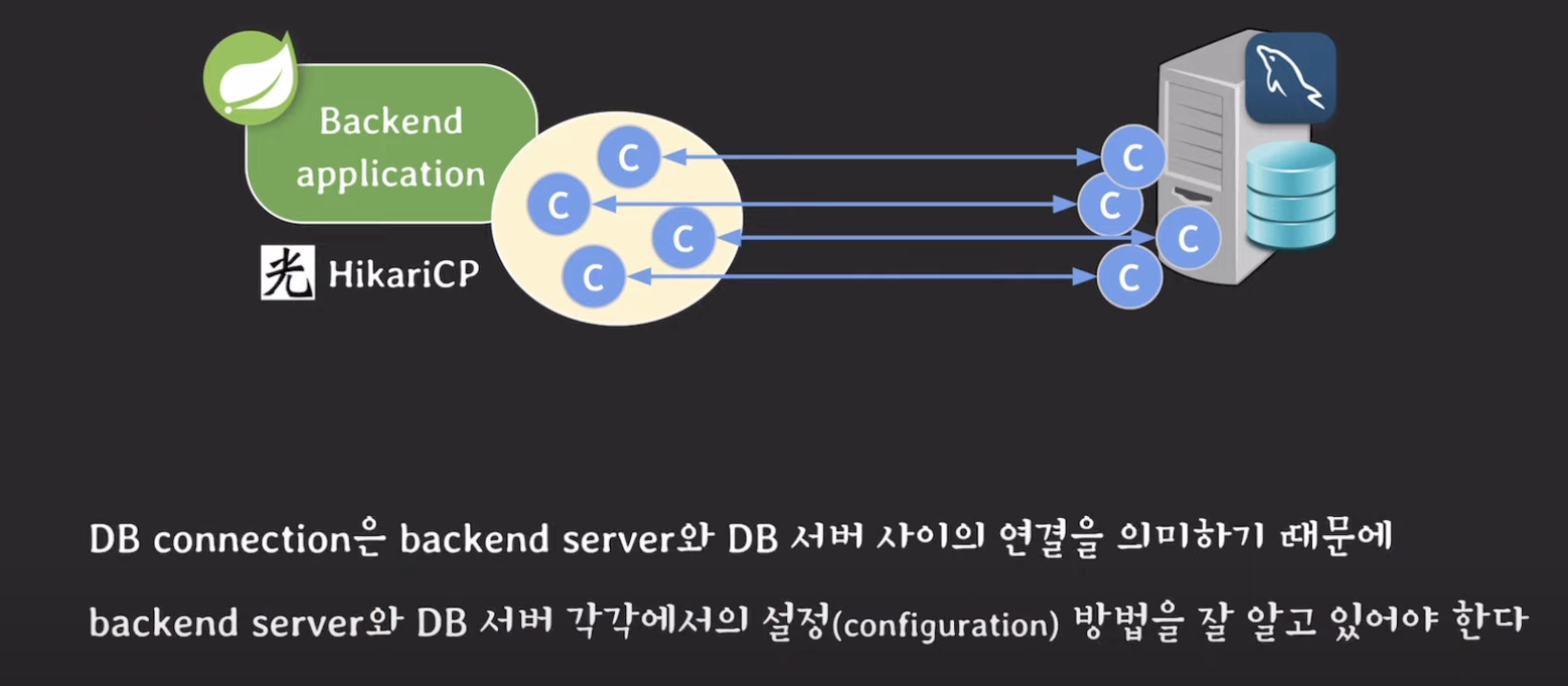
db, dbcp 종류마다 다름.
그래서 db는 mysql, dbcp는 hikariCP기준으로 설명
<DB 서버 설정 방법>
- max-connections : client와 맺을 수 있는 최대 connection 수
만약 max_c가 4고, DBCP의 최대 c수가 4라면?
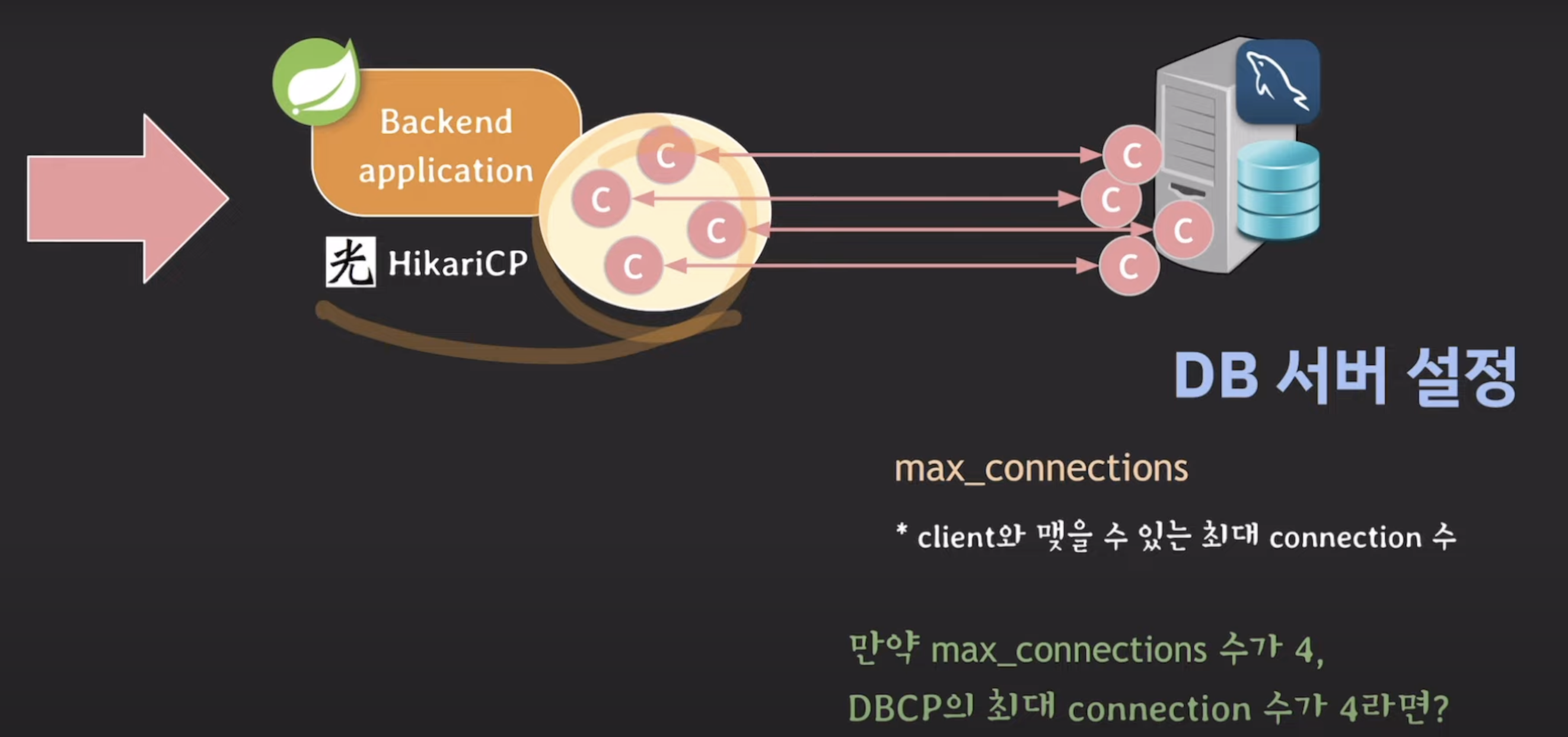
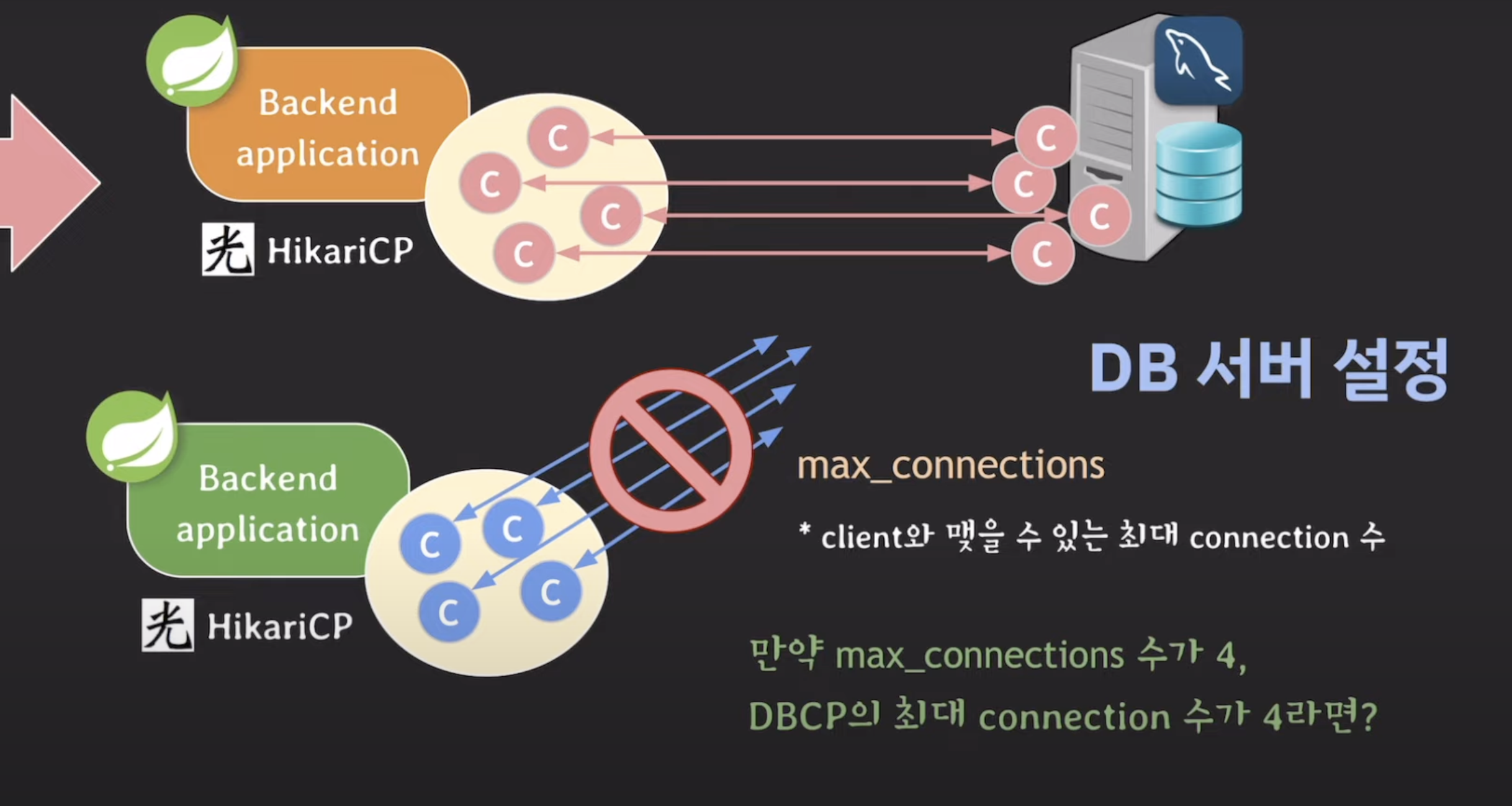
왼) 이미 max_c만큼 c맺어져있음.
서버에 트래픽이 더 많이 몰려오면? 서버 cpu, mem 사용량 점점 업
-> 서버 과부하 -> 서버 한대 더 투입하자!
오) 한대 더 투입.
서버 띄울려면 c를 미리 맺어둬야함 (풀)
-> 근데 이미 db서버의 max_c만큼의 c가 맺어진 상태라 추가 c못 맺음
=> max_connections을 잘 설정해줘야, 신규서버를 추가하거나 dbcp의 c수를 늘려도 에러가 발생하지 않고 정상적으로 작동
- wait-timeout : connection이 inactive할 때 다시 요청이 들어올 떄까지 얼마만큼 기다리다가 close할건지 결정
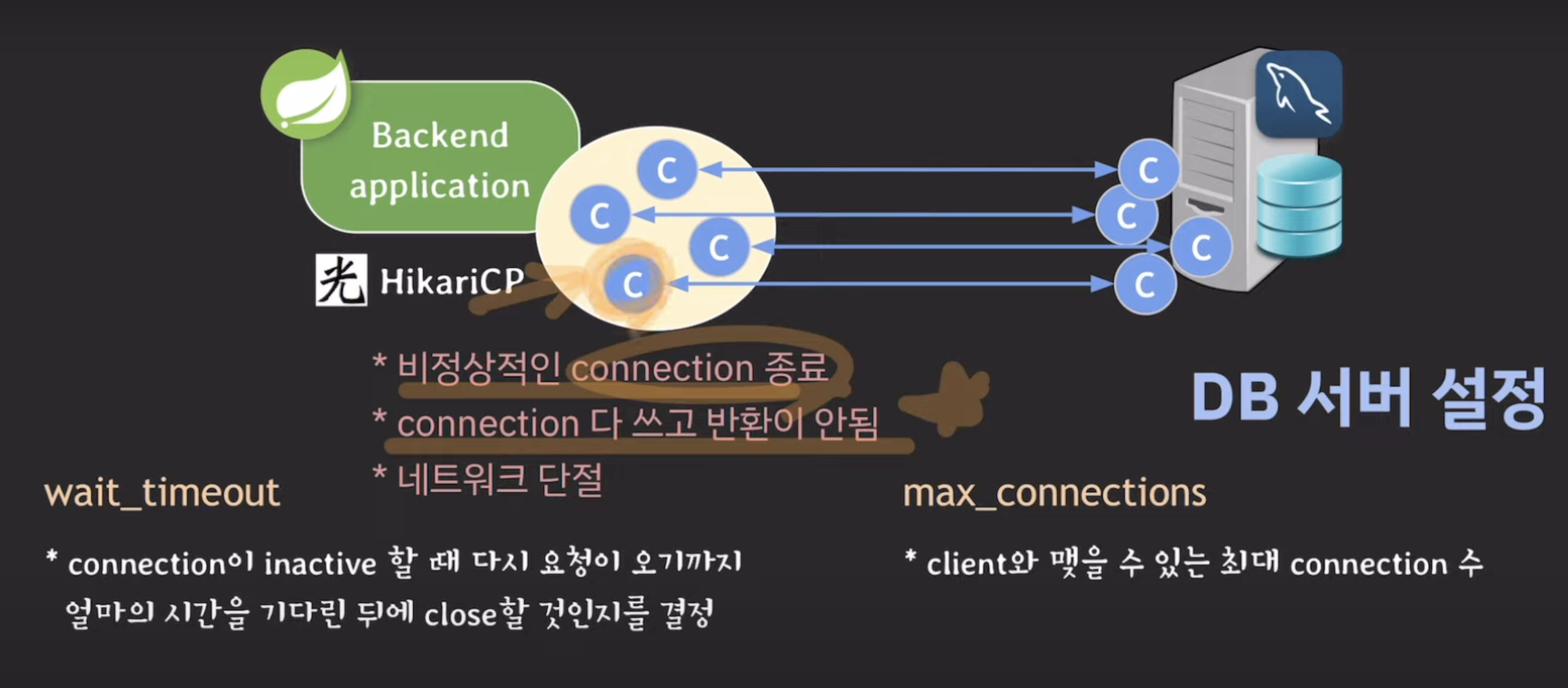
db서버 입장에서 열려있는 c. 근데 inactive(idle) 상태일때. 즉 요청이 올때까지 기다리고있는 상태.
만약 정상적인 상황이라면 서버에서 '나 이제 c끊을거야~'라고 요청줌. -> 제거
근데 비정상적인 상황(ex. 비정상적 c 종료, c 다 쓰고 반환x 등)이라면 c를 계속 들고 있는데 요청을 안보냄. 즉 누군가 점유는 하고 있지만 쓰고 있지는 않은 상태.
db서버 입장에서는 c가 비정상적이라는 걸 모르고, 하염없이 요청을 기다림 -> 이런 상태가 많아지다 보면 db서버에 안좋음
=> wait_timeout 설정으로 해결
ex. 60초로 설정 -> 60초 동안 아무 요청없으면 c 닫아버림 -> c가 차지하고 있던 리소스 반환
마지막 요청을 받고 60초까지 기다림. 기다려도 안오면 db서버에서 연결 끊어버림.
시간내에 요청이 들어오면 0으로 초기화!
<DBCP 설정 방법>
- minimumidle : pool에서 유지하는 최소한의 idel connection 수
idle : 연결은 되어있지만, 어떤 요청(작업)을 할 때까지 기다리고 있는. 즉 놀고 있는 (유휴) (inactive)
- maximum-pool size : pool이 가질 수 있는 최대 connection 수 (active + inactive)
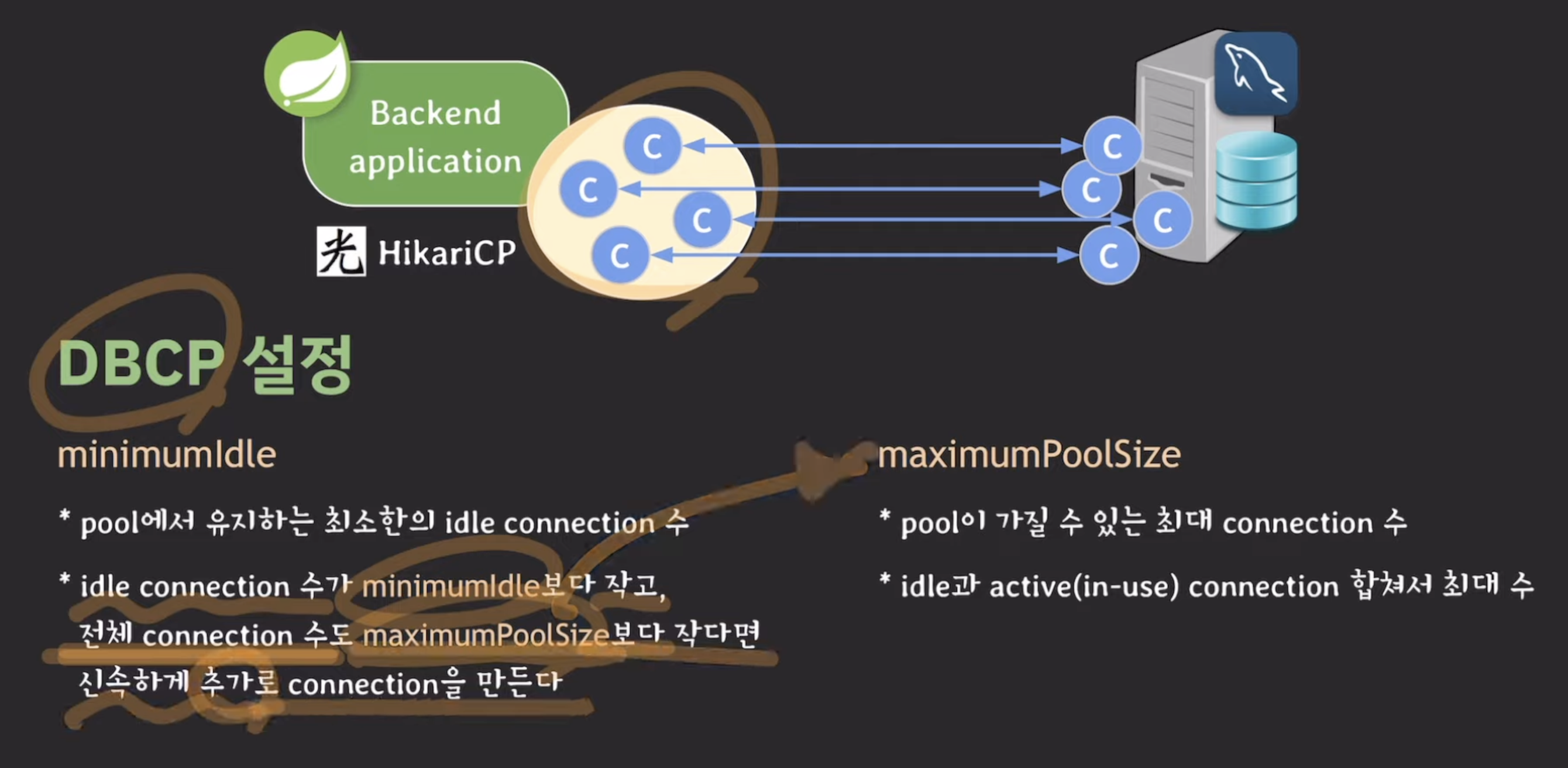
maximum pool size가 우선순위가 높다.
ex. minimumidle이 2이고, maximumpoolsize가 4라면?
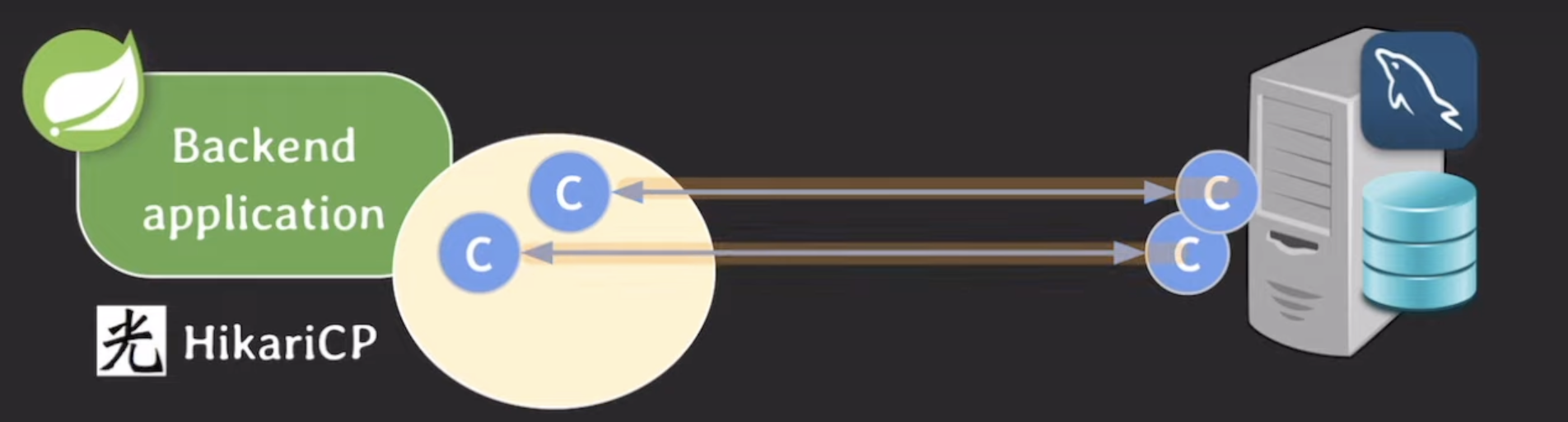
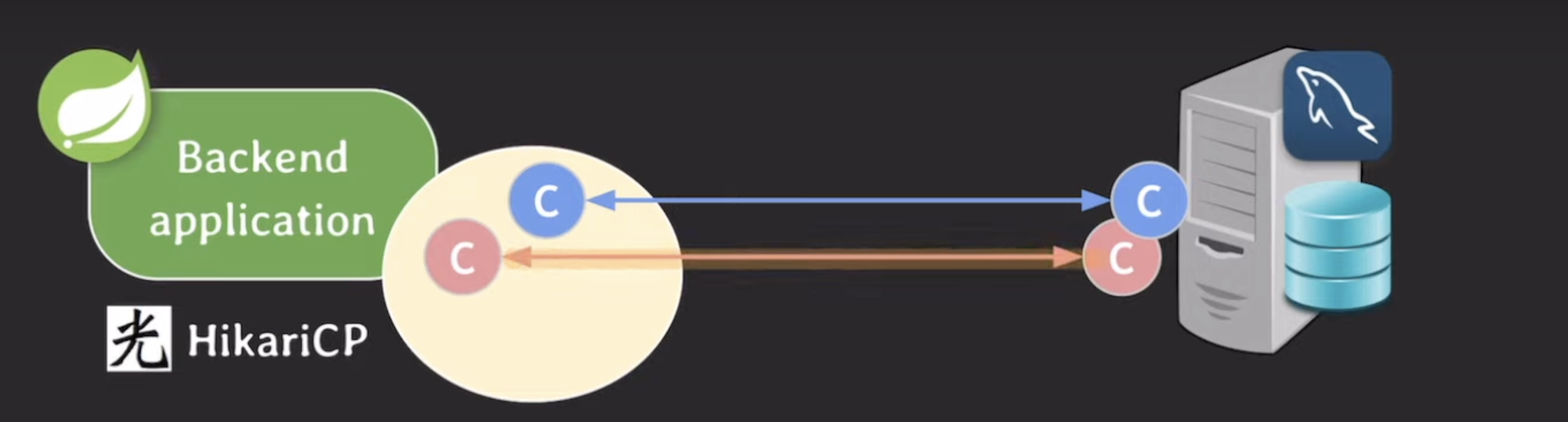
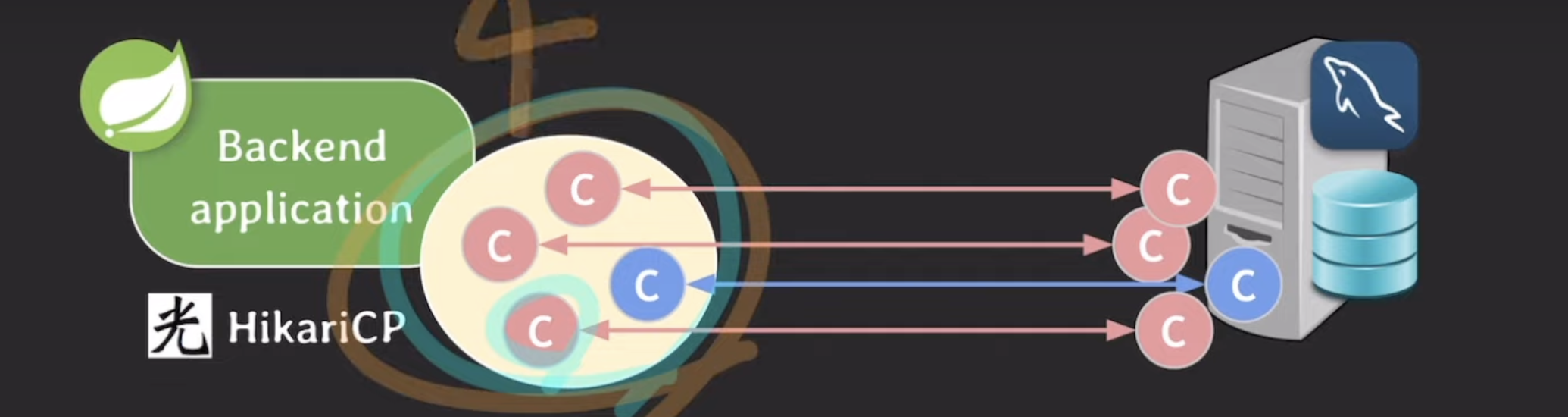
idle 2 -> 요청을 처리하느라 c 하나 사용 -> idle 1 -> 1 < minimumidle 이라 하나 더 추가. 근데 하나 더해도 <=maximum이라 가능
맨 오른 쪽 같은 경우 idle 1이지만 이미 maximum이라 추가 불가
=> maximum이 우선순위가 더 높다
더이상 트래픽이 들어오지 않으면 다시 minimumidle로 만들기 위해 2개 삭제
!!!!권장사항!!!!
minimumidle은 maximumpool과 동일(pool size고정)하게 하는것이 좋다!
(이유 : min < max이면 트래픽 몰려올 때마다 추가로 c만들어야함 -> 풀의 의미가 없다)
+) 실무에서 commons DBCP를 썼었을 때 initialSize, maxActive, minIdle, maxIdle을 모두 같은 값으로 설정해서 썼던 기억이 나네요
- maxlifetime : pool에서 connection의 최대 수명
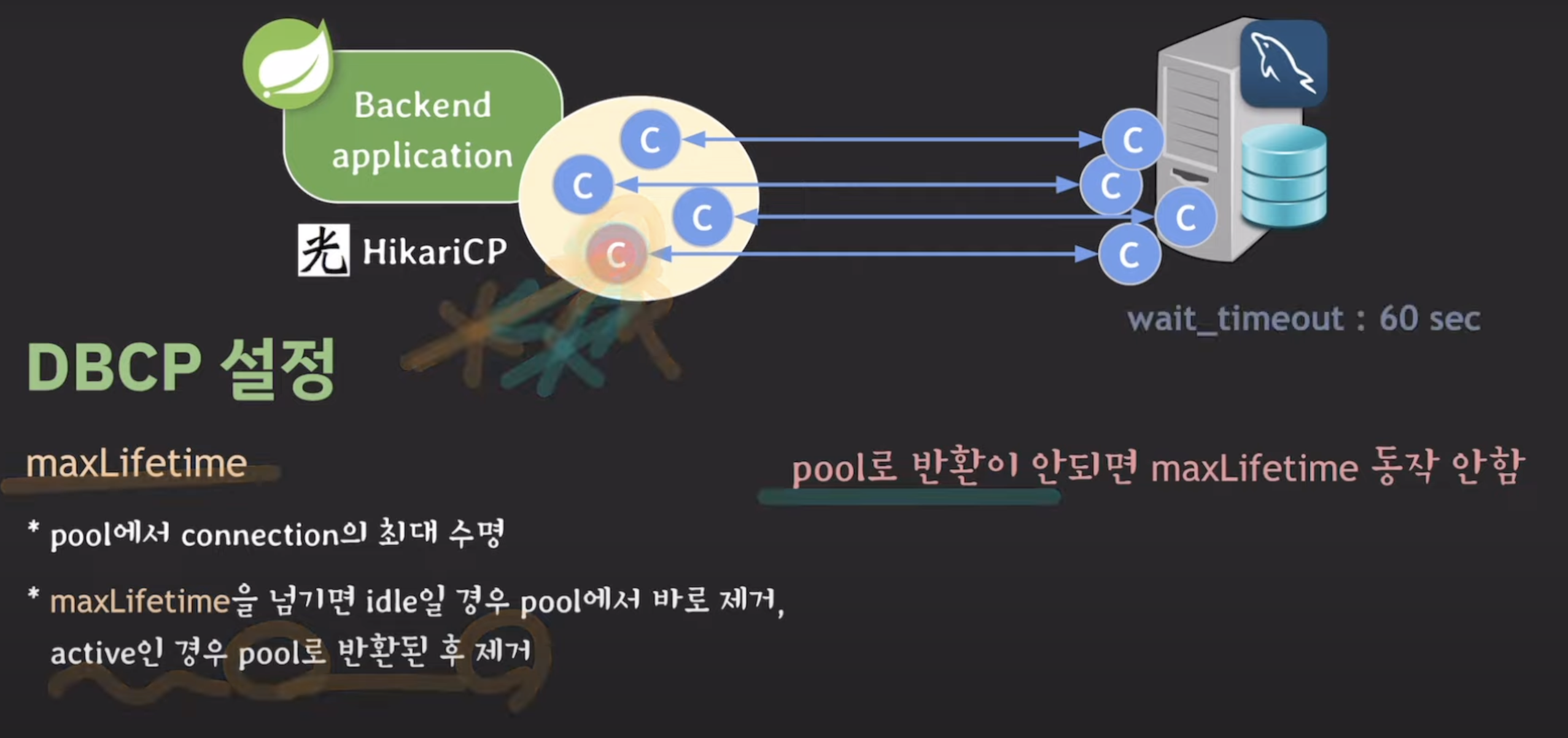
c제거해도 pool size를 4로 고정해뒀다면, 삭제하자마자 새로운 c만든다.
pool로 반환이 안되면 -> active한 상태로 인식 -> pool로 돌아오지 않아서 제거 불가
이 상황에서 db서버에서 wait_timeout을 60초로 설정해두면, 정해진 시간동안 요청 안와서 끊어버림 -> 이후에 서버에서 db로 요청보내도 이미 c끊겼기때문에 exception뱉음
=> 결론 : maxlifetime이 잘 동작하게 하려면 다 쓴 c는 pool로 반환을 시켜주는 것이 중요하다~
(에러 뜨면, 혹시 c반환이 잘 안되나? 그래서 커넥션 누수 현상이 발생하나? 확인~)
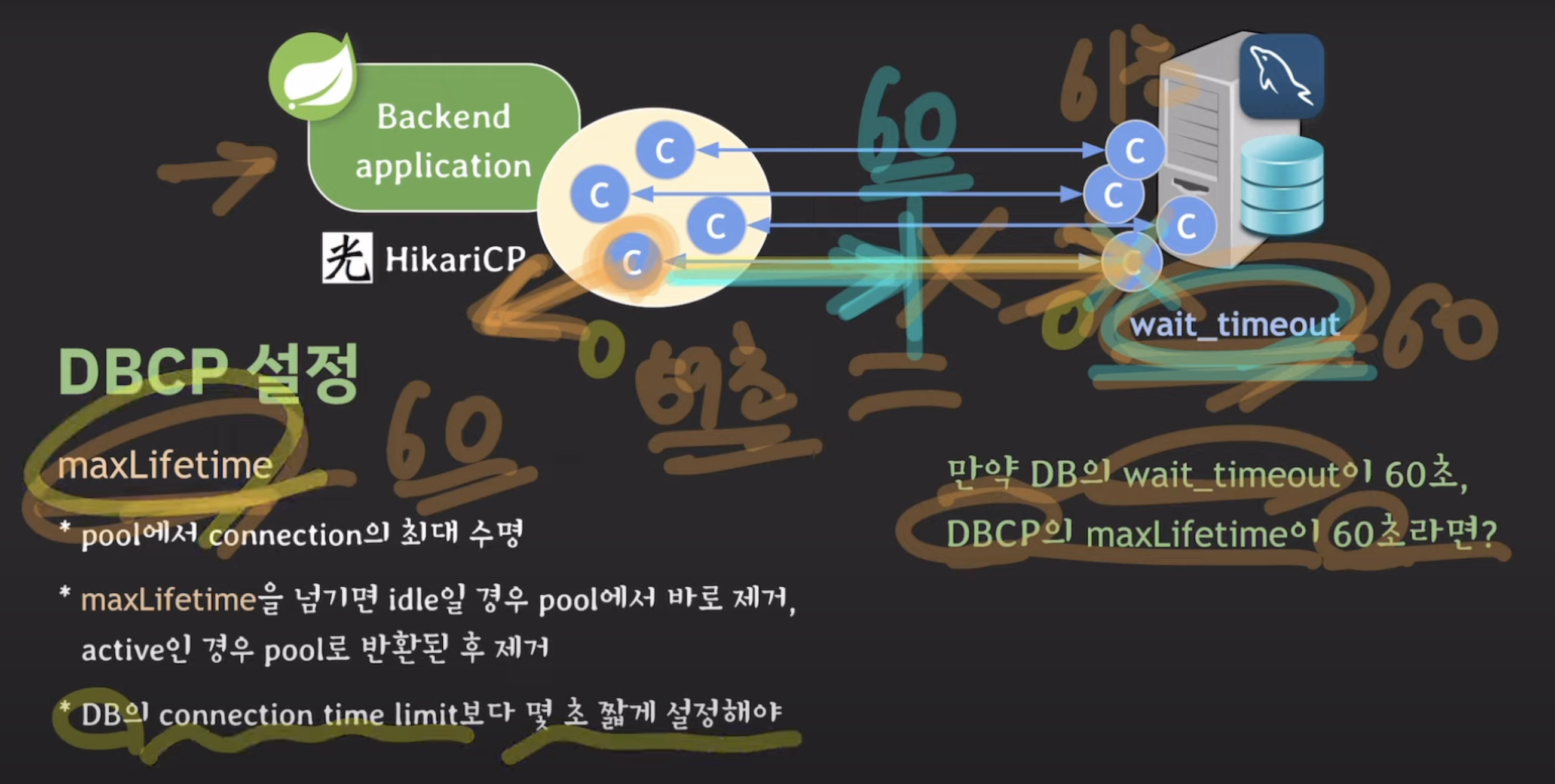
maxlifetime은 db의 connection time limit(wait_timeout)보다 몇초 짧게 설정해야한다!
- connectionTimeout : pool에서 connection을 받기 위한 대기 시간
근데 일반적인 사용자는 오래 안기다린다. 그러므로 길게 하는건 의미가 없다.
📍 적절한 connection 수를 찾기 위한 과정
신규 기능을 출시할 예정. 트래픽이 몰릴 것 같다. 지금 서버 세팅으로 다 처리할 수 있을까? (파라미터 값이 적절할까?)
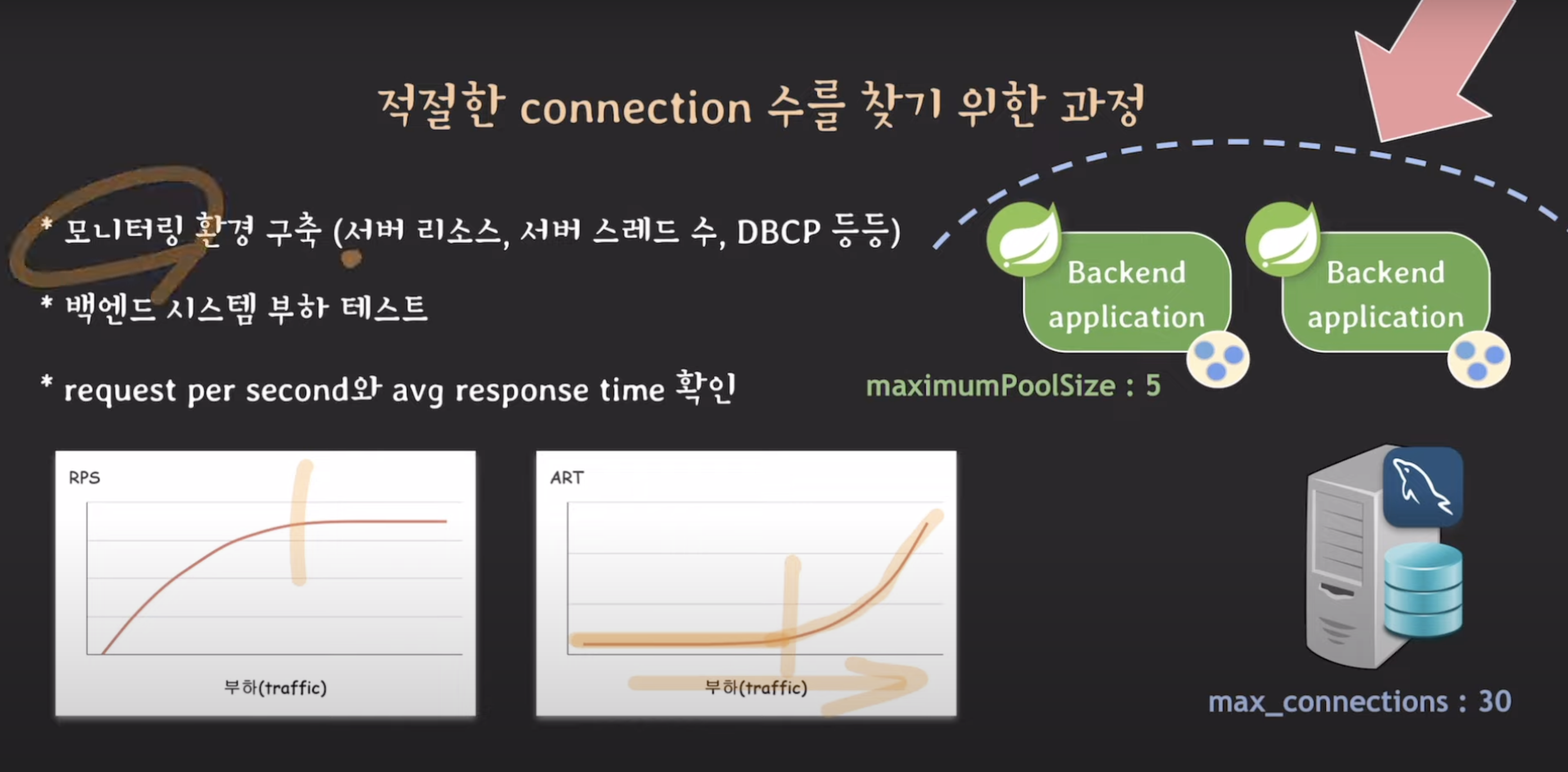
1. 모니터링 환경 구축
2. 부하 테스트 (트래픽을 점점 늘려간다)
3. 부하를 주다가 성능(rps, art등)이 일정해지는 순간을 찾음 -> 그 포인트에서 모니터링 시스템의 지표 확인
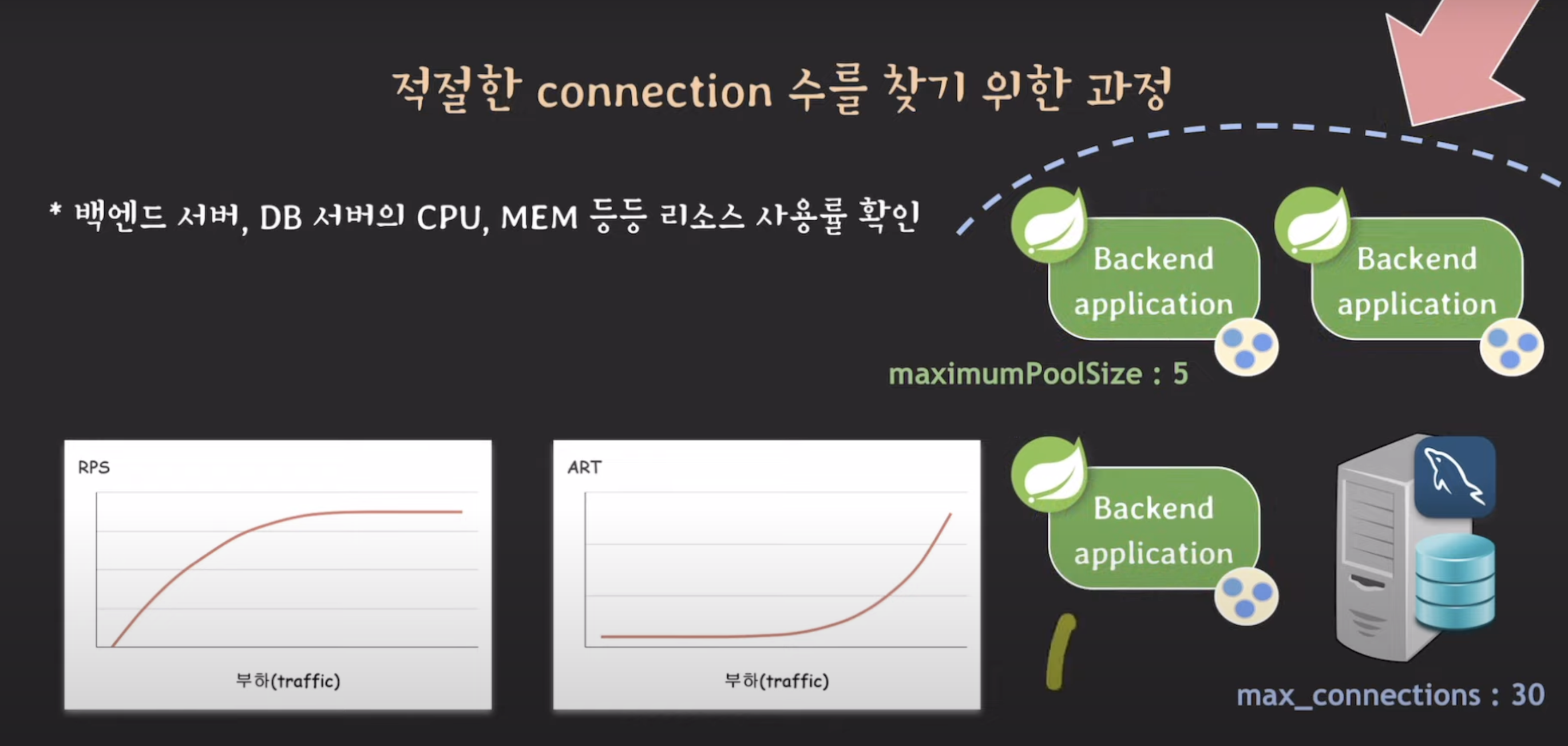
백엔드 서버의 리소스 사용률 확인
막 80%이렇게 올라가면 이 두대의 서버만으로는 트래픽을 감당할 수 없는 것
-> 백엔드 서버 추가 -> 트래픽을 분산하니까 각 서버의 리소스 사용률 적게
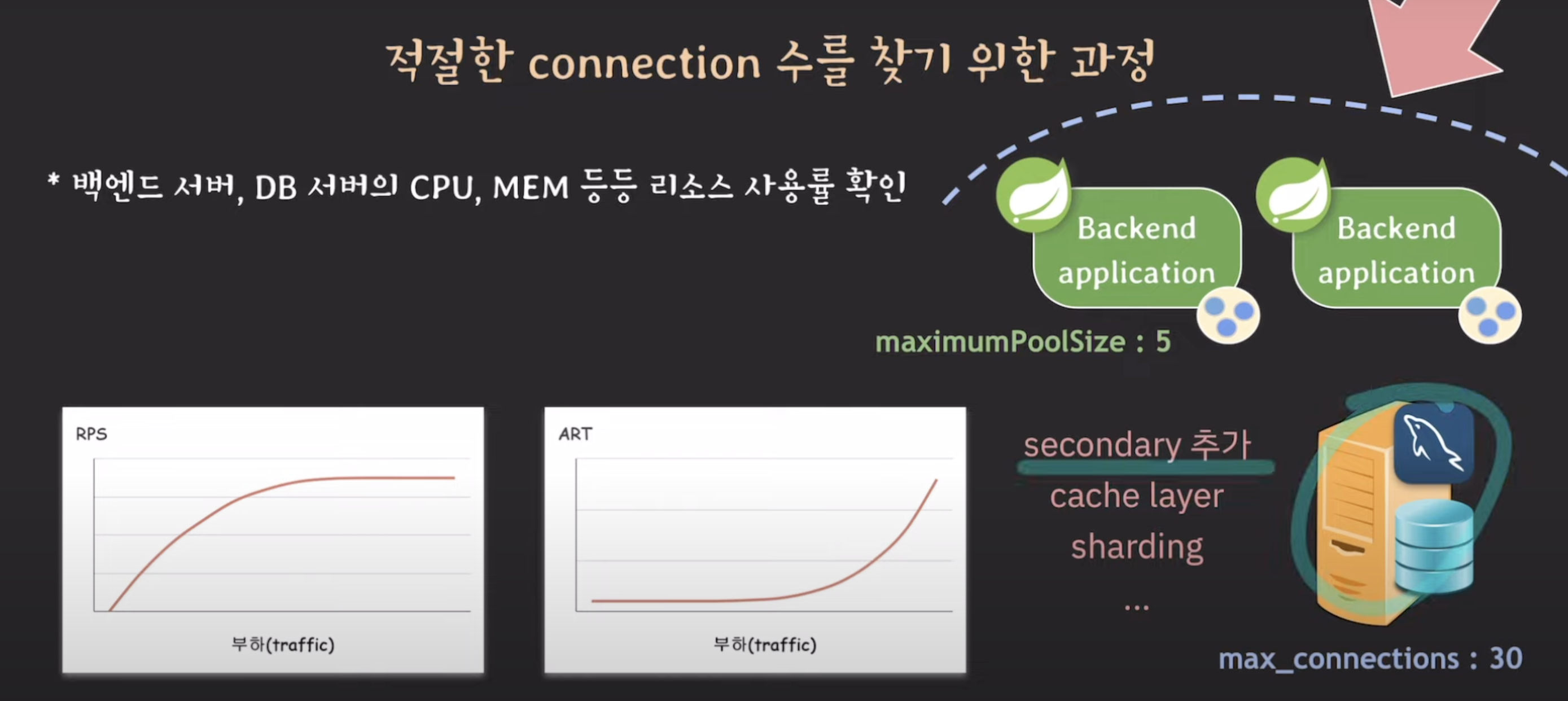
만약 백엔드 서버는 괜찮은데 DB서버의 리소스 사용률이 올라가면
-> slave를 추가하거나, 백엔드 서버와 db서버 사이에 cache를 둬서 db서버가 직접적으로 받는 부하를 줄이거나, sharding을 하거나 등등..
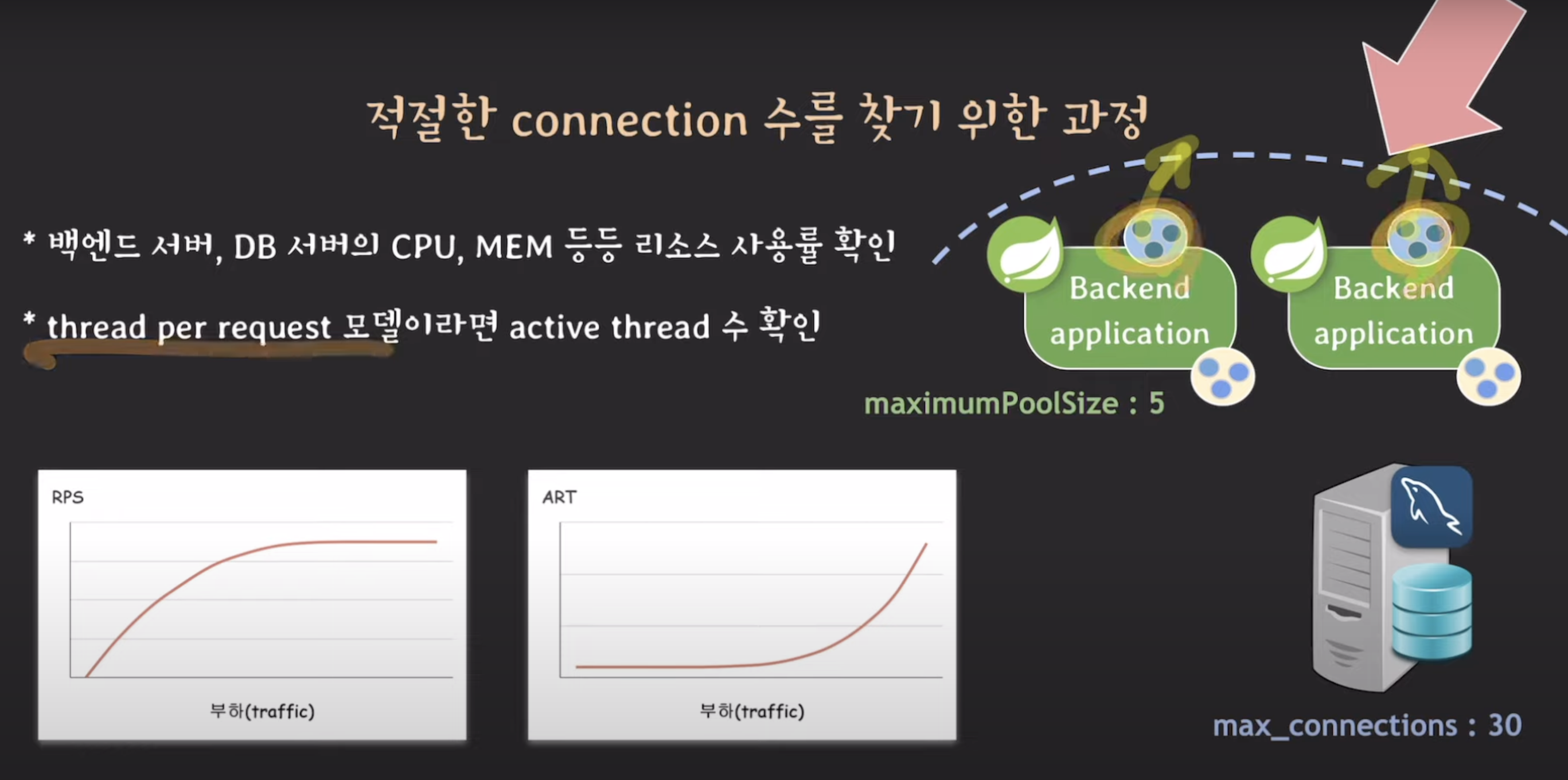
만약 백엔드 서버도 db서버도 리소스 사용률 괜찮은데도 불구하고 어떤 지점에서 그래프가 꺾인다면?
thread per request(request마다 thread를 할당해서 처리) 모델이라면
-> 요청을 받는 thread pool의 thread 수가 병목일 수 있음
-> 꺾이는 위치에서 active thread 수 확인!
thread pool의 전체 thread가 5인데, active thread도 5면..
어쩌면 thread pool의 thread 수가 너무 작아서 병목이 생기는 거일수도 -> thread 수를 늘린다
thread pool의 전체 thread가 100인데, active thread는 50면..
널널한 것 -> thread pool의 문제가 아니다
-> dbcp의 maximum pool size 확인
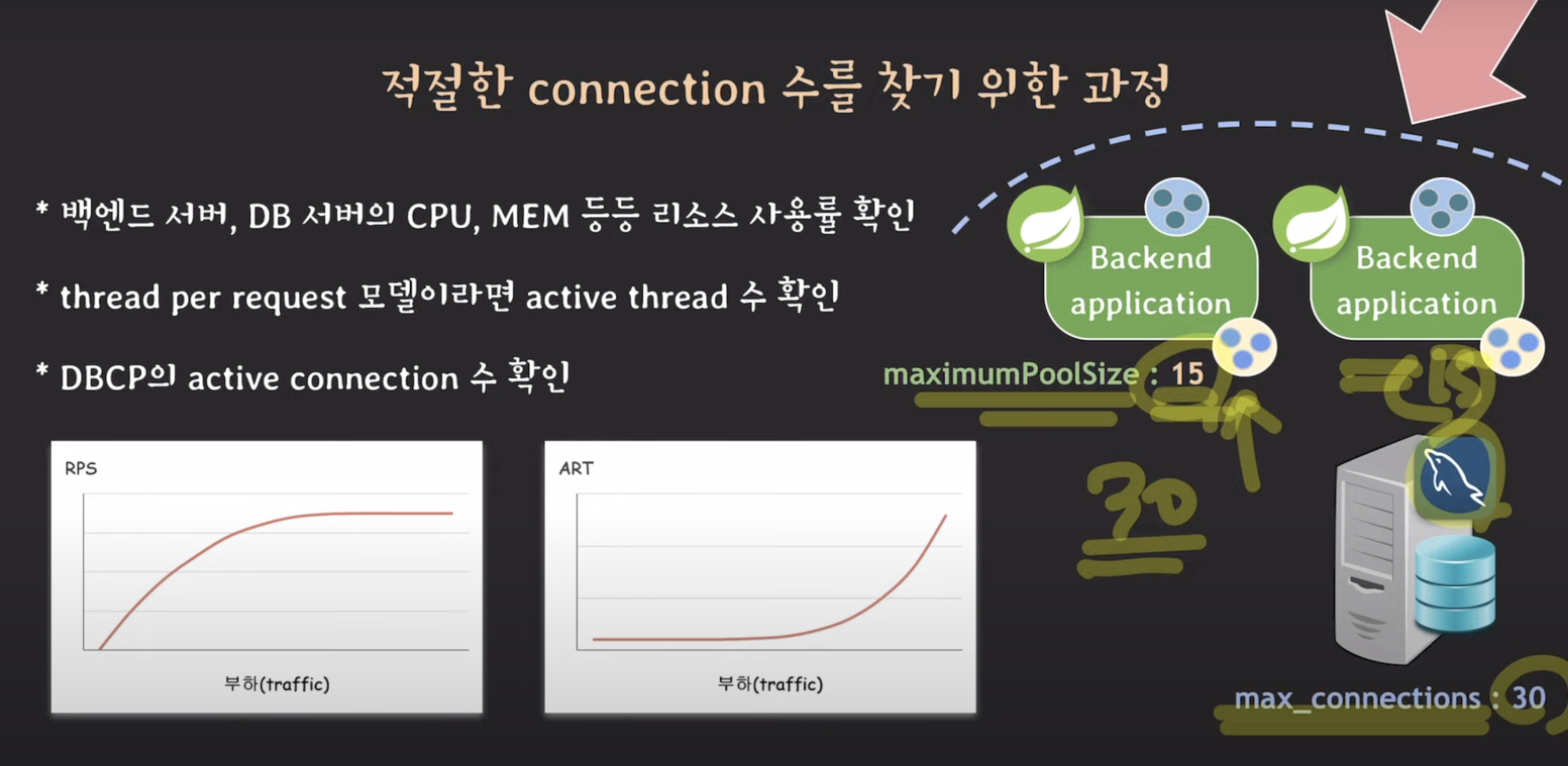
5/5면 connection 수를 늘려서 테스트해보고~
이런식으로 반복
15+15 = 30
db서버의 max_connection이 30이기 때문에 이 이상으로 올릴 수는 없다
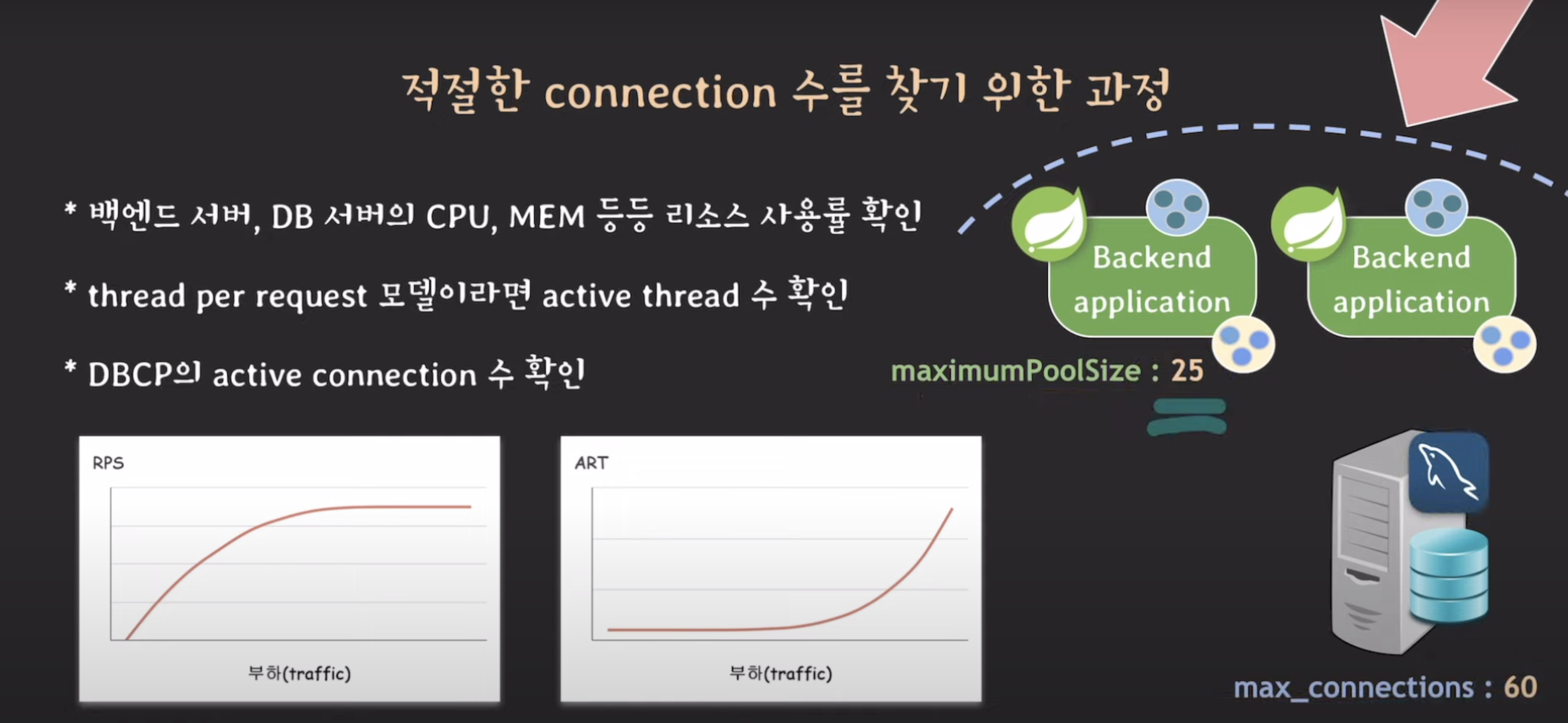
여기까지 했는데 괜찮다면 max_connection을 60으로 올려보고~
반복
어느선에서 멈춰서 db서버의 max_connection 적당히 잡기.
60이면 적절할 것 같아. 이거면 지금보다 트래픽이 5배 넘게 몰려와도 버틸 수 있어.
부하테스트는 여기까지만 하겠어!
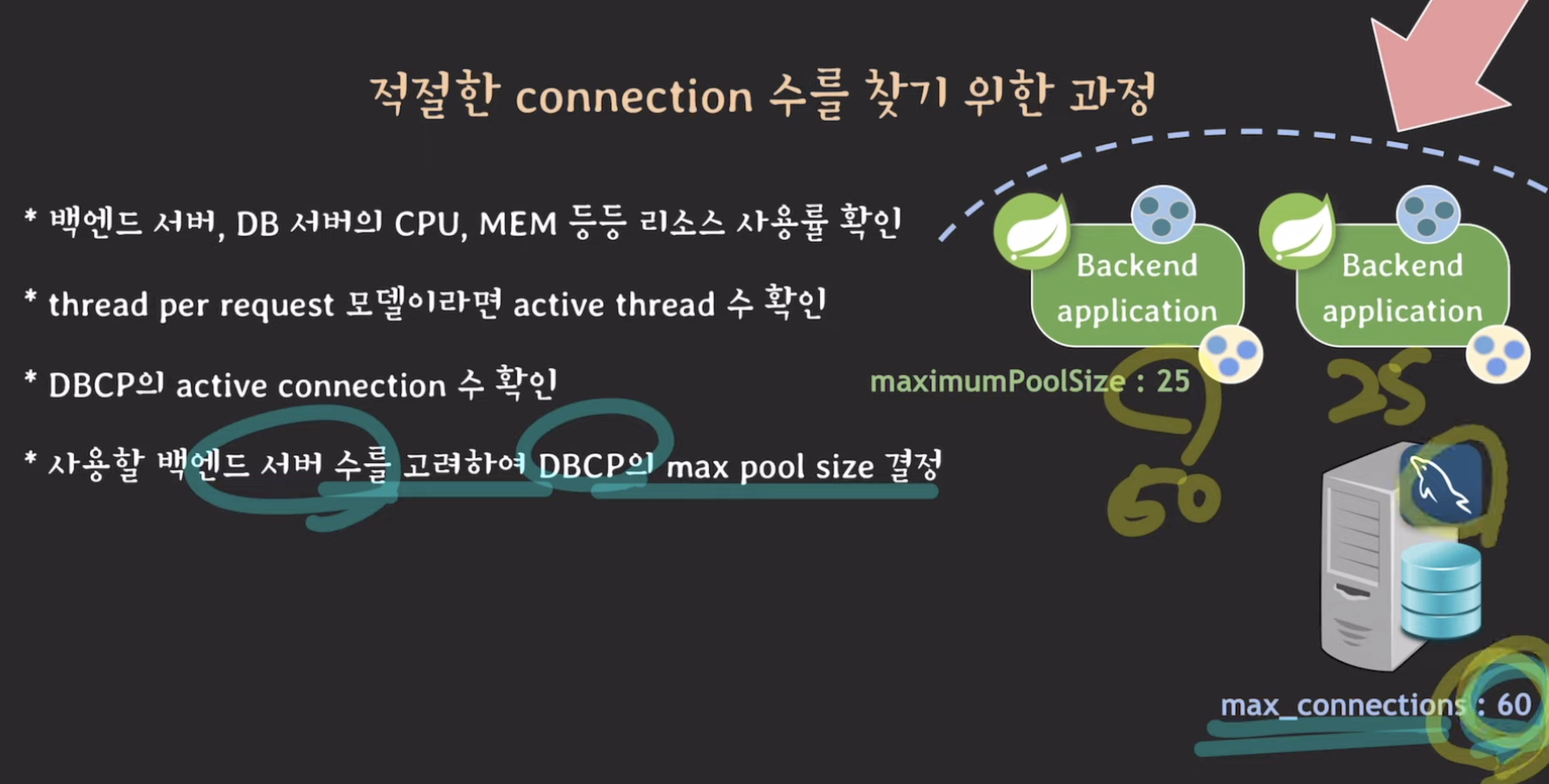
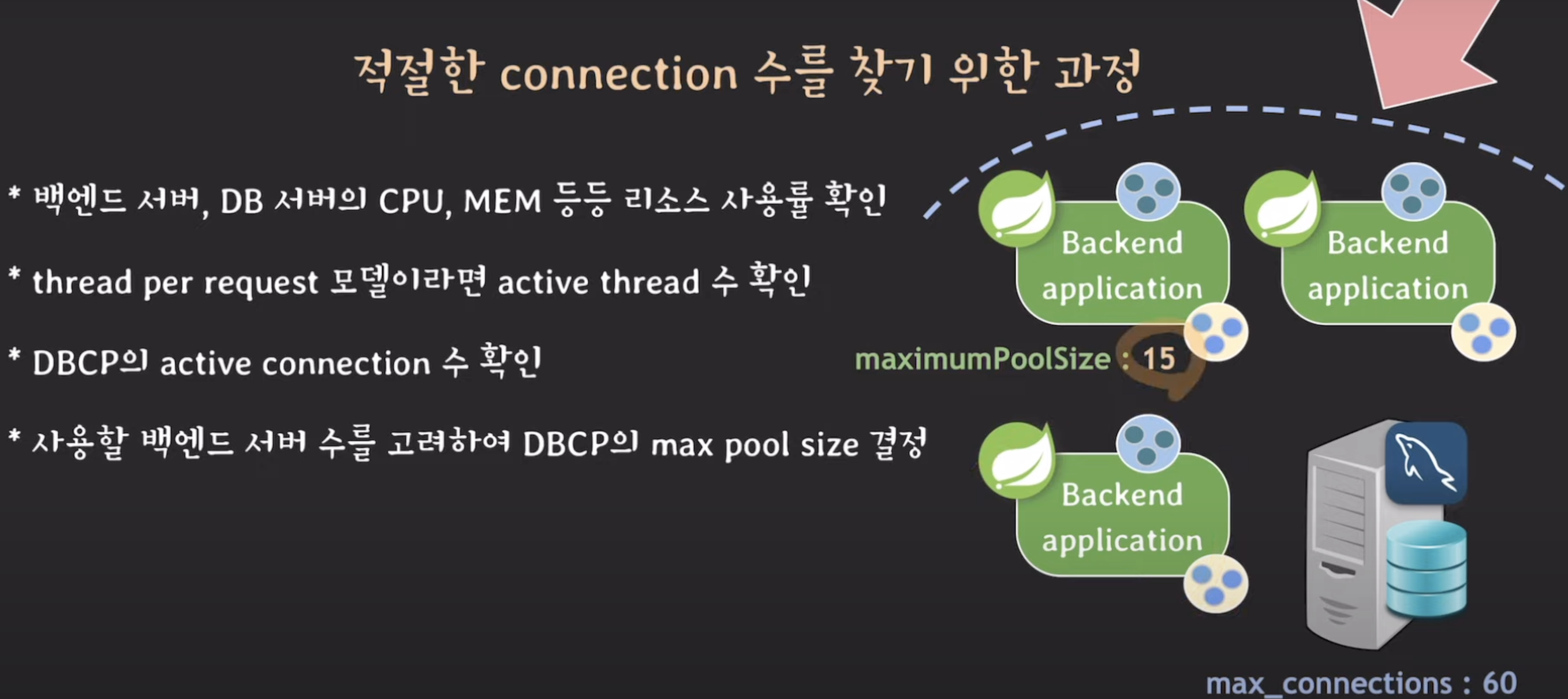
그럼 이제 정한 max_connection을 기준으로 사용할 백엔드 서버 수를 고려해 dbcp의 max pool size 결정!
서버 두대만 돌리기에는 약간 불안하다. 왜냐하면 요청이 많이 몰려오면 서버의 cpu가 60퍼까지 올라가기도 하던데
-> 서버 한대 더 추가! 그대신 Maximumpoolsize를 15로 줄이자!
=> 이런식으로 종합적으로 고려하며 적절한 connection 수를 설정할 수 있다
+) max_connections 수는 어느 정도 여유분을 두는게 좋다.
즉, max_connections보다 (백엔드 서버 수 X DBCP max size)가 작게 잡힐 수 있도록 DBCP max size를 설정해 주는 것이 좋다.
왜냐하면, 일반적인 백엔드 서버들 외에도 여러 형태의 클라이언트들이 존재할 수 있기 때문이다
(가령 테스트를 위한 서버나 개발자들이 쓰는 클라이언트 프로그램 등등)
https://d2.naver.com/helloworld/5102792
요거 나중에 읽어보자~
5. 책을 읽었다.
좋코나코 ch1
개발자 온보딩 가이드 2장, 4장반